Executor 框架是 Java5 之后引进的,在 Java 5 之后,通过 Executor 来启动线程比使用 Thread 的 start 方法更好,除了更易管理,效率更好(用线程池实现,节约开销)外,还有关键的一点:有助于避免 this 逃逸问题。
补充:this 逃逸是指在构造函数返回之前其他线程就持有该对象的引用. 调用尚未构造完全的对象的方法可能引发令人疑惑的错误。
Executor 框架不仅包括了线程池的管理,还提供了线程工厂、队列以及拒绝策略等,Executor 框架让并发编程变得更加简单。
Runnable /Callable)执行任务需要实现的 Runnable 接口 或 Callable接口。Runnable 接口或 Callable 接口 实现类都可以被 ThreadPoolExecutor 或 ScheduledThreadPoolExecutor 执行。
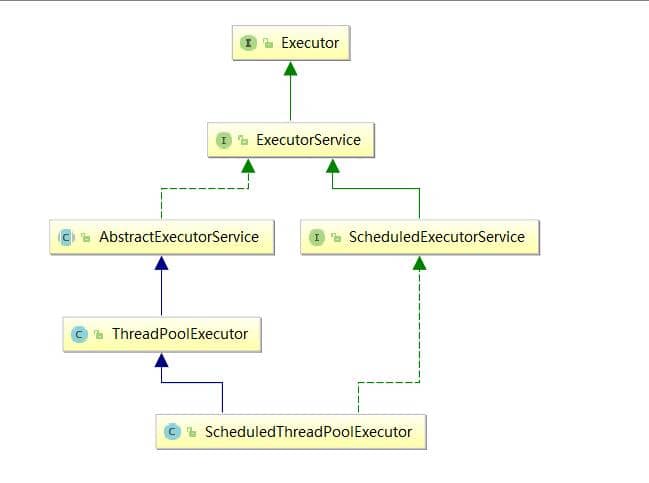
Executor)如下图所示,包括任务执行机制的核心接口 Executor ,以及继承自 Executor 接口的 ExecutorService 接口。ThreadPoolExecutor 和 ScheduledThreadPoolExecutor 这两个关键类实现了 ExecutorService 接口。
这里提了很多底层的类关系,但是,实际上我们需要更多关注的是 ThreadPoolExecutor 这个类,这个类在我们实际使用线程池的过程中,使用频率还是非常高的。
注意: 通过查看
ScheduledThreadPoolExecutor源代码我们发现ScheduledThreadPoolExecutor实际上是继承了ThreadPoolExecutor并实现了 ScheduledExecutorService ,而ScheduledExecutorService又实现了ExecutorService,正如我们下面给出的类关系图显示的一样。
ThreadPoolExecutor 类描述:
//AbstractExecutorService实现了ExecutorService接口 public class ThreadPoolExecutor extends AbstractExecutorService
ScheduledThreadPoolExecutor 类描述:
//ScheduledExecutorService实现了ExecutorService接口 public class ScheduledThreadPoolExecutor extends ThreadPoolExecutor implements ScheduledExecutorService

Future)Future 接口以及 Future 接口的实现类 FutureTask 类都可以代表异步计算的结果。
当我们把 Runnable接口 或 Callable 接口 的实现类提交给 ThreadPoolExecutor 或 ScheduledThreadPoolExecutor 执行。(调用 submit() 方法时会返回一个 FutureTask 对象)
Runnable 或者 Callable 接口的任务对象。Runnable/Callable接口的 对象直接交给 ExecutorService 执行: ExecutorService.execute(Runnable command))或者也可以把 Runnable 对象或Callable 对象提交给 ExecutorService 执行(ExecutorService.submit(Runnable task)或 ExecutorService.submit(Callable <T> task))。ExecutorService.submit(…),ExecutorService 将返回一个实现Future接口的对象(我们刚刚也提到过了执行 execute()方法和 submit()方法的区别,submit()会返回一个 FutureTask 对象)。由于 FutureTask 实现了 Runnable,我们也可以创建 FutureTask,然后直接交给 ExecutorService 执行。FutureTask.get()方法来等待任务执行完成。主线程也可以执行 FutureTask.cancel(boolean mayInterruptIfRunning)来取消此任务的执行。线程池实现类 ThreadPoolExecutor 是 Executor 框架最核心的类。
