整体效果:
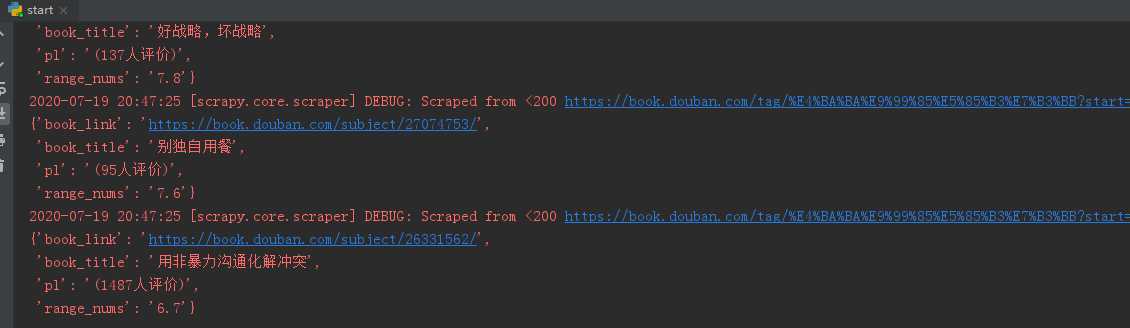
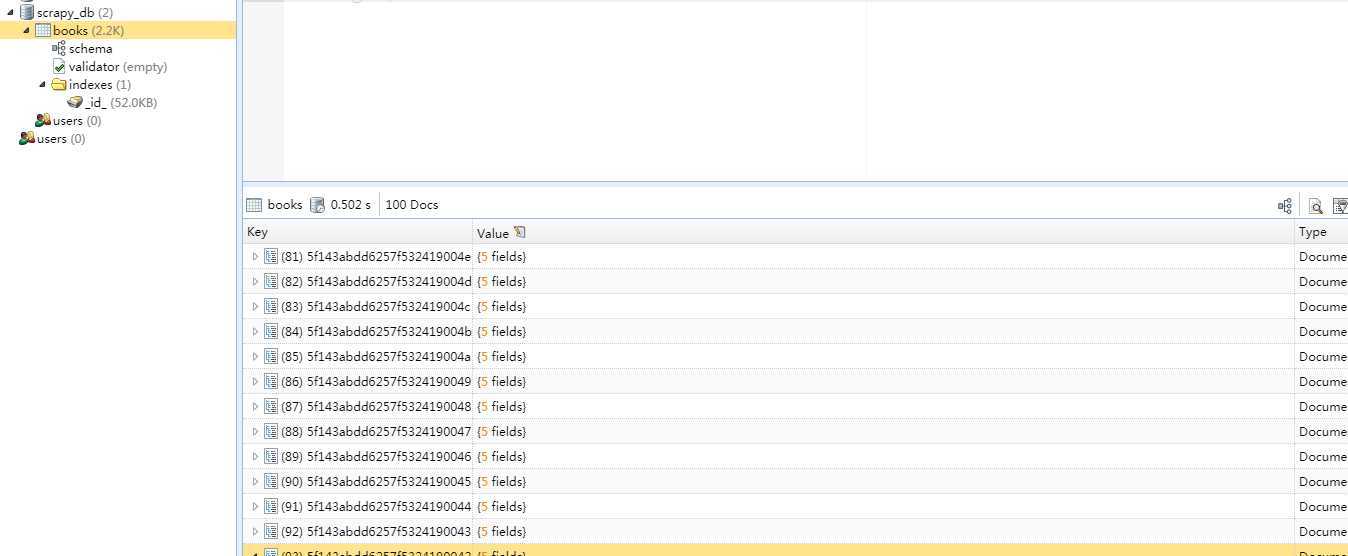
整体思路:
通过标签页的分类链接,获取全部书籍链接
第一步:调整settings文件
ROBOTSTXT_OBEY = False #rebots协议关闭
DOWNLOAD_DELAY = 1 #下载延迟,尽量打开
DEFAULT_REQUEST_HEADERS = {
‘Accept‘: ‘text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8‘,
‘Accept-Language‘: ‘en‘,
‘User-Agent‘:"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36"
}#加入请求头,伪装自己
新写一个start.py文件,用以开始scrapy服务,方便以后调试
from scrapy import cmdline
cmdline.execute("scrapy crawl douban".split())
第2步:在item里写入想要的字段
book_title = scrapy.Field()
book_link = scrapy.Field()
range_nums = scrapy.Field()
pl = scrapy.Field()
第3步:正式工作开始,爬取标签页包含的链接
start_urls = [‘https://book.douban.com/tag/?view=type&icn=index-sorttags-all‘]
起始链接:https://book.douban.com/tag/?view=type&icn=index-sorttags-all 包含所有标签链接。进行解析拼接想要的链接
def parse(self, response):
divs = response.xpath(‘//div[@class="article"]/div[2]‘)
for div in divs:
names = div.xpath(‘.//a/h2/text()‘)
# print(names)
trs = div.xpath(‘.//table[@class="tagCol"]/tbody‘)
for tr in trs:
tds = tr.xpath(‘.//tr‘)
for td in tds:
td_links = td.xpath(‘.//a/@href‘).extract()
for td in td_links:
detail_url = self.url + td
yield scrapy.Request(url=detail_url, callback=self.parse_tag)#访问详情页
第4步:对详情页进行解析,获取想要的字段。通过item返回给管道。
def parse_tag(self,response):
# names = response.meta.get("info")
# print(response.url)
lis = response.xpath(‘//div[@id="subject_list"]/ul‘)
for li in lis:
book_title = li.xpath(‘.//div[@class="info"]/h2/a/@title‘).getall()
