| series |
系列:是用于存储一行或者一列的数据,以及与之相关的索引的集合,序列比列表多了一个索引的概念
|
| DataFrame | 数据框 |
Series(a,index = [])
s.append()
s.drop()
切片
from pandas import Series # 创建Series以及索引 x = Series([‘a‘, True, 1,45,‘2‘,67,98], index=[‘first‘, ‘second‘, ‘third‘,‘forth‘,‘fifth‘,‘sixth‘,‘seventh‘]) # x = Series([‘a‘, True, 1]) 这种方式创建 索引会默认为是 0,1,2 #访问 print(x[1]); # #根据index访问 print(x[‘second‘]); # 不能追加单个元素 x.append(‘2‘) # 追加一个序列 x = x.append(Series([‘2‘])) # 若仅仅是x.append(Series([‘2‘])) 是不能追加成功到x的 x = x.append(Series([‘2‘])) # 这种形式添加 两个索引值都为0 # 需要一个变量来承担 print( ‘2‘ in x) # 默认的值为key 所为FALSE # 判断值是否存在 print( ‘2‘ in x.values) # True # 切片 print(x[1:3]) # 包括1不包括3 # 定位获取,这个方法经常用于随机抽样 print(x[[0, 2, 1]]) # 根据index删除 x = x.drop(0) x = x.drop(‘first‘) # 根据位置删除 x = x.drop(x.index[0]) # 因为这样x。drop里面是索引值了 用了x.index() # 根据值删除 x = x[‘2‘!=x.values]
from pandas import Series x = Series([‘a‘, True, 1], index=[‘first‘, ‘second‘, ‘third‘]) for v in x: # 取指 而不是索引 print("x中的值 :", v) """x中的值 : a x中的值 : True x中的值 : 1"""
Dataframe() 用字典+列表的方式,创建 表格并确定索引
切片
df.iloc[a:b,c:d] 行+列的切片 df.iloc[a] 列的切片 df.iloc[a:b,c:d] = [] 也可用来定位某一个格并修改
df.at[a,b] 行索引 +列名
df.columns
df.index 可以用来列出index 也可用来修改索引
df.drop 删除行或者列 要表明axis =0/1 不标默认为0
del df[列名] 切片删除列
df.loc[] = [几个列几个元素] 可以用来增加 也可以用来修改
df[列名] = [几行几个元素] 可以用来增加列
df.groupby(分组地段)[被分类字段].agg(函数)
df.iterrows() 返回两个值 第一格为index 第二格是行信息
df.apply(func,axis=0/1) 将行或列的每个元素基于函数判断
len(df)为几行
df[列名].astype(str) 整列转换成字符
from pandas import DataFrame #%% df = DataFrame({ ‘age‘: [21, 22, 23], ‘name‘: [‘KEN‘, ‘John‘, ‘JIMI‘] }) #%% df = DataFrame(data={ ‘age‘: [21, 22, 23], ‘name‘: [‘KEN‘, ‘John‘, ‘JIMI‘] }, index=[‘first‘, ‘second‘, ‘third‘]) #%% # 按列访问 打印出了该列的所有数值 print(df[‘age‘]) #%% #按行访问 print(df[1:2]) #打印出了第一行的数值 #%% #按行列号访问 print(df.iloc[0:2, 0:1]) #打印出了[0-2)行 [0-1)列的单元格 #%% #按行索引,列名访问 print(df.at[‘first‘, ‘name‘]) #%% #修改列名 df.columns=[‘age2‘, ‘name2‘] #%% #修改行索引 df.index = range(1,4) # 把索引改成了123 #%% print(df.index) # RangeIndex(start=1, stop=4, step=1) #%% #根据行索引删除 df = df.drop(1, axis=0) # 删除了第一行 axis= 0 是指行 =1 是指列 #%% #默认参数axis=0 #根据列名进行删除 df = df.drop(‘age2‘, axis=1) #%% #第二种删除列的方法 del df[‘age2‘] #%% #增加行,注意,这种方法,效率非常低,不应该用于遍历中 df.loc[len(df)] = [24, "KENKEN"] #%% df.loc[2] = [24, "KENKEN"] # 也可以用来修改 #%% #增加列 df[‘newColumn‘] = [2, 4, 6, 8]
