测试环境说明 :
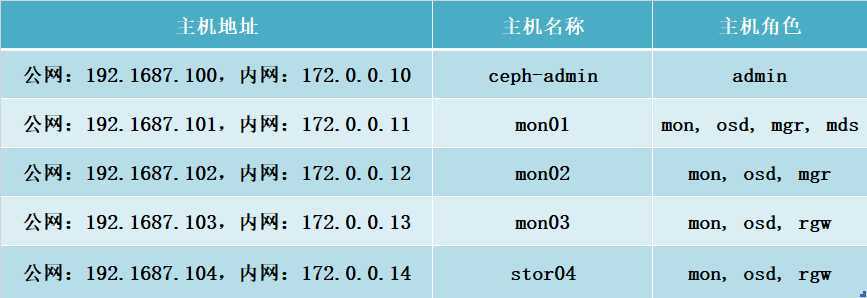
测试使用的Ceph存储集群可由一个MON主机及两个以上的OSD机组成,这些主机可以是物理服务器,也可以运行于 vmware、virtualbox或kvm等虚拟化平台上的虚拟机,甚至是公有云上的VPS主机。 本测试环境将由stor01、stor02、stor03和ceph-admin四个独立的主机组成,其中stor01、stor02和stor03是为 Ceph存储集群节点,它们分别作为MON节点和OSD节点,各自拥有专用于存储数据的磁盘设备/dev/sdb和/dev/sdc,操作系统环境均为CentOS 7.5 1804。而ceph-admin主机是为管理节点,用于部署ceph-deploy。
注意:此实验,我在每台主机上分别添加了两个50G的磁盘,也分别在每台主机上创建了一个内网和外网IP地址,详细如下表。
此外,各主机需要预设的系统环境如下:
出于简化配置步骤的目的,本测试环境使用hosts文件进行各节点名称解析,文件内容如下所示:
[root@mon01 ~]# hostnamectl set-hostname mon01 # 修改三个ceph集群的主机名称 [root@mon02 ~]# hostnamectl set-hostname mon02 [root@mon03 ~]# hostnamectl set-hostname mon03 [root@openstack ~]# hostnamectl set-hostname stor04 # 第四台主机名 [root@mon01 ~]# vim /etc/hosts # 在三台集群主机上都添加一下域名解析和主机名称解析到内网IP地址上,然后将域名解析给管理节点和每台集群节点都复制一份 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 172.0.0.11 mon01.linux.com mon01 172.0.0.12 mon02.linux.com mon02 172.0.0.13 mon03.linux.com mon03 172.0.0.14 stor04.linux.com stor04 # 第四台主机名为stor04,只需要解析此一台即可
在CentOS7上,iptables或?rewalld服务通常只会安装并启动一种,在不确认具体启动状态的前提下,这里通过同时 关闭并禁用二者即可简单达到设定目标。
~]# systemctl stop firewalld.service ~]# systemctl stop iptables.service ~]# systemctl disable firewalld.service ~]# systemctl disable iptables.service
若当前启用了SELinux,则需要编辑/etc/syscon?g/selinux文件,禁用SELinux,并临时设置其当前状态为 permissive
~]# sed -i ‘s@^\(SELINUX=\).*@\1disabled@‘ /etc/sysconfig/selinux ~]# setenforce 0
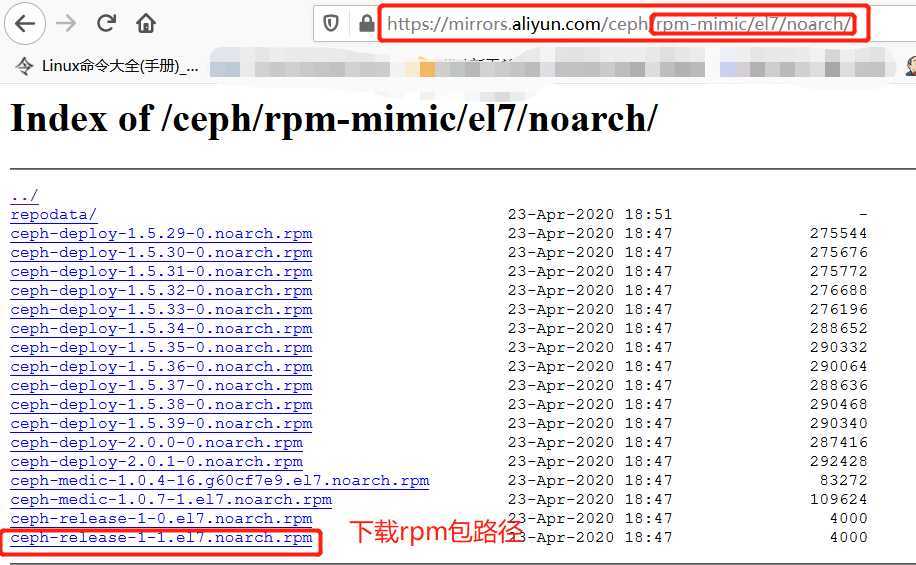
Ceph官方的仓库路径为http://download.ceph.com/,目前主流版本相关的程序包都在提供,包括kraken、 luminous和mimic等,它们分别位于rpm-mimic等一类的目录中。直接安装程序包即可生成相关的yum仓库相关的 配置文件,程序包位于相关版本的noarch目录下,例如rpm-mimic/el7/noarch/ceph-release-1-1.el7.noarch.rpm 是为负责生成适用于部署mimic版本Ceph的yum仓库配置文件,因此直接在线安装此程序包,也能直接生成yum仓 库的相关配置,由于Ceph官网下载比较慢,我们可以在阿里云仓库内下载。
Ceph包下载的阿里云地址:https://mirrors.aliyun.com/ceph/?spm=a2c6h.13651104.0.0.5d3322d1okfAzl
在ceph-admin管理节点、mon01、mon02、mon03、stor04节点上,使用如下命令即可安装生成mimic版本相关的yum仓库配置:
[root@ceph-admin~]#rpm -ivh https://mirrors.aliyun.com/ceph/rpm-mimic/el7/noarch/ceph-release-1-1.el7.noarch.rpm