ThreadPoolExecutor 类中提供的四个构造方法。我们来看最长的那个,其余三个都是在这个构造方法的基础上产生(其他几个构造方法说白点都是给定某些默认参数的构造方法比如默认制定拒绝策略是什么),这里就不贴代码讲了,比较简单。
/** * 用给定的初始参数创建一个新的ThreadPoolExecutor。 */ public ThreadPoolExecutor(int corePoolSize,//线程池的核心线程数量 int maximumPoolSize,//线程池的最大线程数 long keepAliveTime,//当线程数大于核心线程数时,多余的空闲线程存活的最长时间 TimeUnit unit,//时间单位 BlockingQueue<Runnable> workQueue,//任务队列,用来储存等待执行任务的队列 ThreadFactory threadFactory,//线程工厂,用来创建线程,一般默认即可 RejectedExecutionHandler handler//拒绝策略,当提交的任务过多而不能及时处理时,我们可以定制策略来处理任务 ) { if (corePoolSize < 0 || maximumPoolSize <= 0 || maximumPoolSize < corePoolSize || keepAliveTime < 0) throw new IllegalArgumentException(); if (workQueue == null || threadFactory == null || handler == null) throw new NullPointerException(); this.corePoolSize = corePoolSize; this.maximumPoolSize = maximumPoolSize; this.workQueue = workQueue; this.keepAliveTime = unit.toNanos(keepAliveTime); this.threadFactory = threadFactory; this.handler = handler; }
下面这些对创建 非常重要,在后面使用线程池的过程中你一定会用到!所以,务必拿着小本本记清楚。
ThreadPoolExecutor 3 个最重要的参数:
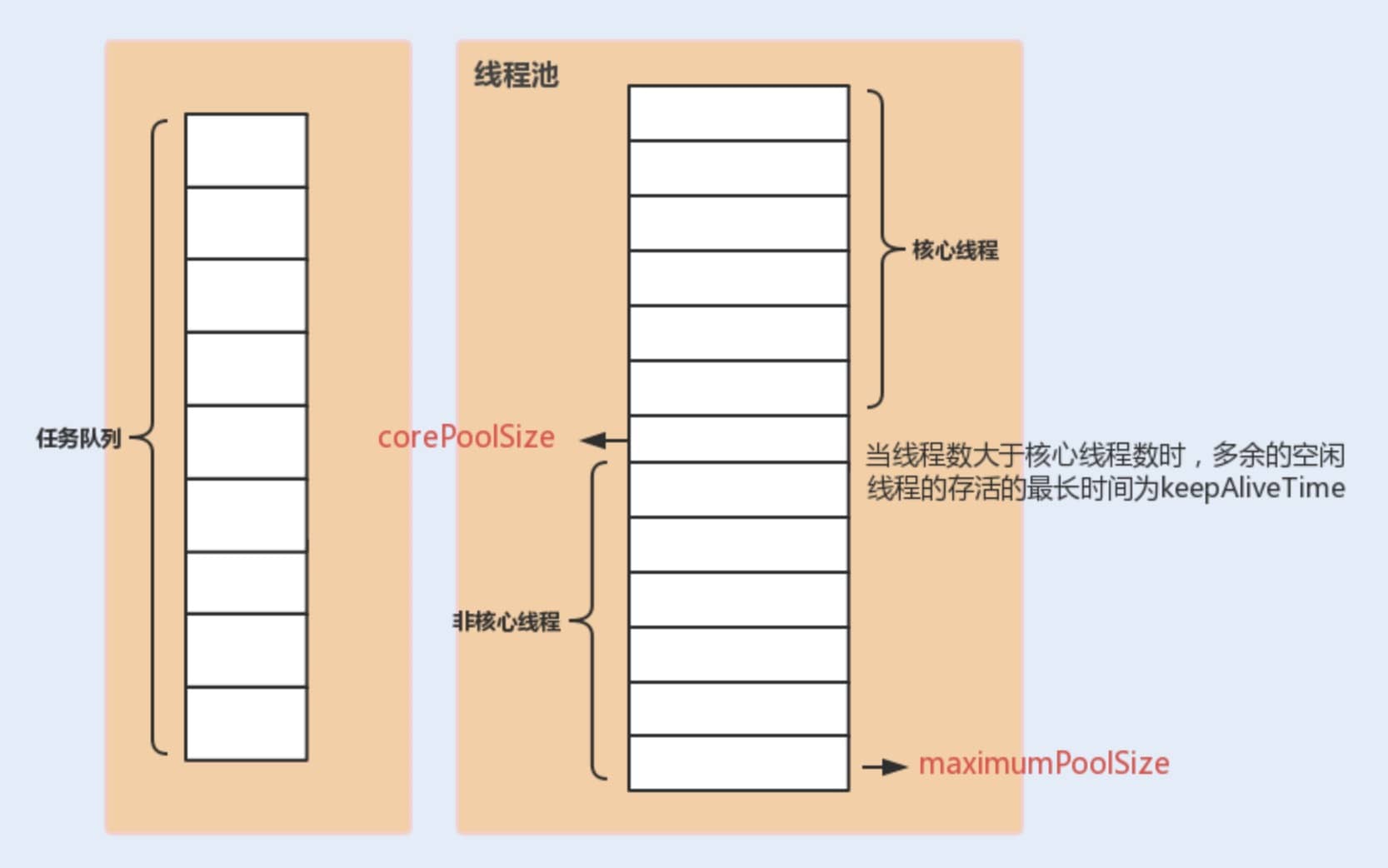
corePoolSize : 核心线程数线程数定义了最小可以同时运行的线程数量。maximumPoolSize : 当队列中存放的任务达到队列容量的时候,当前可以同时运行的线程数量变为最大线程数。workQueue: 当新任务来的时候会先判断当前运行的线程数量是否达到核心线程数,如果达到的话,信任就会被存放在队列中。ThreadPoolExecutor其他常见参数:
keepAliveTime:当线程池中的线程数量大于 corePoolSize 的时候,如果这时没有新的任务提交,核心线程外的线程不会立即销毁,而是会等待,直到等待的时间超过了 keepAliveTime才会被回收销毁;unit : keepAliveTime 参数的时间单位。threadFactory :executor 创建新线程的时候会用到。handler :饱和策略。关于饱和策略下面单独介绍一下。下面这张图可以加深你对线程池中各个参数的相互关系的理解(图片来源:《Java 性能调优实战》):
原文:https://www.cnblogs.com/xiaomaoyvtou/p/13357137.html