import numpy from pandas import DataFrame df = DataFrame({ ‘key1‘: [‘a‘,‘a‘,‘b‘,‘b‘,‘a‘], ‘key2‘: [‘one‘,‘two‘,‘one‘,‘two‘,‘one‘], ‘data1‘: numpy.random.randn(5), ‘data2‘: numpy.random.randn(5) # 随机生成5个数字 }); #%% df2 = df.groupby(‘key1‘)[‘data1‘,‘data2‘].agg(lambda arr:arr.max()-arr.min()) # agg 聚合函数 将data1 和 data2 根据key1 的值进行聚合分组 #%% arr1 = numpy.random.randn(2,4) print(arr1) # 返回两行四列的矩阵,内容为从标准正态分布中返回一个或多个样本值
from pandas import Series from pandas import DataFrame df = DataFrame({ ‘age‘: Series([21, 22, 23]), ‘name‘: Series([‘KEN‘, ‘John‘, ‘JIMI‘]) }) #%% #遍历列名 for r in df: print(r); #%% #遍历列 for cName in df: print(‘df中的列 :\n‘, cName) print(‘df中的值 :\n‘, df[cName]); print("---------------------") #%% #遍历行,方法一 for rIndex in df.index: print(‘现在是第 ‘, rIndex, ‘ 行‘) print(df.iloc[rIndex]) #%% #遍历行,方法二 for r in df.values: print(r) print(r[0]) print(r[1]) print("---------------------") #%% #遍历行,方法三 for index, row in df.iterrows(): print(‘第 ‘, index, ‘ 行:‘) print(row) print("---------------------")
print(df.apply(lambda x: min(x))) # 选出每列的最小值 print(df.apply(lambda x: min(x), axis=1)) # 选出每行的最小值 #%% #判断每个列,值是否都大于0 print(df.apply(lambda x: numpy.all(x>0), axis=1)) # 是否每行都大于0 #%% #结合过滤 print(df[df.apply(lambda x: numpy.all(x>0), axis=1)]) # 选出每个元素都大于0 的行
同一时间执行多次操作,对不同的数据执行同样的一个或一批指令
函数运算:相同位置的数据进行函数的计算,函数返回结果保留在相同的位置
四则运算,相同位置的数据进行运算,结果保留在相同的位置,直到和长的变量长度一致
如果两个向量长度不一样,就会使用rep方法,将短的变量不断重复
r[r>0.3]: 选出矩阵r中>0.3 的元素
file 文件路径, names :列名,默认文件中的第一行作为列名,
sep:分隔符,默认为空,表示默认导入为一列
encoding: 设置文件编码,在导入中文时需要设置为UTF-8
read_csv(file,encoding) 导入csv 文件(是用逗号做分隔符号)
read_table(file,names=[列1,列2,....], sep = "", encoding,....) 导入普通文本文件
read_excel(file,sheetname,header) /路径+sheet 名字 + 列名(默认为第一行) 导入excel 文件 ,header 是数字表示第几行作为列名
to_csv(filepath,sep=",",index = TRUE,header = TRUE) index=True 为导出行序号, header = True 导出列名: 导出文本文件
from pandas import read_csv; #%% df1 = read_csv(‘/Volumes/CHASESKY/python/03-数据分析与数据挖掘篇/1-数据分析数据可视化实战-(Python3.5)/章节4数据处理/4/4.1/1.csv‘, encoding=‘UTF-8‘) #%% # 下载notepad++ 解决中文乱码, 修改文件编码 mac 不支持 from pandas import read_table; df2 = read_table(‘/Volumes/CHASESKY/python/03-数据分析与数据挖掘篇/1-数据分析数据可视化实战-(Python3.5)/章节4数据处理/4/4.1/2.txt‘, names=[‘age‘, ‘name‘], sep=‘,‘) #%% from pandas import read_excel; df3 = read_excel(‘/Volumes/CHASESKY/python/03-数据分析与数据挖掘篇/1-数据分析数据可视化实战-(Python3.5)/章节4数据处理/4/4.1/3.xlsx‘,‘data‘,0) #%% # coding UTF-8 from pandas import DataFrame df4 = read_table(‘/Volumes/CHASESKY/python/03-数据分析与数据挖掘篇/1-数据分析数据可视化实战-(Python3.5)/章节4数据处理/4/4.1/中文.txt‘, sep=‘,‘, encoding=‘UTF-8‘) #%% df5 = DataFrame({ ‘age‘: [21, 22, 23], ‘name‘: [‘KEN‘, ‘John‘, ‘JIMI‘] }); df5.to_csv("/Volumes/CHASESKY/python/03-数据分析与数据挖掘篇/1-数据分析数据可视化实战-(Python3.5)/章节4数据处理/4/4.2/df123456.csv"); #%% df5.to_csv("/Volumes/CHASESKY/python/03-数据分析与数据挖掘篇/1-数据分析数据可视化实战-(Python3.5)/章节4数据处理/4/4.2/df56789.csv", index=False)
