1.1 csv文件操作:
读取操作
pandas.read_csv(filepath, sep=‘, ‘, delimiter=None, header=‘infer‘, names=None, index_col=None, prefix=None, parse_dates=False, infer_datetime_format=False
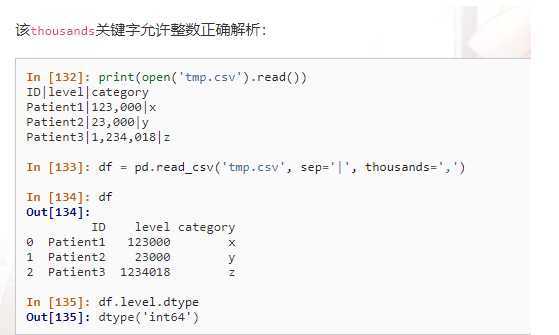
, dayfirst=False,keep_date_col=False, encoding=None,thousands=None)
filepath: 文件路径,r‘路径‘。
sep:分隔符,一般csv默认逗号为分隔符,如果想使用其他字符对csv文件进行分隔可以指定为其他的字符,此外,还可以指定正则表达式为分隔符。
delimiter:分隔符,默认为None。sep的别名。当有delimiter的时候,sep失效。
header:文件头,会自动识别header。
对于header,当第一行为字符时,则第一行数据默认为表头,此时尽量不要设置Header=None
对于Header, 当第一行与其他数据类型相同的时候,也会把第一行当做表头,此时无表头的话,应该设置Header=None,然后在设置names=[‘a‘,‘b‘,‘c‘,‘d‘],否则列名就是1,2,3,4
names:列名,当设置了names之后,header无论设不设置,都是None,以names为列名。
index_col:索引名,会自动识别index_col。
对于index_col,若数据类型相同,则表示无Index,输出默认的1,2,3,4,5
,若第一列数据为字符串,其他列为数值,则第一列为index
, 若设置index_col=False,表示无index,默认index=1,2,3,4,5,。以后在dataframe中可以改变。
, 若设置index_col=[0,1],则变成了高级索引,1,2列都为索引。
prefix:前缀。当header=None时给列标签添加前缀。如:prefix=‘X‘,则列标签为[‘X1‘, ‘X2‘, ‘X3‘......]。
parse_dates:将某列转为datatime格式。
如果写成了parse_dates=[‘time‘,‘date‘] , pd.read_csv() 会分别对‘time‘ ,‘date‘ 列 进行字符串转为日期,此外还会造成一个小小的麻烦。由于本例中的Time的格式为‘ HH:MM:SS ‘ ,parse_date默认调用dateutil.parser.parse解析为datetime格式,因此在解析这一列的时候,会在前面自作主张的添加上当前的日期。
如果写成了parse_dates=[[‘time‘,‘date‘] ] , 即将[[‘time‘,‘date‘]]两列的字符串先合并后解析方可,合并后的新列会以下划线‘_‘连接原列名命名,本例中解析后的命名为‘time_date‘,解析得到的日期格式会作为dataframe的第一列。在index_col指定表格的第几列作为index的时候就需要小心了。如本例中,指定参数index_col=0,则此时会以新生成的‘time_Date‘列作为index,因此保险的指定inde的方法是index_col=‘indexcol‘.
infer_datetime_format:True,可显著减少日期解析命令的时间。但是要注意infer_datetime_format敏感dayfirst,默认月在前面。使用dayfirst=True,他将猜测01/12/2020 是12月1日。默认dayfirst=False,则猜测是1月12日。

keep_date_col:是否保留原有时间列,True保留,False不保留
encoding:字符串编码。
thousands:数值型千分位消除。
保存文件
pandas.to_csv(filepath, sep=‘, ‘, columns=[],header=True,index=True,date_format="%Y-%M-%D",encoding=‘utf-8‘)
filepath:文件路径。r‘xxxx‘
sep:分隔符。默认为‘,‘,在excel里面打开,excel会自动识别‘,‘,然后将数据放入对于单元格。
columns:保存的列。
header:保存列名,默认为True,这是我们希望的。
index:保存索引名,默认为True,这个常常我们不希望。
date_format: 日期保存格式。
encoding:编码格式。
---------------------------------------------------------------------------------------
2.1 excel文件。 常常先转为CSV,然后在EXCEL里面转为EXCEL
pd.read_excel(filepath, sheet_name=0, header=0, names=None, index_col=None, parse_dates=False, thousands=None)
原文:https://www.cnblogs.com/jarvan-4/p/13321405.html