正则表达式(Regluar Expressions)又称规则表达式,这个概念最初是由Unix中的工具软件(如sed 和 grep)普及开的。正则表达式在代码中常简写为REs,regexes或regexp(regex patterns)。它本质上是一个小巧的、高度专用的编程语言。 许多程序设计语言都支持通过正则表达式进行字符串操作。例如,在Perl中就内建了一个功能强大的正则表达式引擎。
正则表达式能做什么:
匹配验证:判断给定的字符串是否符合正则表达式所指定的过滤规则,从而可以判断某个字符串的内容是否符合特定的规则(如email地址、手机号码等);当正则表达式用于匹配验证时,通常需要在正则表达式字符串的首部和尾部加上^和$,以匹配整个待验证的字符串。
查找与替换: 判断给定字符串中是否包含满足正则表达式所指定的匹配规则的子串,如查找一段文本中的所包含的IP地址。另外,还可以对查找到的子串进行内容替换。
字符串分割与子串截取: 基于子串查找功能还可以以符合正则表达式所指定的匹配规则的字符串作为分隔符对给定的字符串进行分割。
var re = /^\d{3}$/;这种事所谓的静态定义方式,就是里面的内容不可以使用变量
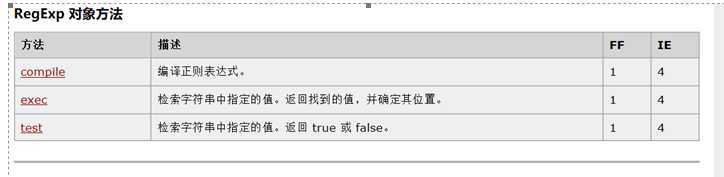
test:测试参数是否与正则表达式匹配,匹配返回true,反之false。
var re = new RegExp(“^\d{3}$”); 这种就是动态定义正则表达式

js中的几个关键的正则表达式
js中的正则表达式校验
a: RegExp(如果这里有转义字符的话,需要使用“\”)
<script type="text/javascript"> var patt1 = new RegExp("e"); var val = patt1.test("We need keep smiling"); console.log(val);//true </script>
全局替换和只替换第一个字符的写法
alert("2014+03-22++aaaa".replace(/+/,‘‘)); //单个替换
alert("2014+03-22++aaaa".replace(/+/g,‘‘));//全局替换
alert("2014+03-22++aaaa".replace(/+*/,‘‘));//全局替换,这个是错误的表达
第一行结果是201403-22++aaaa,第二行结果是201403-22aaaa,第三行,无结果
java中的正则表达式
正则表达式本身(可以借鉴js中的内容)
相关的API
java.util.regex.Pattern:
static Pattern compile(String pattern)根据一个字符串(正则表达式)创建pattern对象
Matcher matcher(String text) 获取Matcher对象
boolean static matches(String pattern,String text)判断第二个参数字符串是否与参数一正则匹配
java.util.regex.Matcher:
int groupCount() 获取组的个数
String group(int groupNumber)获取某个分组
boolean matches()完全匹配
boolean lookingAt() 从第一个字符开始匹配(匹配部分)
int start()匹配开始位置(包含)
int end()匹配结束位置(不包含)。另外可以通过字符串的substring与他们两完成截取子串截取子串
.......
java中的String里面也有一些方法可以使用正则表达式的。例如replace
String replaceAll(String regex,String replacement)
String[] split(String regex)
接下来介绍一下Java当中正则表达式的使用
邮箱的验证(如果这里碰到转义字符,需要使用“\”)
public static void main(String[] args) { // TODO Auto-generated method stub String str = "1012092703@qq.com"; // 邮箱验证规则 String regEx = "^[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\\.[a-zA-Z0-9_-]+)+$"; // 编译正则表达式 Pattern pattern = Pattern.compile(regEx); // 忽略大小写的写法 // Pattern pat = Pattern.compile(regEx, Pattern.CASE_INSENSITIVE); Matcher matcher = pattern.matcher(str); // 字符串是否与正则表达式相匹配 boolean rs = matcher.matches(); System.out.println(rs);//true }
| 元字符 | 含义 |
|---|---|
| \b | 单词之间的间隔 |
| . | 任意一个字符(除换行之外) |
| \d | 表示0-9中10个数字任意一个。 |
| ^ | 以XX字符开头。例如:^a,以a字符开头 |
| $ | 以XX字符结尾。例如:a$,以a字符结尾 |
| \s | 表示空白字符,例如空格,制表符\t,换行\n |
| \w | 表示字母(大小写都包含),数字(0-9),下划线(_) |
| + | 表示之前(或者左边)字符出现的此时>=1次 |
| ? | 表示之前字符出现<=1次,(0,1) |
| {m}{m,n}{m,} | 表示数量的意思,前面的字符出现的次数。{m,n},m-n之间次数包含。{m,},>=m次 |
| * | 数量词,表示它前面字符出现任意次(0-多次,>=0) |
| [] | 区间的意思,任意一个 |
| [^...] | 取反的意思 |
| (...) | 分组或者分支判断。 |
| ...... | ...... |
元字符的使用,就会带来一些问题,例如,想表示一个真正的(**.点号)如何操作?**
汉字如何去判断,当然(**.)是可以判断到汉字的,不过还可以判断其他字符,并不是最佳选择,汉字的判断是通过字符的unicode码值来判断,97,65(A,a)。一般而言把常用的汉字归纳一下,在一个区间,这个区间是(16进制来表示)
原文:https://www.cnblogs.com/qianshen-bolg/p/13311374.html