java爬虫学习webmagic爬取前程无忧职位信息遇到的一些问题记录一下
1.使用爬取页面跑出"TLSv1.3"不支持异常
由于webmagic作者长期没有发布0.74版本,所以只能手动解决
下载webmagic-core源码,去除"TLSv1.3",在忽视测试在install,即可爬取页面
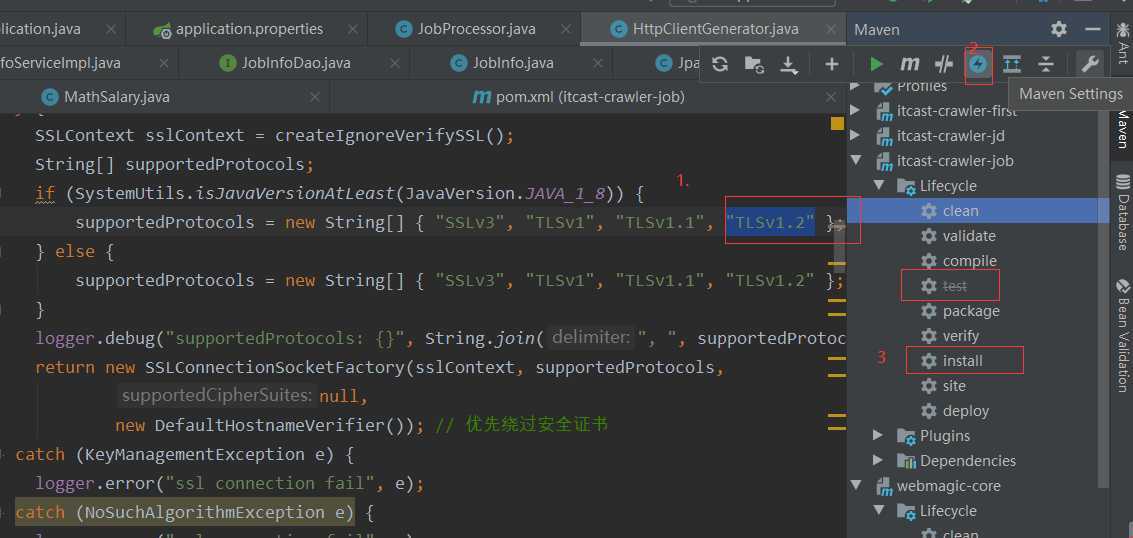
2.问题如下
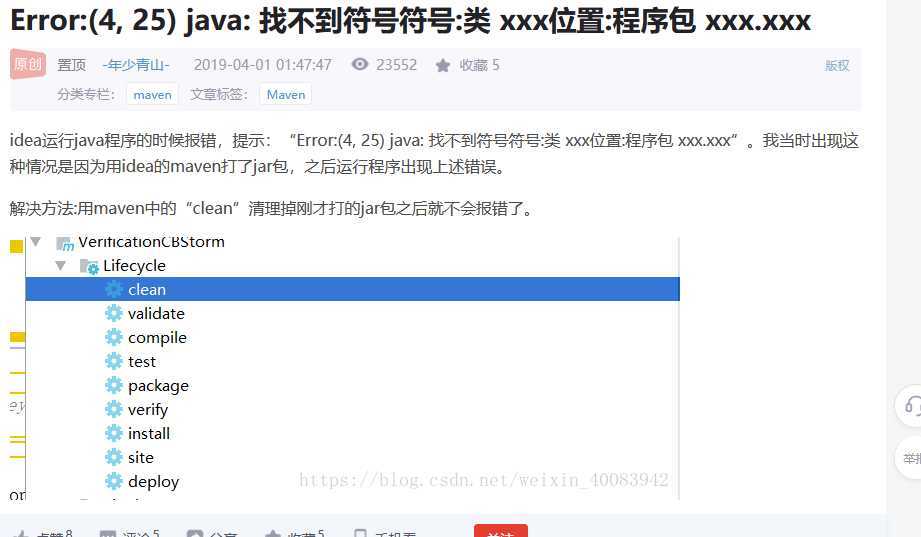
3.因为之前用的1.7的编译版本,改成1.8导致idea 版本报错:Error:java: Compilation failed: internal java compiler error 解决办法
报错原因:
项目中Java版本不一致,可以查看项目中的jdk配置
1、查看项目的jdk(Ctrl+Alt+shift+S)
File ->Project Structure->Project Settings ->Project
2、查看工程的jdk(Ctrl+Alt+shift+S)
File ->Project Structure->Project Settings -> Modules -> (需要修改的工程名称) -> Sources ->
3、查看idea中Java配置
File-->Other Settings-->Default Settings-->Compiler-->Java Compiler
如果出现的Choose Module框中是空白,无法修改Target bytecode version.则:
选中项目,右击选择Maven-->Reimport, 然后再次编译,问题解决。
爬取前程无忧职位使用的是webmagic,项目搭建使用的是springboot,springdatajpa,当然也可以使用mybatis
主要代码如下
1.JobInfoServiceImpl 业务实现
@Service public class JobInfoServiceImpl implements JobInfoService { @Autowired private JobInfoDao jobInfoDao; @Override @Transactional public void save(JobInfo jobInfo) { //先从数据库查询数据,根据发布日期查询和url查询 JobInfo param = new JobInfo(); param.setUrl(jobInfo.getUrl()); param.setTime(jobInfo.getTime()); List<JobInfo> list = this.findJobInfo(param); if (list.size() == 0) { //没有查询到数据则新增或者修改数据 jobInfoDao.saveAndFlush(jobInfo); } } @Override public List<JobInfo> findJobInfo(JobInfo jobInfo) { Example example = Example.of(jobInfo); List<JobInfo> list = jobInfoDao.findAll(example); return list; } }
2.JpaPipeline 实现爬取信息存储到数据库
@Component public class JpaPipeline implements Pipeline { @Autowired private JobInfoService jobInfoService; @Override public void process(ResultItems resultItems, Task task) { JobInfo jobInfo = resultItems.get("jobInfo"); if(jobInfo!=null){ jobInfoService.save(jobInfo); } } }
3.JobProcessor 页面爬取实现
@Component public class JobProcessor implements PageProcessor { private String url="https://search.51job.com/list/000000,000000,0000,01%252C32,9,99,java,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare="; @Override public void process(Page page) { //解析页面,获取招聘信息详情的url地址 List<Selectable> list = page.getHtml().css("div#resultList div.el").nodes(); //判断获取到的集合是否为空 if (list.size() == 0) { // 如果为空,表示这是招聘详情页,解析页面,获取招聘详情信息,保存数据 