1、什么是脑裂
如果服务器网络中断或者服务器宏机,那么集群会有可能被划分为两个部分,各自与自己的master来管理,这就是脑裂。
假设ES集群,刚开始服务器1是主节点,其它两台为从节点

然后假设Master受到影响,挂机了。此时假设服务器2成为主节点,服务器2和服务器3成为一个新的集群。
接着服务器1恢复了,它有可能不会成为Slave,不会加入到原先的集群,这样相当于服务器被割裂开来,如下图所示。
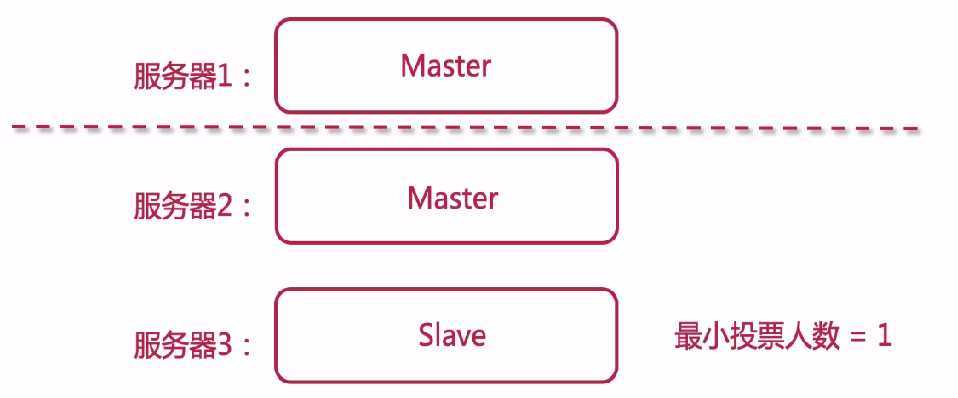
为什么会出现上面的情况?
因为ES有最小投票人数,默认是1。服务器1恢复后,自己给自己投票,就能成为master。就有2个集群了。 对于ES集群来说,这时候不可能有两个集群的,服务器1所在的集群数据是不完整的。
2、如何解决脑裂问题
解决实现原理:半数以上节点同意选举,节点方可能成为master
discovery.zen.minimum_master_nodes = (N/2 + 1) N并不代表所有的ES节点数,配置了node.master=true的所有节点数。
老版本可能出现脑裂的问题。
原文:https://www.cnblogs.com/linlf03/p/13337872.html