引用自:http://jalammar.github.io/a-visual-guide-to-using-bert-for-the-first-time/

在过去的几年中,用于处理语言的机器学习模型正在迅速加速发展。这一进展已经离开了研究实验室,并开始为一些领先的数字产品提供动力。一个很好的例子就是最近宣布的BERT模型如何成为Google搜索背后的主要力量。Google相信这一步骤(或在搜索中应用自然语言理解的进步)代表着“过去五年中最大的飞跃,也是搜索历史上最大的飞跃之一”。
这篇文章是有关如何使用BERT的变体对句子进行分类的简单教程。这是一个足够基本的示例,作为第一个介绍,但足够先进,足以展示其中涉及的一些关键概念。
除了这篇文章,我还准备了一个笔记本。您可以在笔记本上看到它,或在colab上运行它。
在此示例中,我们将使用的数据集为SST2,其中包含电影评论中的句子,每个句子都标记为正(值为1)或负(值为0):
| 句子 | 标签 |
|---|---|
| 一部激动人心,有趣而又最终传达出对美与野兽和1930年代恐怖电影的想象 | 1个 |
| 显然是从任何给定的日间肥皂的切割室地板重新组装的 | 0 |
| 他们认为听众不会坐以待so | 0 |
| 这是关于爱情,记忆,历史以及艺术与商业之间战争的视觉上惊人的反省 | 1个 |
| 乔纳森·帕克(Jonathan Parker)的剧作应该是所有现代办公室失范电影的结尾 | 1个 |
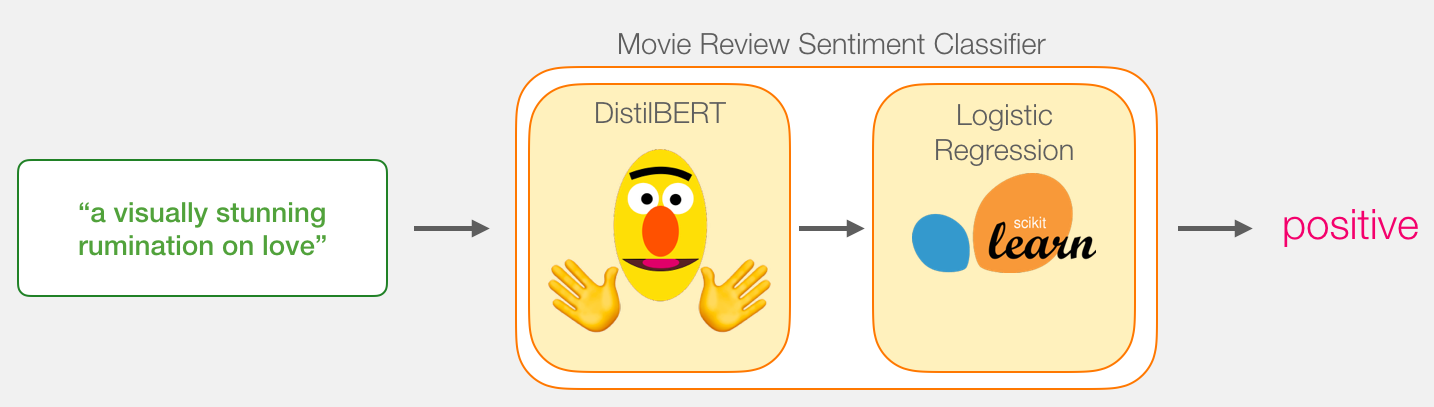