因为Ceph包会依赖epel仓库的源包,会解决依赖关系,因此需要在每台主机上安装epel-release包
# yum install epel-release -y
1、首先需要在各节点以管理员的身份创建一个专用于ceph-deploy的特定用户账号,例如cephadm(建议不要使用 ceph),并为其设置认证密centos。
# useradd cephadm && echo centos | passwd --stdin cephadm
2、而后,在每台主机节点上新创建的用户cephadm都有无密码运行sudo命令的权限。
~]# echo "cephadm ALL = (root) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/cephadm # 在管理节点上创建一个授予sudo权限,并免密登录 ~]# chmod 0440 /etc/sudoers.d/cephadm # 在管理节点上将此配置文件复制到远程主机上 # scp -p /etc/sudoers.d/cephadm mon01:/etc/sudoers.d/cephadm # scp -p /etc/sudoers.d/cephadm mon02:/etc/sudoers.d/cephadm # scp -p /etc/sudoers.d/cephadm mon03:/etc/sudoers.d/cephadm # scp -p /etc/sudoers.d/cephadm stor04:/etc/sudoers.d/cephadm
测试普通用户cephadm用户是否已经授权root权限,并实现了不需要密码验证
[root@ceph-adminyum.repos.d]#su - cephadm # 切换到cephadm用户上
Last login: Thu Jul 16 15:01:33 CST 2020 on pts/0
[cephadm@ceph-admin~]$sudo -l # 查看此时普通用户的权限
Matching Defaults entries for cephadm on ceph-admin:
!visiblepw, always_set_home, match_group_by_gid, always_query_group_plugin, env_reset, env_keep="COLORS DISPLAY HOSTNAME HISTSIZE
KDEDIR LS_COLORS", env_keep+="MAIL PS1 PS2 QTDIR USERNAME LANG LC_ADDRESS LC_CTYPE", env_keep+="LC_COLLATE LC_IDENTIFICATION
LC_MEASUREMENT LC_MESSAGES", env_keep+="LC_MONETARY LC_NAME LC_NUMERIC LC_PAPER LC_TELEPHONE", env_keep+="LC_TIME LC_ALL LANGUAGE
LINGUAS _XKB_CHARSET XAUTHORITY", secure_path=/sbin\:/bin\:/usr/sbin\:/usr/bin
User cephadm may run the following commands on ceph-admin:
(root) NOPASSWD: ALL # ALL 所有权限
[cephadm@ceph-admin~]$exit
logout
[root@ceph-adminyum.repos.d]#sudo -l # 查看此时root用户的权限
Matching Defaults entries for root on ceph-admin:
!visiblepw, always_set_home, match_group_by_gid, always_query_group_plugin, env_reset, env_keep="COLORS DISPLAY HOSTNAME HISTSIZE
KDEDIR LS_COLORS", env_keep+="MAIL PS1 PS2 QTDIR USERNAME LANG LC_ADDRESS LC_CTYPE", env_keep+="LC_COLLATE LC_IDENTIFICATION