this.saveJobInfo(page); } else { //如果不为空,表示这是列表页,解析出详情页的url地址,放到任务队列中 for (Selectable selectable : list) { //获取url地址 String jobInfoUrl = selectable.links().toString(); //把获取到的url地址放到任务队列中 page.addTargetRequest(jobInfoUrl); } //获取下一页的url String bkUrl = page.getHtml().css("div.p_in li.bk").nodes().get(1).links().toString(); //把url放到任务队列中 page.addTargetRequest(bkUrl); } } //解析页面,获取招聘详情信息,保存数据 private void saveJobInfo(Page page) { //创建招聘详情对象 JobInfo jobInfo = new JobInfo(); //解析页面 Html html = page.getHtml(); // //获取数据,封装到对象中 jobInfo.setCompanyName(html.css("div.cn p.cname a","text").toString()); jobInfo.setCompanyAddr(Jsoup.parse(html.css("div.bmsg").nodes().get(1).toString()).text()); jobInfo.setCompanyInfo(Jsoup.parse(html.css("div.tmsg").toString()).text()); jobInfo.setJobName(html.css("div.cn h1","text").toString()); String[] msgs = html.css("div.tHeader div.cn p.msg", "title").toString().split("\\|"); jobInfo.setJobAddr(msgs[0].trim()); jobInfo.setJobInfo(Jsoup.parse(html.css("div.job_msg").toString()).text()); jobInfo.setUrl(page.getUrl().toString()); //获取薪资 Integer[] salary = MathSalary.getSalary(html.css("div.tHeader div.cn strong", "text").toString()); jobInfo.setSalaryMax(salary[1]); jobInfo.setSalaryMin(salary[0]); //获取发布时间 //处理发布时间 String time = null; for (String msg : msgs) { if (msg.contains("发布")) { time = msg.trim().substring(0, msg.length() - 2).trim(); break; } } if (time == null) { time = "未知"; } jobInfo.setTime(time); //把结果保存起来 page.putField("jobInfo",jobInfo); } private Site site = Site.me() .setCharset("gbk")//设置编码 .setTimeOut(10 * 1000)//设置超时时间 .setRetrySleepTime(3000)//设置重试的间隔时间 .setRetryTimes(3);//设置重试的次数 @Autowired private JpaPipeline jpaPipeline; @Override public Site getSite() { return site; } //initialDelay 任务启动后多久执行方法 fixedDelay 间隔多久再执行方法 @Scheduled(initialDelay = 1000,fixedDelay = 100*1000) public void process(){ Spider.create(new JobProcessor()) .addUrl(url) .setScheduler(new QueueScheduler().setDuplicateRemover(new BloomFilterDuplicateRemover(100000))) .thread(5) .addPipeline(jpaPipeline) .run(); } }
其他接口和pojo,工具类自行查找
解决bug即可运行得到信息
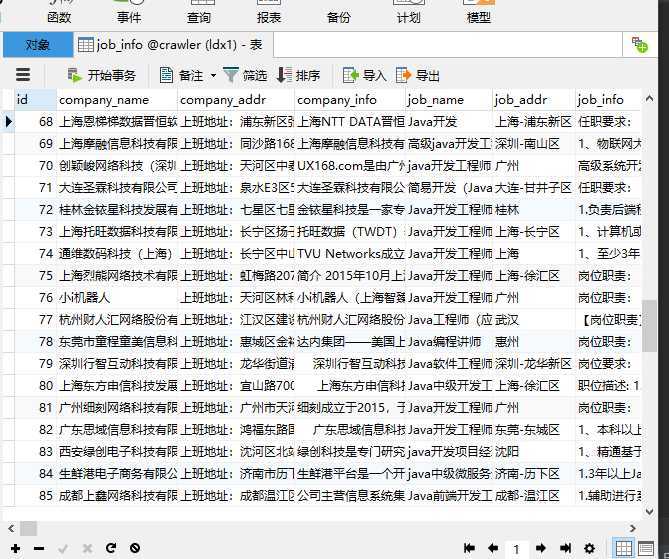
原文:https://www.cnblogs.com/snax/p/13345458.html