我们的目标是创建一个接受句子的模型(就像数据集中的句子一样),并产生1(指示句子带有正面情绪)或0(指示句子带有负面情绪)。我们可以认为它看起来像这样:

在引擎盖下,模型实际上由两个模型组成。
我们在两个模型之间传递的数据是大小为768的向量。我们可以将此向量视为对可用于分类的句子的嵌入。
如果您已阅读我的上一篇文章Illustrated BERT,则此向量是第一个位置的结果(该位置接收[CLS]令牌作为输入)。
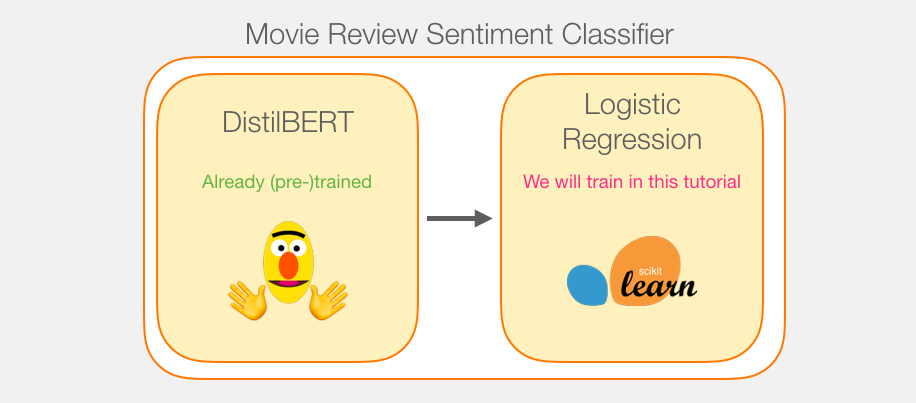
虽然我们将使用两个模型,但我们只会训练逻辑回归模型。对于DistillBERT,我们将使用已经预先训练并掌握英语的模型。但是,这种模型都没有经过训练,没有经过微调来进行句子分类。但是,我们从训练BERT的总体目标中获得了一些句子分类功能。对于第一个位置的BERT输出(与[CLS]令牌相关联),情况尤其如此。