LC_MEASUREMENT LC_MESSAGES", env_keep+="LC_MONETARY LC_NAME LC_NUMERIC LC_PAPER LC_TELEPHONE", env_keep+="LC_TIME LC_ALL LANGUAGE
LINGUAS _XKB_CHARSET XAUTHORITY", secure_path=/sbin\:/bin\:/usr/sbin\:/usr/bin
User root may run the following commands on ceph-admin:
(ALL) ALL # 也是授予所有权限
3、在管理节点上配置用户基于密钥的ssh认证
ceph-deploy命令不支持运行中途的密码输入,因此,必须在管理节点上生成SSH密 钥并将其公钥分发至Ceph集群的各节点上。下面直接以cephadm用户的身份生成SSH密钥对
[root@ceph-admin~]#su - cephadm # 切换到普通用户进行创建公私钥对 [cephadm@ceph-admin~]$ssh-keygen # 生成公私钥对
而后即可把公钥拷贝到各Ceph节点:
# ssh-copy-id cephadm@mon01: # 这里直接用到了hostname名称解析IP的方法 # ssh-copy-id cephadm@mon02: # ssh-copy-id cephadm@mon03: # ssh-copy-id cephadm@stor04:
1、此时需要切换到root用户安装ceph-deploy,Ceph存储集群的部署的过程可通过管理节点使用ceph-deploy全程进行,这里首先在管理节点安装ceph-deploy及其依赖到的程序包:
[root@ceph-admin ~]# yum update [root@ceph-admin ~]# yum install ceph-deploy python-setuptools python2-subprocess32 -y
1. 首先在管理节点上以cephadm用户创建集群相关的配置文件目录
[root@ceph-admin~]#su - cephadm Last login: Thu Jul 16 15:18:30 CST 2020 on pts/0 [cephadm@ceph-admin~]$ mkdir ceph-cluster [cephadm@ceph-admin~]$cd ceph-cluster/
2、初始化第一个MON节点,准备创建集群:
初始化第一个MON节点的命令格式为”ceph-deploy new {initial-monitor-node(s)}“,
本示例中,mon01即为第一个 MON节点名称,其名称必须与节点当前实际使用的主机名称保存一致。运行如下命令即可生成初始配置:
[cephadm@ceph-adminceph-cluster]$ceph-deploy new --cluster-network 172.0.0.0/8 --public-network 192.168.7.0/24 mon01 # 其中--cluster-network 172.0.0.0/24是内网地址, --pubilc-network 192.168.7.0/24 是公网地址
如果没有添加--cluster和--public,两个选项,也可以在生成的ceph.conf配置文件中添加内网和公网的IP地址
[cephadm@ceph-adminceph-cluster]$ls # 此时可以在管理节点看到生成了三个文件 ceph.conf ceph-deploy-ceph.log ceph.mon.keyring [cephadm@ceph-adminceph-cluster]$cat ceph.conf [global] fsid = 247fed18-54e3-4120-a663-863ba5a385dc # 生成的唯一ID public_network = 192.168.7.0/24 # 修改为公网地址 cluster_network = 172.0.0.0/8 # 修改为内网地址 mon_initial_members = mon01 mon_host = 192.168.7.101 auth_cluster_required = cephx # ceph集群的认证 auth_service_required = cephx auth_client_required = cephx
1、ceph-deploy命令能够以远程的方式连入Ceph集群各节点完成程序包安装等操作,命令格式如下:
ceph-deploy install {ceph-node} [{ceph-node} ...]
