加载购买商品表的数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from pandas import Series,DataFrame
%matplotlib inline
order_df = pd.read_csv(‘./(sample)sam_tianchi_mum_baby_trade_history.csv‘)
order_df.head()
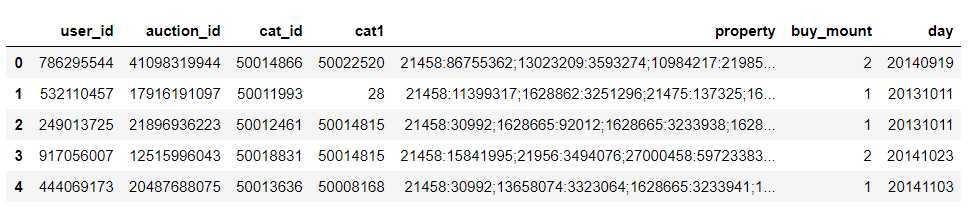
#考虑到属性字段,都是一些编号,没办法具体分析,因此去除该字段
order_df.drop(labels=‘property‘,axis=1,inplace=True)
#查看一下信息 看下有没有空值
order_df.info()
# 查看数据的时间范围 显示出数据集的最早购买时间和最后购买时间
order_df[‘day‘].min(),order_df[‘day‘].max()
(Timestamp(‘2012-07-02 00:00:00‘), Timestamp(‘2015-02-05 00:00:00‘))
#查看buy_mount是否存有异常值
(order_df[‘buy_mount‘] <= 0).sum()
0
#查看数据集用户购买商品的情况需要获知,大部分用户是多次购买商品还是只是购买了一次商品 用户ID去重后的购买记录和去重前的购买记录 作比较 差值大即多次购买多
order_df[‘user_id‘].nunique(),order_df.shape[0]
(29944, 29971)
加载婴儿表的数据
baby_df = pd.read_csv(‘./(sample)sam_tianchi_mum_baby.csv‘)
baby_df.head()
# 把birthday转换成时间序列
baby_df[‘birthday‘] = pd.to_datetime(baby_df[‘birthday‘],format=‘%Y%m%d‘)
# 查看gender列是否存在异常数据 看下gender里的值有哪些 发现2这个异常值
baby_df[‘gender‘].value_counts()
0 489 1 438 2 26 Name: gender, dtype: int64
#清除gender列中的异常数据 取出不含2的gender 赋值给gender
baby_df = baby_df.loc[~(baby_df[‘gender‘] == 2)]
#查看婴儿表中的男女比例
boby_df[‘gender‘].value_counts()
0 489 1 438 Name: gender, dtype: int64
#汇总婴儿表和购买商品表的数据 how 用outer 保持数据的完整性
order_baby_df = pd.merge(left=order_df,right=baby_df,on=‘user_id‘,how=‘outer‘)
order_boby_df.head()
#查看新老用户的数量 思路:新用户:用户只消费了一次 用户消费多次 找出用户消费时间的最大值和最小值,对比两个值,如果两个值一样,说明用户只消费了一次,否则消费了多次
#agg():在基于df进行分组后可以进行多个不同的聚合操作
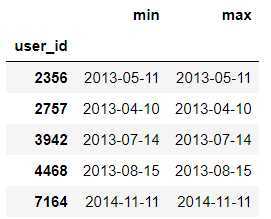