我认为这是由于BERT的第二个训练对象–下一个句子的分类。这个目标似乎训练模型将句子范围的意义封装到第一位置的输出。该变压器库为我们提供了DistilBERT的实施以及模型的预训练版本。
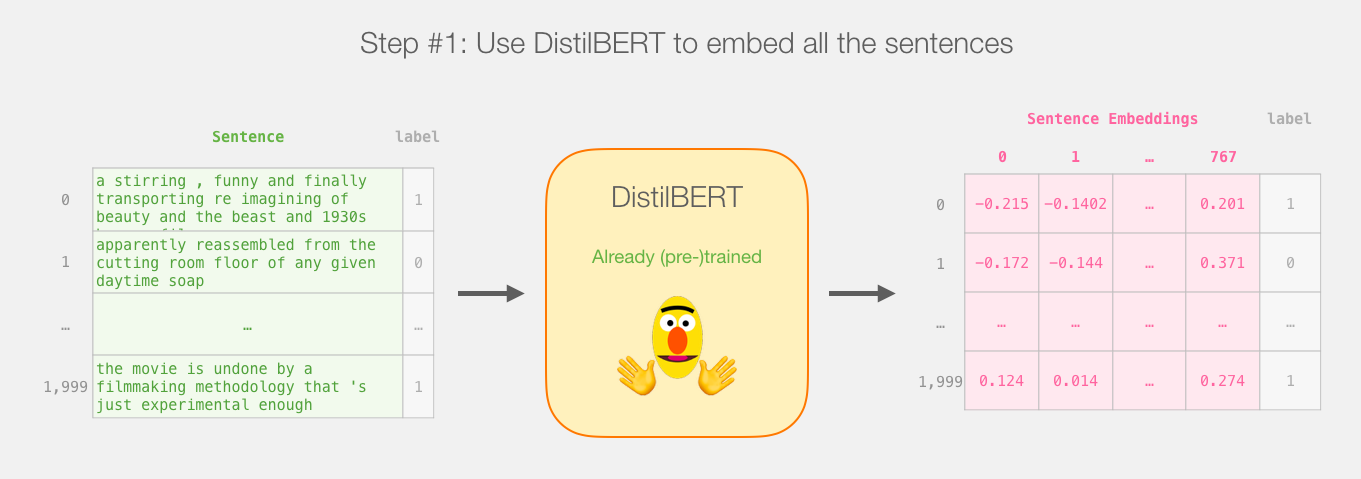
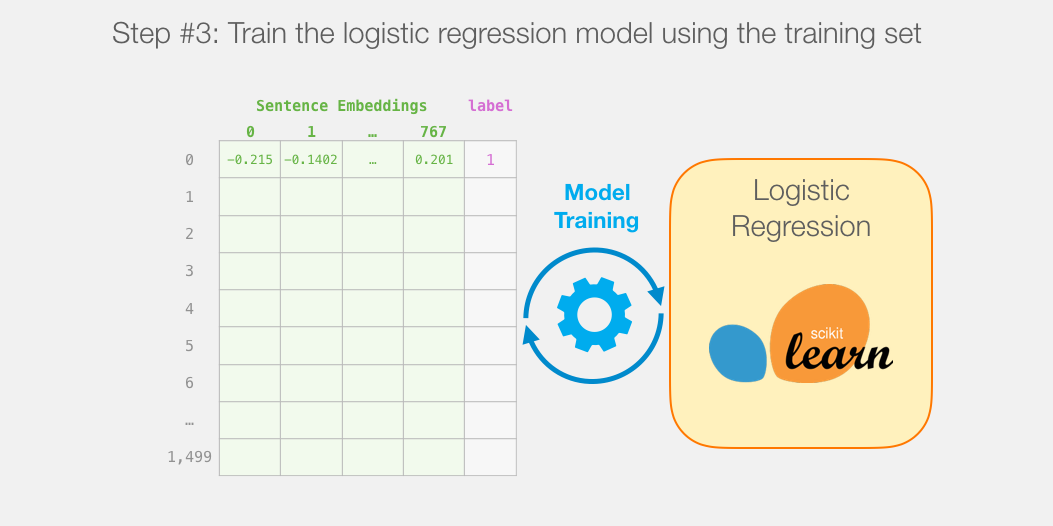
所以这是本教程的游戏计划。我们将首先使用经过训练的distilBERT生成2,000个句子的句子嵌入。
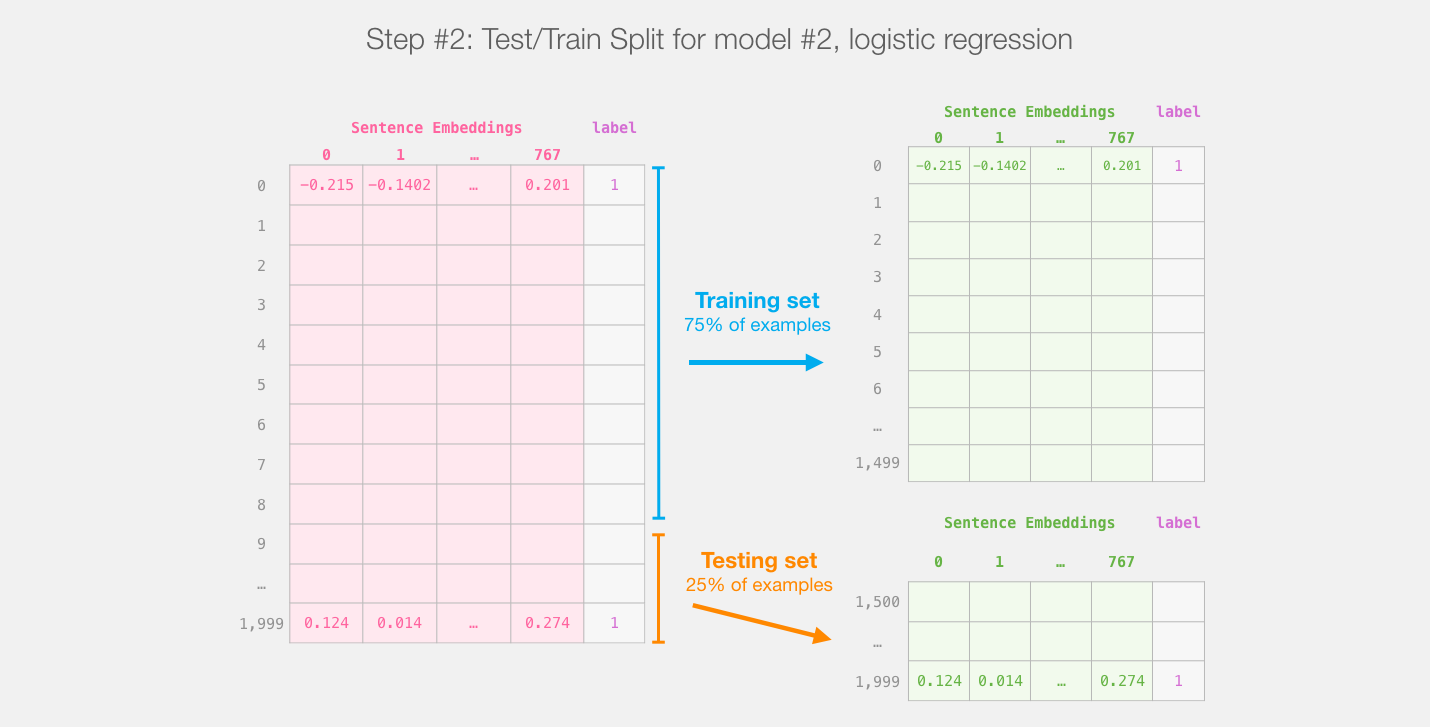
此步骤之后,我们将不再触摸distilBERT。这就是Scikit Learn的全部内容。我们在此数据集上进行常规的训练/测试拆分:
然后我们在训练集上训练逻辑回归模型:
在深入研究代码并解释如何训练模型之前,我们先来看一个训练后的模型如何计算其预测。
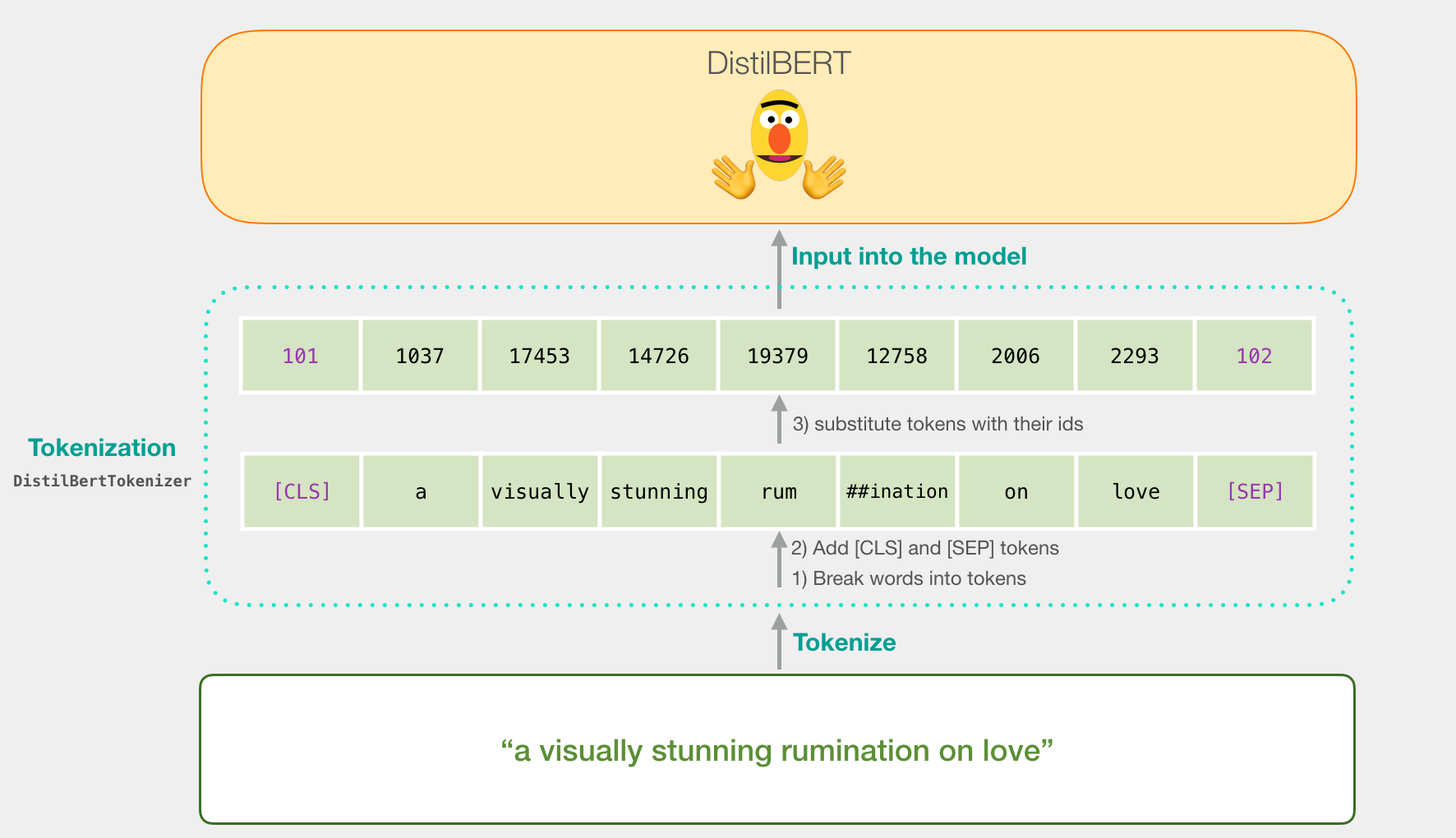
让我们尝试对句子“对爱的视觉上惊人的反省”进行分类。第一步是使用BERT令牌生成器首先将单词拆分为令牌。然后,我们添加句子分类所需的特殊标记(这些标记位于第一个位置的[CLS],位于句子结尾的[SEP])。

令牌化程序执行的第三步是用嵌入表中的令牌替换每个令牌,这是我们通过训练模型获得的组件。阅读说明的Word2vec,了解有关单词嵌入的背景。

请注意,令牌生成器在一行代码中完成所有这些步骤:
tokenizer.encode("a visually stunning rumination on love", add_special_tokens=True)
