public class Test {
public void test() {
String str1 = "abc";
String str2 = new String("abc");
System.out.println(str1 == str2); //false
String str3 = new String("abc");
System.out.println(str3 == str2); //false
String str4 = "a" + "b";
System.out.println(str4 == "ab"); true
final String s = "a";
String str5 = s + "b";
System.out.println(str5 == "ab"); true
String s1 = "a";
String s2 = "b";
String str6 = s1 + s2;
System.out.println(str6 == "ab"); //false
String str7 = "abc".substring(0,2);
System.out.println(str7 == "ab"); false
String str8 = "abc".toUpperCase();
System.out.println(str8 == "ABC"); false
String s3 = "abc";
String s4 = "ab" + getString();
System.out.println(s3 == s4); //false
String s5 = "a";
String s6 = "abc";
String s7 = s5 + "bc";
System.out.println(s6 == s7.intern()); //true
}
private String getString(){
return "c";
}
}
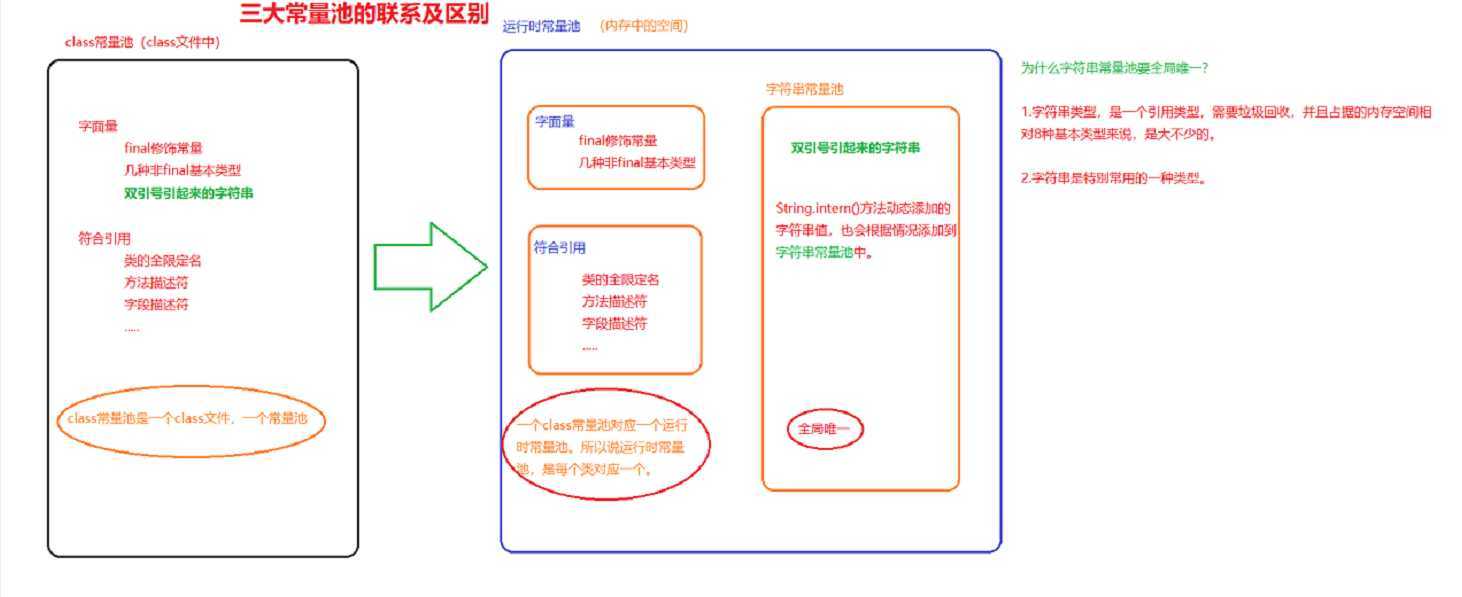
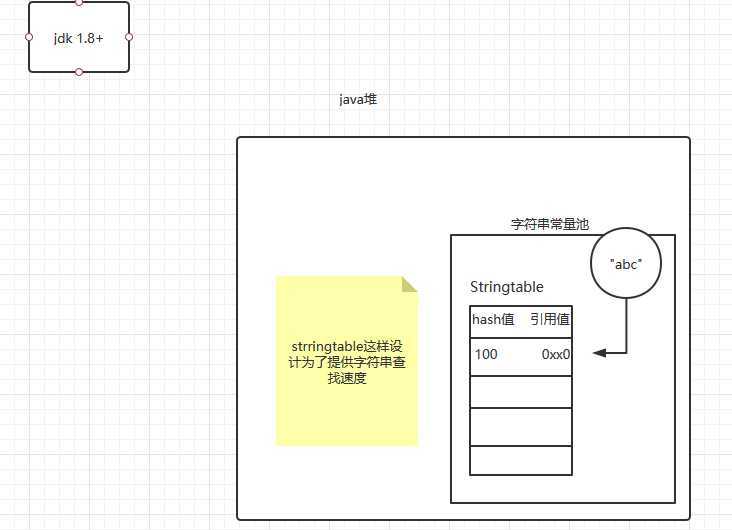
String的Intern方法详解
String a = "hello";
String b = new String("hello");
System.out.println(a == b); //false
String c = "world";
System.out.println(c.intern() == c); //true
String d = new String("mike");
System.out.println(d.intern() == d); //false
String e = new String("jo") + new String("hn"); newString("john") -->不会放到常量池。
System.out.println(e.intern() == e); //true --->intern 将字符串放到常量池中。
String f = new String("ja") + new String("va");
System.out.println(f.intern() == f); //false (java关键字 字符串在编译器就放入常量池中)
intern的作用是把new出来的字符串的引用添加到stringtable中,java会先计算string的hashcode,查找stringtable中是否已经有string对应的引用了,如果有返回引用(地址),然后没有把字符串的地址
放到stringtable中,并返回字符串的引用(地址)。

public static void main(String[] args) {
