一、数据集
竞赛数据集:pandas
大数据:spark
二、评估:多分类问题的机器学习竞赛常常将F1-score作为最终的测评方法。
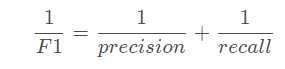

其中:
TP(True Positive):正样本预测为正样本的个数
FP(True Positive):将负样本预测为正样本的个数
FN(True Positive):将正样本预测为负样本的个数
三、解题思路
赛题思路分析
本质是一个文本分类问题,需要根据每句的字符进行分类。但赛题给出的数据是匿名化的,不能直接使用中文分词等操作,这个是赛题的难点。因此本次赛题的难点是需要对匿名字符进行建模,进而完成文本分类的过程。由于文本数据是一种典型的非结构化数据,因此可能涉及到特征提取和分类模型两个部分。进行分类可通过四种方法:
原文:https://www.cnblogs.com/yuyunfei/p/13358012.html