先上一张搜索来的图。
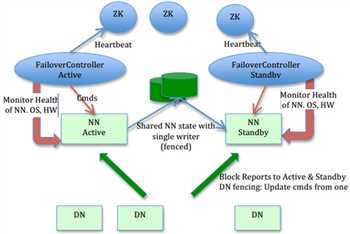
如上图,HDFS的高可用其实就是NameNode的高可用。
上一篇里,SecondaryNameNode是NameNode单节点部署才会有的角色,它只帮助NameNode完成日志合并的工作,在NameNode出现问题时不能顶上去。
在高可用里,不再有SecondaryNameNode这个角色,Hadoop2.x版本支持NameNode的一主一从,3.x版本支持一主多从,由从NameNode完成日志合并任务。
总结一下,在一个高可用的HDFS集群里,至少需要这么几个角色:
为了实现NameNode的自动切换,还需要这两个角色:
未完待续
原文:https://www.cnblogs.com/burningblade/p/13349079.html