user_order_dt = order_baby_df.groupby(by=‘user_id‘)[‘day‘].agg([‘min‘,‘max‘])
user_order_dt.head()
#返回True表示新用户,False老用户
user_order_dt[‘min‘] == user_order_dt[‘max‘]
#统计新老用户的人数
(user_order_dt[‘min‘] == user_order_dt[‘max‘]).value_counts()
True 29920 False 24 dtype: int64
# 给数据添加新的一列为购买的月份
order_baby_df[‘month‘] = order_baby_df[‘day‘].astype(‘datetime64[M]‘)
order_baby_df.head()
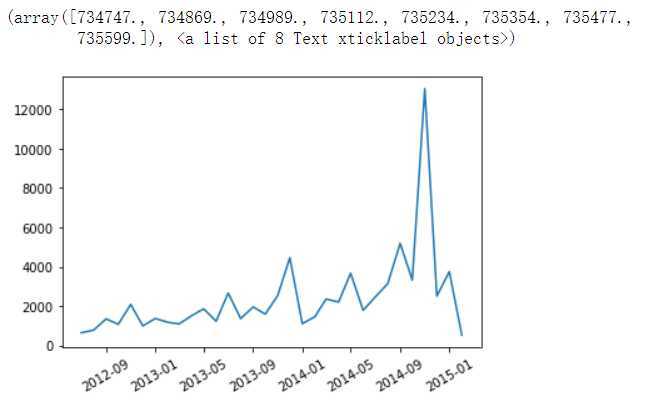
#查看每个月商品的销量情况,绘制线形图进行展示 根据month分组 在统计各个月的销量
month_amount_s = order_baby_df.groupby(by=‘month‘)[‘buy_mount‘].sum()
month_amount_s
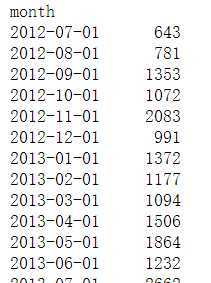
#制图 .index .values 是横纵坐标 xticks是横坐标 rotation=30 是坐标标签倾斜30度
plt.plot(month_amount_s.index,month_amount_s.values)
plt.xticks(rotation=30)
#查看12,13,14年每个月的销量情况,绘制线性图进行展示
#1.给源数据添加一列为购买的年份
order_baby_df[‘year‘] = order_baby_df[‘day‘].astype(‘datetime64[Y]‘)
order_baby_df.head()
#2.给源数据添加一列为购买的年份的第几个月
order_baby_df[‘month_num‘] = order_baby_df[‘day‘].dt.month
order_baby_df.head()

#3.查看12,13,14年每个月的销量情况
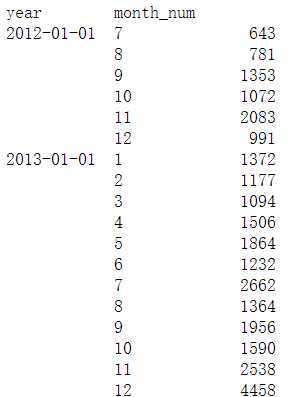
year_month_amount_s = order_baby_df.groupby(by=[‘year‘,‘month_num‘])[‘buy_mount‘].sum()
year_month_amount_s
amount_12 = year_month_amount_s[‘2012-01-01‘]
amount_13 = year_month_amount_s[‘2013-01-01‘]
amount_14 = year_month_amount_s[‘2014-01-01‘]
plt.plot(amount_12,label=‘2012‘)
plt.plot(amount_13,label=‘2013‘)
plt.plot(amount_14,label=‘2014‘)
plt.legend()
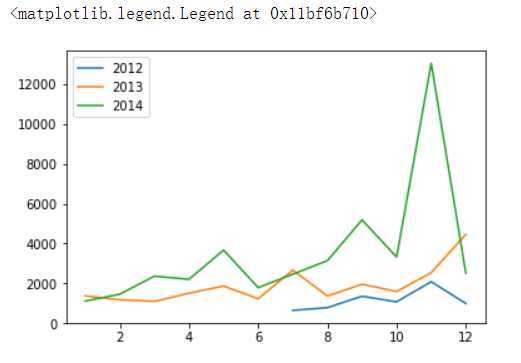
#通过走势分析发现,在每年的5月,9月,11月都有不同程度的高峰凸起,整体呈现上涨趋势,接下来分析,为什么销量上涨?