String s = new String("1");
s.intern();
String s2 = "1";
System.out.println(s == s2); //false
String s3 = new String("1") + new String("1");
s3.intern();
String s4 = "11";
System.out.println(s3 == s4); jdk1.6 false jdk1.7+ true
}
2.Java堆
Java堆中,主要是用来存储对象和数组的。
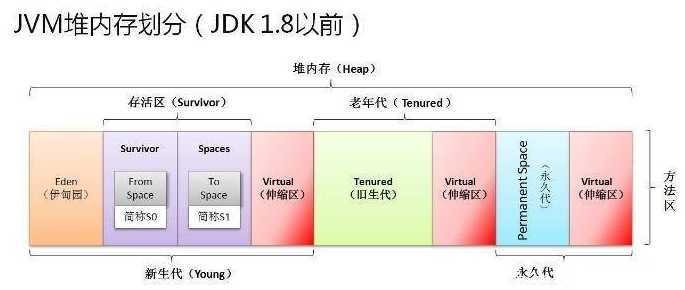
堆内存划分
堆被划分为老年代和年轻代。
年轻代和老年代的内存占比默认为1:2。
年轻代又划分为:伊甸园(Eden)、两个幸存区(Survivor)
伊甸园和两个幸存区的内存占比默认为8:1:1。
之所以我们堆内存要进行以上这么细粒度的内存划分,是为了垃圾回收。
垃圾回收针对不同情况的对象,回收策略(回收算法)是不同的的。而通过内存的划分,可以将不同的
算法在不同的区域中进行使用。
比如说年轻代使用了复制算法。
年轻代中的对象,生命周期很短,基本上是很快就死了,也就是被GC了。
老年代中的对象,都是一些老顽固,都是多次回收的对象或者大对象才存到老年代中。
内存的分配原则
优先在Eden分配,如果Eden空间不足虚拟机则会进行一次MinorGC
大对象直接进入老年代{大对象一般是 很长的字符串或数组}
长期存活的对象也会进入老年代,每个对象都有一个age,当age达到设定的年纪的时间就会进入老年代。默认是15.
内存分配安全问题
在分配内存的同时,存在线程安全的问题,即虚拟机给A线程分配内存过程中,指针未修改,B线程可能同时使用了同样一块内存。
在JVM中有两种解决办法:
1. CAS,比较和交换(Compare And Swap): CAS 是乐观锁的一种实现方式。所谓乐观锁就是,每次不加锁而是假设没有冲突而去完成某项操作,如果因为冲突失败就重试,直到成功为止。虚拟机采用 CAS 配上失败重试的方式保证更新操作的原子性。
2. TLAB,本地线程分配缓冲(Thread Local Allocation Buffffer即TLAB): 为每一个线程预先分配一块内存,JVM在给线程中的对象分配内存时,首先在TLAB分配,当对象大于TLAB中的剩余内存或TLAB的内存已用尽时,再采用上述的CAS进行内存分配。
对象的内存布局
普通对象在内存中存储的布局可以分为4块区域:
对象头(Header 在hotport称为markword 长度8个字节)
ClassPointer 指针:--xx:+UseCompressedClassPointers 为4个字节 ,若不开启压缩 为8个字节
实例数据(Instance Data)引用类型: -XX:UseCompressedOops 开启压缩为4个字节,不开启为8个字节。
对齐填充(Padding) 这个对齐是8的倍数。
数组对象在内存中存储的布局可以分为4块区域:
对象头(Header 在hotport称为markword 长度8个字节)
ClassPointer 指针:--xx:+UseCompressedClassPointers 为4个字节 ,若不开启压缩 为8个字节 。
数组长度:4个字节。
实例数据(Instance Data)引用类型: -XX:UseCompressedOops 开启压缩为4个字节,不开启为8个字节。
对齐填充(Padding) 这个对齐是8的倍数。
对象头具体包含:(JDK1.8)32位
对象定位
1.句柄池 :稳定,对象被移动只需要修改句柄中的地址。
2.直接指针:指向对象然后指向class,访问速度快。