(1)数据清洗
drop_duplicates() 处理重复值,行相同的数据只保留一行
from pandas import Series from pandas import DataFrame from pandas import read_csv import pandas import numpy #%% df6 = read_csv(‘/Volumes/CHASESKY/python/03-数据分析与数据挖掘篇/1-数据分析数据可视化实战-(Python3.5)/章节4数据处理/4/4.3/data.csv‘) newDF = df6.drop_duplicates() #重复数据 删除重复数据
dropna() 去除数据结构中值为空的数据
df7 = read_csv(‘/Volumes/CHASESKY/python/03-数据分析与数据挖掘篇/1-数据分析数据可视化实战-(Python3.5)/章节4数据处理/4/4.4/data.csv‘)#%% newDF2 = df7.dropna() # 缺失数据处理 是删掉
缺失值的产生: 有些信息暂时无法获取,有些信息被遗漏或者错误处理
缺失值的处理方式: 数据补齐,删除对应缺失行,不处理
(3)数据加工
slice(start,stop) 字段抽取,相当于切片
#4.6字段抽取 df = read_csv("/Volumes/CHASESKY/python/03-数据分析与数据挖掘篇/1-数据分析数据可视化实战-(Python3.5)/章节4数据处理/4/4.6//data.csv") df[‘tel‘] = df[‘tel‘].astype(str) # 原本是数字形式,转换成字符形式 #运营商 bands = df[‘tel‘].str.slice(0, 3) df[‘bands‘]=bands #地区 areas = df[‘tel‘].str.slice(3, 7) df[‘areas‘]=areas #号码段 nums = df[‘tel‘].str.slice(7, 11) df[‘nums‘]=nums
split(sep,n,expand=False) 字段拆分,sep:分隔符,n:分割次数,expand=true 返回dataframe, = flase 返回series
#4.7 字段拆分 df1 = read_csv("/Volumes/CHASESKY/python/03-数据分析与数据挖掘篇/1-数据分析数据可视化实战-(Python3.5)/章节4数据处理/4/4.7/data.csv") newDF = df1[‘name‘].str.split(‘ ‘, 1, True) newDF.columns = [‘band‘, ‘name‘]
str.strip() 去掉空格
df8 = read_csv(‘/Volumes/CHASESKY/python/03-数据分析与数据挖掘篇/1-数据分析数据可视化实战-(Python3.5)/章节4数据处理/4/4.5//data.csv‘) newName3 = df8[‘name‘].str.strip() # 去掉左右空格 输出series df8[‘name‘] = newName3 # 再替换进去
dataframe[过滤条件] 记录抽取,根据一定的条件对数据进行抽取 返回dataframe
df.[pandas.isnull(df.title)]
df.[df.comments.between(1000,10000)]
df = read_csv("/Volumes/CHASESKY/python/03-数据分析与数据挖掘篇/1-数据分析数据可视化实战-(Python3.5)/章节4数据处理/4//4.8//data.csv", sep="|") print(df[df.comments>10000]) print(df[df.comments.between(1000, 10000)]) print(df[pandas.isnull(df.title)]) print(df[df.title.str.contains(‘台电‘, na=False)]) print(df[(df.comments>=1000) & (df.comments<=10000)])
isnull() 空值匹配
str.contains(pattern, na = false) df[df.title.str.contains(‘台电‘,na=False)]
concat([dataFrame1, dataFrame2,....) 记录合并
df1 = read_csv("/Volumes/CHASESKY/python/03-数据分析与数据挖掘篇/1-数据分析数据可视化实战-(Python3.5)/章节4数据处理/4//4.10//data1.csv", sep="|") df2 = read_csv("/Volumes/CHASESKY/python/03-数据分析与数据挖掘篇/1-数据分析数据可视化实战-(Python3.5)/章节4数据处理/4//4.10//data2.csv", sep="|") df3 = read_csv("/Volumes/CHASESKY/python/03-数据分析与数据挖掘篇/1-数据分析数据可视化实战-(Python3.5)/章节4数据处理/4//4.10//data3.csv", sep="|") df = pandas.concat([df1, df2, df3])