#查看每年的5,9,11这三个月每天的销量情况
#查看12,13年11月份每天的销量情况,同理查看5,9月每天的销量情况
#原始数据添加一列为销售时间的天数
order_baby_df[‘day_num‘] = order_baby_df[‘day‘].dt.day
order_baby_df.head()

#1.12年和13年11月份的数据单独取出
df_12_11 = order_baby_df.query(‘year == "2012-01-01" & month_num == 11‘)
df_13_11 = order_baby_df.query(‘year == "2013-01-01" & month_num == 11‘)
s_12_11_day_amount = df_12_11.groupby(by=‘day_num‘)[‘buy_mount‘].sum()
s_13_11_day_amount = df_13_11.groupby(by=‘day_num‘)[‘buy_mount‘].sum()
plt.plot(s_12_11_day_amount,label=‘12-11‘)
plt.plot(s_13_11_day_amount,label=‘13-11‘)
plt.legend()
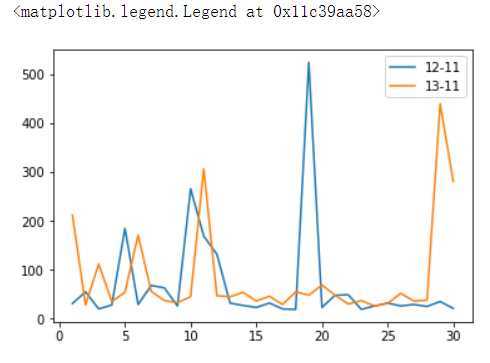
#结论 :2012年在11月10日和11月19日出现高峰,2013年在11月11日和11月29日出现高峰很明显是双十一促销带来的影响
#分析一级分类商品的销量情况,使用柱状图显示
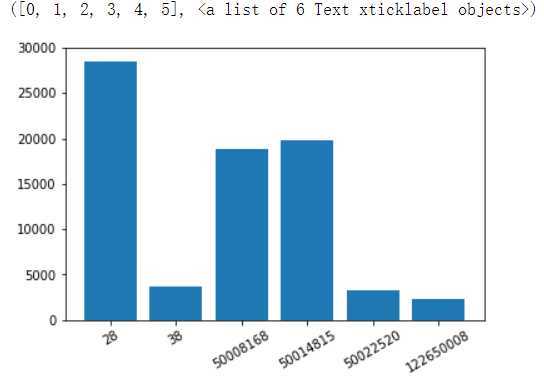
cat1_amount_s = order_baby_df.groupby(by=‘cat1‘)[‘buy_mount‘].sum()
cat1_amount_s
cat1 28 28545 38 3666 50008168 18792 50014815 19763 50022520 3245 122650008 2239 Name: buy_mount, dtype: int64
plt.bar(cat1_amount_s.index.astype(‘str‘),cat1_amount_s.values)
plt.xticks(rotation=30)
#分析一级分类商品的购买用户人数,使用柱状图显示 # 这里 要用nunique 对user_id 去重 因为 一个用户多次购买 也只能算一个用户
cat_1_user_count_s = order_boby_df.groupby(by=‘cat1‘)[‘user_id‘].nunique()
cat_1_user_count_s
cat1 28 6958 38 1201 50008168 12484 50014815 4833 50022520 2367 122650008 2110 Name: user_id, dtype: int64
plt.bar(cat_1_user_count_s.index.astype(‘str‘),cat_1_user_count_s.values)
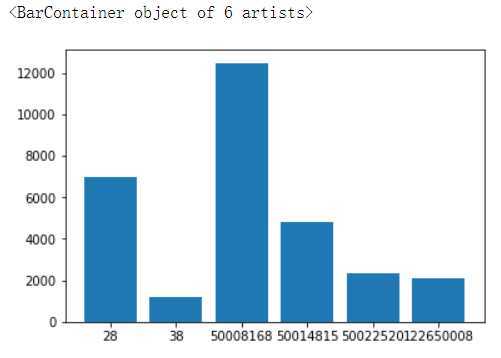
图中可以看出 68结尾的商品,购买用户人数是最大的,但是总销量低于28产品,按照我们对于热销产品的定义,50008168为热销产品。
热销产品为购买人数最多的产品而不是销量最高的产品,因为可能会有少量用户一次性购买大量的某种商品
原文:https://www.cnblogs.com/linranran/p/13325462.html