因此,若要将mon01、mon02、mon03和stor04配置为Ceph集群节点,则执行如下命令即可:
提示:在ceph管理节点用命令ceph-deploy install去安装Ceph集群过程中,因为不能同步在每个主机上安装,执行比较慢,所以我们需要在集群各节点独立安装ceph程序包,其方法如下:
[root@mon1~]#yum install ceph ceph-radosgw -y
因此,若要将mon01、mon02、mon03和stor04配置为Ceph集群节点,则执行如下命令即可:
[root@ceph-admin~]# ceph-deploy install --help # 查询帮助
usage: ceph-deploy install [-h] [--stable [CODENAME] | --release [CODENAME] |
--testing | --dev [BRANCH_OR_TAG]]
[--dev-commit [COMMIT]] [--mon] [--mgr] [--mds]
[--rgw] [--osd] [--tests] [--cli] [--all]
[--adjust-repos | --no-adjust-repos | --repo]
[--local-mirror [LOCAL_MIRROR]]
[--repo-url [REPO_URL]] [--gpg-url [GPG_URL]]
[--nogpgcheck]
HOST [HOST ...]
Install Ceph packages on remote hosts.
positional arguments:
HOST hosts to install on
optional arguments:
-h, --help show this help message and exit
--stable [CODENAME] [DEPRECATED] install a release known as CODENAME (done
by default) (default: None)
--release [CODENAME] install a release known as CODENAME (done by default)
(default: None)
--testing install the latest development release
--dev [BRANCH_OR_TAG]
install a bleeding edge build from Git branch or tag
(default: master)
--dev-commit [COMMIT]
install a bleeding edge build from Git commit
(defaults to master branch)
--mon install the mon component only
--mgr install the mgr component only
--mds install the mds component only
--rgw install the rgw component only
--osd install the osd component only
--tests install the testing components
--cli, --common install the common component only
--all install all Ceph components (mon, osd, mds, rgw)
except tests. This is the default
--adjust-repos install packages modifying source repos
--no-adjust-repos install packages without modifying source repos # 如果已经在各个节点安装了ceph-radosgw和ceph包,就需要添加此选项,否则就会重新再次安装
--repo install repo files only (skips package installation)
--local-mirror [LOCAL_MIRROR]
Fetch packages and push them to hosts for a local repo
mirror
--repo-url [REPO_URL]
specify a repo URL that mirrors/contains Ceph packages
--gpg-url [GPG_URL] specify a GPG key URL to be used with custom repos
(defaults to ceph.com)
--nogpgcheck install packages without gpgcheck
在cephadm普通用户上,开始对上面安装的ceph和ceph-radosgw依赖包进行校验:
[cephadm@ceph-admin~]$ su - cephadm # 切换到cephadm用户上 [cephadm@ceph-admin~]$ceph-deploy install --no-adjust-repos mon01 mon02 mon03 stor04 # 对每台集群节点进行校验,如果未安装上面的ceph和依赖包,就不需要加--no-adjust-repos选项
2、配置初始MON节点,并收集所有密钥
[cephadm@ceph-admin~]$cd ceph-cluster/ [cephadm@ceph-adminceph-cluster]$ceph-deploy mon create-initial