book_link = li.xpath(‘.//div[@class="info"]/h2/a/@href‘).getall()
range_nums = li.xpath(‘.//div[@class="star clearfix"]/span[2]/text()‘).getall()
pl = li.xpath(‘.//div[@class="star clearfix"]/span[3]/text()‘).getall()
pls = []
for i in range(len(pl)):
pls.append(pl[i].strip())
for a,b,c,d in zip(book_title,book_link,range_nums,pls):
item = DushuItem(book_link=b, book_title=a, range_nums=c, pl=d)
yield item
第5步:获取一页的链接进行判断并请求
next_url = response.xpath(‘//span[@class="next"]/a/@href‘).extract()
if next_url:
next_link = self.url + next_url[0]
yield scrapy.Request(url=next_link,callback=self.parse_tag)
第6部:存储item到mongoDB
开启mongoDB服务:
在cmd 中输入 mongod --dbpath="D:\MongoDB\db"
在pipeline写入:
from pymongo import MongoClient
from scrapy import Item
class MongoDBPipeline(object):
# 打开数据库
def open_spider(self, spider):
db_uri = spider.settings.get(‘MONGODB_URI‘, ‘mongodb://localhost:27017‘)
db_name = spider.settings.get(‘MONOGDB_DB_NAME‘, ‘scrapy_db‘)
self.db_client = MongoClient(db_uri)
self.db = self.db_client[db_name]
# 关闭数据库
def close_spider(self, spider):
self.db_client.close()
# 对数据进行处理
def process_item(self, item, spider):
self.insert_db(item)
return item
# 插入数据
def insert_db(self, item):
if isinstance(item, Item):
item = dict(item)
self.db.books.insert(item)
在settings加入
MONGODB_URI = ‘mongodb://127.0.0.1:27017‘
MONGODB_DB_NAME = ‘scrapy_db‘
第7步:打开pipeline
ITEM_PIPELINES = {
# ‘dushu.pipelines.DushuPipeline‘: 300,
‘dushu.pipelines.MongoDBPipeline‘: 300,
}
启动
原文:https://www.cnblogs.com/kkdadao/p/13341175.html