+ 字符合并 合并后产生Series
df = read_csv( "/Volumes/CHASESKY/python/03-数据分析与数据挖掘篇/1-数据分析数据可视化实战-(Python3.5)/章节4数据处理/4//4.11//data.csv", sep=" ", names=[‘band‘, ‘area‘, ‘num‘] ) df = df.astype(str) tel = df[‘band‘] + df[‘area‘] + df[‘num‘] df[‘tel‘]=tel
pandas.merge(表1,表2,表1用于匹配的列,表2 用于匹配的列) 字段匹配 类似于 联结
items = read_csv( "/Volumes/CHASESKY/python/03-数据分析与数据挖掘篇/1-数据分析数据可视化实战-(Python3.5)/章节4数据处理/4//4.12//data1.csv", sep=‘|‘, names=[‘id‘, ‘comments‘, ‘title‘] ) prices = read_csv( "/Volumes/CHASESKY/python/03-数据分析与数据挖掘篇/1-数据分析数据可视化实战-(Python3.5)/章节4数据处理/4//4.12//data2.csv", sep=‘|‘, names=[‘id‘, ‘oldPrice‘, ‘nowPrice‘] ) itemPrices = pandas.merge( items, prices, left_on=‘id‘, right_on=‘id‘ )
数据标准化
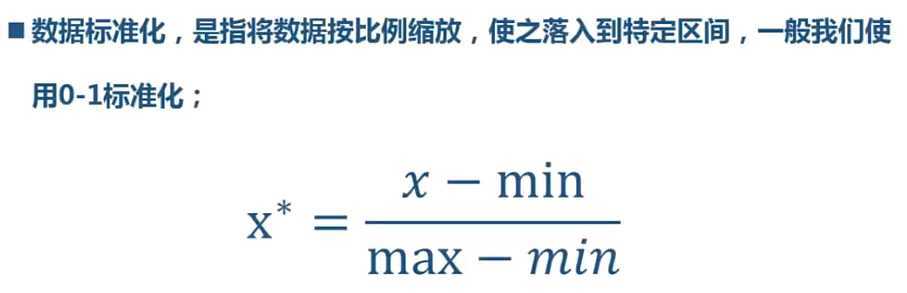
scale = (df.score-df.score.min())/(df.score.max()-df.score.min())
cut(series,bins,right=True,labels=Null) 需要分组的数据/分组的划分数组/分组的时候,右边是否闭合/分组的自定义标签,可以不自定义
df = read_csv("/Volumes/CHASESKY/python/03-数据分析与数据挖掘篇/1-数据分析数据可视化实战-(Python3.5)/章节4数据处理/4//4.15//data.csv", sep=‘|‘) bins = [min(df.cost)-1, 20, 40, 60, 80, 100, max(df.cost)+1] labels = [‘20以下‘, ‘20到40‘, ‘40到60‘, ‘60到80‘, ‘80到100‘, ‘100以上‘] print(pandas.cut(df.cost, bins)) print(pandas.cut(df.cost, bins, right=False)) print(pandas.cut(df.cost, bins, right=False, labels=labels)) df[‘series‘] = pandas.cut(df.cost, bins, right=False, labels=labels)
date = to_datetime(dateString,format) 字符型转日期型
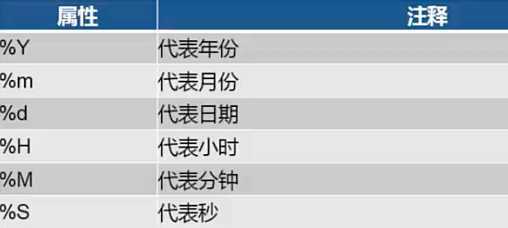
from pandas import to_datetime#%% df = read_csv("/Volumes/CHASESKY/python/03-数据分析与数据挖掘篇/1-数据分析数据可视化实战-(Python3.5)/章节4数据处理/4//4.16//data.csv", encoding=‘utf8‘) df_dt = to_datetime(df.注册时间, format=‘%Y/%m/%d‘)
apply(lambda x:处理逻辑) datetime.strftime(x,format)
from datetime import datetime#%% df_dt_str = df_dt.apply(lambda x: datetime.strftime(x, ‘%d-%m-%Y‘))
dt.property property 是指 second minute hour day month year weekday
print(df_dt.dt.year) print(df_dt.dt.second) print(df_dt.dt.minute)
(3)数据抽样
numpy.random.randint(start,end,num) 随机抽样
df = read_csv("/Volumes/CHASESKY/python/03-数据分析与数据挖掘篇/1-数据分析数据可视化实战-(Python3.5)/章节4数据处理/4//4.9//data.csv")
r = numpy.random.randint(0, 10, 3)
df1=df.loc[r, :]
NUMPY
生成等差数列:
numpy.arange(start,end,step):
import numpy r = numpy.arange(0.1, 0.5, 0.01) #range() 不能生成小数范围的
numpy.power(a,b) a的元素的b次方 向量化运算
numpy.dot(r, r.T) 进行矩阵运算
numpy.all(判断标准 ) 对矩阵的所有元素进行判断
numpy.random.randint(start,end,num) 开始值,结束值,抽样个数 行数的索引值序列
原文:https://www.cnblogs.com/adelinebao/p/13341766.html