3、把配置文件和admin密钥拷贝Ceph集群各节点,以免得每次执行”ceph“命令行时不得不明确指定MON节点地址 和ceph.client.admin.keyring:
[cephadm@ceph-adminceph-cluster]$ ceph-deploy admin mon01 mon02 mon03 stor04 # 将密钥都传递到每个Ceph集群节点与stor04节点
而后在各个Ceph集群中需要运行ceph命令的的节点上(或所有节点上)以root用户的身份设定用户cephadm能够读 取/etc/ceph/ceph.client.admin.keyring文件:
[root@mon01ceph]#setfacl -m u:cephadm:r /etc/ceph/ceph.client.admin.keyring
4、配置Manager节点,启动ceph-mgr进程(仅Luminious+版本),指定一个主机位mgr管理节点,在cephadmin用户的ceph-cluster目录下执行命令:
[cephadm@ceph-adminceph-cluster]$ ceph-deploy mgr create mon01 # 我们以mon01为例,让mon01主机为管理节点。
5、在ceph管理节点安装一个管理集群的客户端,并在ceph管理节点将密钥复制给本机一份:
[root@ceph-admin~]#yum install ceph-common -y # 在ceph管理节点安装一个控制集群的客户端 [cephadm@ceph-adminceph-cluster]$ceph-deploy admin ceph-admin # 将密钥推送给本机一份 [root@ceph-admin~]#setfacl -m u:cephadm:r /etc/ceph/ceph.client.admin.keyring # 并在ceph的root用户下授予普通用户的读权限到私钥文件上
6、在Ceph集群内的节点上以cephadm用户的身份运行如下命令,测试集群的健康状态
[cephadm@ceph-adminceph-cluster]$ceph -s # 此时可以看到ceph的运行状态
cluster:
id: 494d5c79-00cd-4b85-bc9d-4ebcacda30a8
health: HEALTH_WARN
OSD count 0 < osd_pool_default_size 3
services:
mon: 1 daemons, quorum mon01
mgr: mon01(active)
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
1、“ceph-deploy disk”命令可以检查并列出OSD节点上所有可用的磁盘的相关信息
[cephadm@ceph-adminceph-cluster]$ ceph-deploy disk list mon01 mon02 mon03
2、而后,在管理节点上使用ceph-deploy命令擦除计划专用于OSD磁盘上的所有分区表和数据以便用于OSD,命令格式 为”ceph-deploy disk zap {osd-server-name} {disk-name}“,
需要注意的是此步会清除目标设备上的所有数据。下 面分别擦净mon01、mon02、mon03和stor04上用于OSD的一个磁盘设备sdb和sdc:在普通用户cephadm,在/home/cephadm/ceph-cluster目录下执行
# ceph-deploy disk zap mon01 /dev/sdc # ceph-deploy disk zap mon02 /dev/sdc # ceph-deploy disk zap mon03 /dev/sdc # ceph-deploy disk zap stor04 /dev/sdc # ceph-deploy disk zap mon01 /dev/sdb # ceph-deploy disk zap mon02 /dev/sdb # ceph-deploy disk zap mon03 /dev/sdb # ceph-deploy disk zap stor04 /dev/sdb
早期版本的ceph-deploy命令支持在将添加OSD的过程分为两个步骤:准备OSD和激活OSD,但新版本中,此种操作 方式已经被废除,添加OSD的步骤只能由命令”ceph-deploy osd create {node} --data {data-disk}“一次完成,默认 使用的存储引擎为bluestore。 如下命令即可分别把mon01、mon02、mon03和stor04上的设备sdb和sdc添加为OSD:在普通用户cephadm,在/home/cephadm/ceph-cluster目录下执行
# ceph-deploy osd create mon01 --data /dev/sdb # ceph-deploy osd create mon02 --data /dev/sdb # ceph-deploy osd create --data /dev/sdb mon03 # ceph-deploy osd create --data /dev/sdc mon01 # ceph-deploy osd create --data /dev/sdc mon02 # ceph-deploy osd create --data /dev/sdc mon03 # ceph-deploy osd create --data /dev/sdc stor04 # ceph-deploy osd create --data /dev/sdb stor04
查看此时的磁盘空间大小,到此Ceph集群已经部署完毕。
