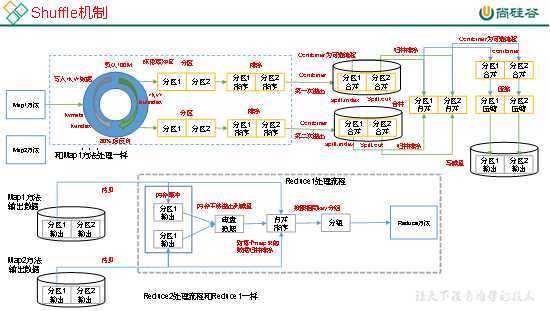
Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle。如图4-14所示。


1.需求
将统计结果按照手机归属地不同省份输出到不同文件中(分区)
(1)输入数据

(2)期望输出数据
手机号136、137、138、139开头都分别放到一个独立的4个文件中,其他开头的放到一个文件中。
2.需求分析

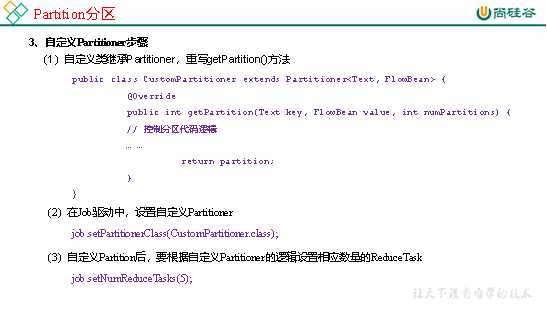
3.在案例2.4的基础上,增加一个分区类

package com.atguigu.mapreduce.flowsum; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Partitioner; public class ProvincePartitioner extends Partitioner<Text, FlowBean> { @Override public int getPartition(Text key, FlowBean value, int numPartitions) { // 1 获取电话号码的前三位 String preNum = key.toString().substring(0, 3); int partition = 4; // 2 判断是哪个省 if ("136".equals(preNum)) { partition = 0; }else if ("137".equals(preNum)) { partition = 1; }else if ("138".equals(preNum)) { partition = 2; }else if ("139".equals(preNum)) { partition = 3; } return partition; } }
4.在驱动函数中增加自定义数据分区设置和ReduceTask设置
package com.atguigu.mapreduce.flowsum; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class FlowsumDriver { public static void main(String[] args) throws IllegalArgumentException, IOException, ClassNotFoundException, InterruptedException { // 输入输出路径需要根据自己电脑上实际的输入输出路径设置 args = new String[]{"e:/output1","e:/output2"}; // 1 获取配置信息,或者job对象实例 Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); // 2 指定本程序的jar包所在的本地路径 job.setJarByClass(FlowsumDriver.class); // 3 指定本业务job要使用的mapper/Reducer业务类 job.setMapperClass(FlowCountMapper.class); job.setReducerClass(FlowCountReducer.class); // 4 指定mapper输出数据的kv类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(FlowBean.class); // 5 指定最终输出的数据的kv类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(FlowBean.class); // 8 指定自定义数据分区 job.setPartitionerClass(ProvincePartitioner.class); // 9 同时指定相应数量的reduce task job.setNumReduceTasks(5); // 6 指定job的输入原始文件所在目录 FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 7 将job中配置的相关参数,以及job所用的java类所在的jar包, 提交给yarn去运行 boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); } }
原文:https://www.cnblogs.com/qiu-hua/p/13337874.html