[cephadm@ceph-adminceph-cluster]$ceph -s # 查看此时的磁盘空间大小
cluster:
id: 494d5c79-00cd-4b85-bc9d-4ebcacda30a8
health: HEALTH_OK
services:
mon: 1 daemons, quorum mon01
mgr: mon01(active)
osd: 6 osds: 6 up, 6 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 6.0 GiB used, 294 GiB / 300 GiB avail # 可以看到一共有6块磁盘加入,并有300G大小
pgs:
Ceph集群中的一个OSD通常对应于一个设备,且运行于专用的守护进程。在某OSD设备出现故障,或管理员出于管 理之需确实要移除特定的OSD设备时,需要先停止相关的守护进程,而后再进行移除操作。对于Luminous及其之后 的版本来说,停止和移除命令的格式分别如下所示:
若类似如下的OSD的配置信息存在于ceph.conf配置文件中,管理员在删除OSD之后手动将其删除。
不过,对于Luminous之前的版本来说,管理员需要依次手动执行如下步骤删除OSD设备:
存取数据时,客户端必须首先连接至RADOS集群上某存储池,而后根据对象名称由相关的CRUSH规则完成数据对象 寻址。于是,为了测试集群的数据存取功能,这里首先创建一个用于测试的存储池mypool,并设定其PG数量为16 个。
[cephadm@ceph-adminceph-cluster]$ ceph osd pool create mypool 16 pool ‘mypool‘ created
列出创建的存储池
[cephadm@ceph-adminceph-cluster]$ceph osd pool ls mypool
而后即可将测试文件上传至存储池中,例如下面的“rados put”命令将/etc/issue文件上传至mypool存储池,对象名 称依然保留为文件名issue,而“rados ls”命令则可以列出指定存储池中的数据对象。
[cephadm@ceph-adminceph-cluster]$rados put issue /etc/issue --pool=mypool # 上传文件 [cephadm@ceph-adminceph-cluster]$rados ls --pool=mypool # 列出上传了哪些文件 issue
而“ceph osd map”命令可以获取到存储池中数据对象的具体位置信息:
[cephadm@ceph-adminceph-cluster]$ceph osd map mypool issue osdmap e28 pool ‘mypool‘ (1) object ‘issue‘ -> pg 1.651f88da (1.a) -> up ([5,4,0], p5) acting ([5,4,0], p5)
删除数据对象,“rados rm”命令是较为常用的一种方式:
[cephadm@ceph-adminceph-cluster]$rados rm issue --pool=mypool
删除存储池命令存在数据丢失的风险,Ceph于是默认禁止此类操作。管理员需要在ceph.conf配置文件中启用支持删 除存储池的操作后,方可使用类似如下命令删除存储池
[cephadm@ceph-adminceph-cluster]$ceph osd pool rm mypool mypool --yes-i-really-really-mean-it Error EPERM: pool deletion is disabled; you must first set the mon_allow_pool_delete config option to true before you can destroy a pool
Ceph存储集群需要至少运行一个Ceph Monitor和一个Ceph Manager,生产环境中,为了实现高可用性,Ceph存储 集群通常运行多个监视器,以免单监视器整个存储集群崩溃。Ceph使用Paxos算法,该算法需要半数以上的监视器 (大于n/2,其中n为总监视器数量)才能形成法定人数。尽管此非必需,但奇数个监视器往往更好。
“ceph-deploy mon add {ceph-nodes}”命令可以一次添加一个监视器节点到集群中。例如,下面的命令可以将集群 中的stor02和stor03也运行为监视器节点:
[cephadm@ceph-adminceph-cluster]$ceph-deploy mon add mon01 # 添加三个节点,最好是奇数节点数
[cephadm@ceph-adminceph-cluster]$ceph-deploy mon add mon02
[cephadm@ceph-adminceph-cluster]$ceph-deploy mon add mon03
[mon03][DEBUG ] "fsid": "494d5c79-00cd-4b85-bc9d-4ebcacda30a8",
[mon03][DEBUG ] "modified": "2020-07-16 23:49:52.759297",
[mon03][DEBUG ] "mons": [
[mon03][DEBUG ] {
[mon03][DEBUG ] "addr": "192.168.7.102:6789/0", # 第一个节点和端口号
[mon03][DEBUG ] "name": "mon01",
[mon03][DEBUG ] "public_addr": "192.168.7.102:6789/0",
[mon03][DEBUG ] "rank": 0
[mon03][DEBUG ] },
[mon03][DEBUG ] {
[mon03][DEBUG ] "addr": "192.168.7.103:6789/0",
[mon03][DEBUG ] "name": "mon02",
[mon03][DEBUG ] "public_addr": "192.168.7.103:6789/0",
[mon03][DEBUG ] "rank": 1
[mon03][DEBUG ] },
[mon03][DEBUG ] {
[mon03][DEBUG ] "addr": "192.168.7.104:6789/0",
[mon03][DEBUG ] "name": "mon03",
[mon03][DEBUG ] "public_addr": "192.168.7.104:6789/0",
[mon03][DEBUG ] "rank": 2
[mon03][DEBUG ] }
[mon03][DEBUG ] ]
[mon03][DEBUG ] },
[mon03][DEBUG ] "name": "mon03",
[mon03][DEBUG ] "outside_quorum": [],
[mon03][DEBUG ] "quorum": [],
[mon03][DEBUG ] "rank": 2,
[mon03][DEBUG ] "state": "electing", # 三个节点处于选举状态
[mon03][DEBUG ] "sync_provider": []
[mon03][DEBUG ] }
设置完成后,可以在ceph客户端上查看监视器及法定人数的相关状态:
[cephadm@ceph-adminceph-cluster]$ceph quorum_status --format json-pretty # 以最美观的json格式查看状态格式
{
"election_epoch": 12,
"quorum": [
0,
1,
2
],
"quorum_names": [
"mon01",
"mon02",
"mon03"
],
"quorum_leader_name": "mon01",
"monmap": {
"epoch": 3,
"fsid": "494d5c79-00cd-4b85-bc9d-4ebcacda30a8",
"modified": "2020-07-16 23:49:52.759297",
"created": "2020-07-16 22:19:19.355909",
"features": {
"persistent": [
"kraken",
"luminous",
"mimic",
"osdmap-prune"
],
"optional": []
},
"mons": [
{
"rank": 0,
"name": "mon01",
"addr": "192.168.7.102:6789/0",
"public_addr": "192.168.7.102:6789/0"
},
{
"rank": 1,
"name": "mon02",
"addr": "192.168.7.103:6789/0",
"public_addr": "192.168.7.103:6789/0"
},
{
"rank": 2,
"name": "mon03",
"addr": "192.168.7.104:6789/0",
"public_addr": "192.168.7.104:6789/0"
}
]
}
}
Ceph Manager守护进程以“Active/Standby”模式运行,部署其它ceph-mgr守护程序可确保在Active节点或其上的 ceph-mgr守护进程故障时,其中的一个Standby实例可以在不中断服务的情况下接管其任务。
“ceph-deploy mgr create {new-manager-nodes}”命令可以一次添加多个Manager节点。下面的命令可以将stor02 节点作为备用的Manager运行,由于前面已经创建了mon01为管理节点,然后此时添加mon02为第二个管理节点:
[cephadm@ceph-adminceph-cluster]$ceph-deploy mgr create mon02
添加完成后,“ceph -s”命令的services一段中会输出相关信息
[cephadm@ceph-adminceph-cluster]$ceph -s
cluster:
id: 494d5c79-00cd-4b85-bc9d-4ebcacda30a8
health: HEALTH_WARN
too few PGs per OSD (8 < min 30)
clock skew detected on mon.mon02, mon.mon03
services:
mon: 3 daemons, quorum mon01,mon02,mon03
mgr: mon01(active), standbys: mon02 # 第二个管理节点mon02,为备用节点
osd: 6 osds: 6 up, 6 in
data:
pools: 1 pools, 16 pgs
objects: 0 objects, 0 B
usage: 6.0 GiB used, 294 GiB / 300 GiB avail
pgs: 16 active+clean
原文:https://www.cnblogs.com/struggle-1216/p/13311232.html