现在,我们的输入句子是传递给DistilBERT的适当形状。
如果您已阅读Illustrated BERT,则此步骤也可以通过以下方式可视化:
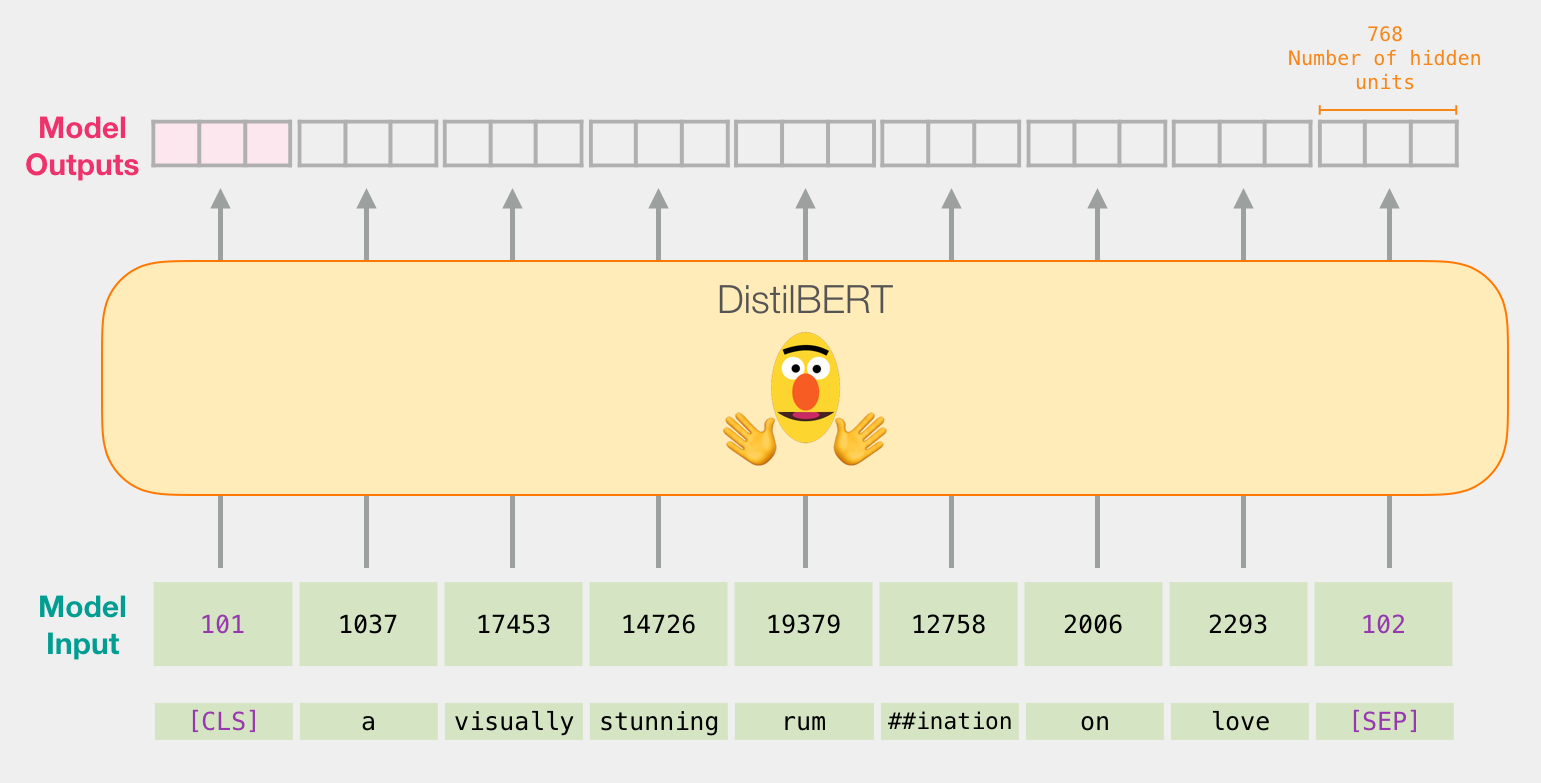
像BERT一样,通过DistilBERT传递输入向量。输出将是每个输入令牌的向量。每个向量由768个数字(浮点数)组成。
因为这是一个句子分类任务,所以我们将忽略除第一个向量(与[CLS]令牌相关联的向量)以外的所有内容。我们传递的一个向量作为逻辑回归模型的输入。
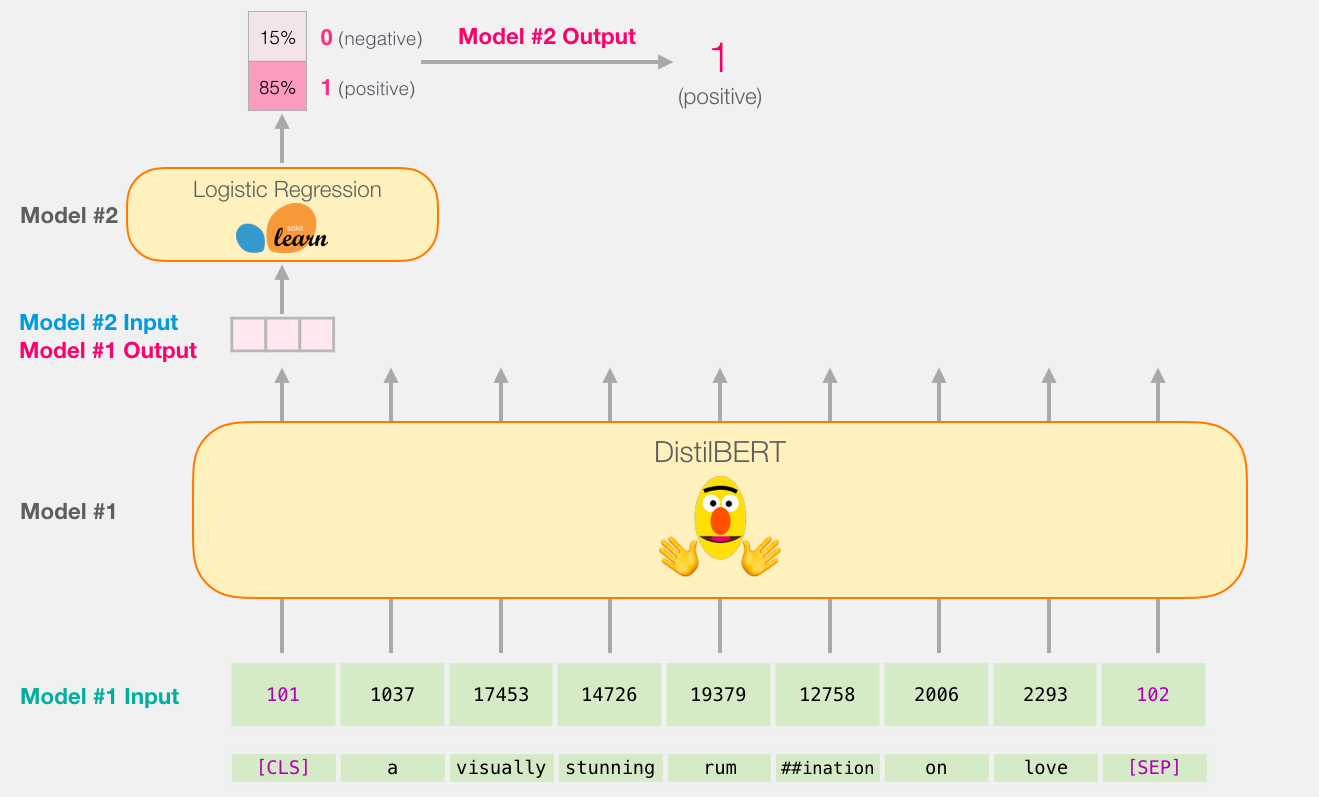
从这里开始,逻辑回归模型的工作就是根据从训练阶段中学到的向量对该向量进行分类。我们可以认为预测计算如下所示:
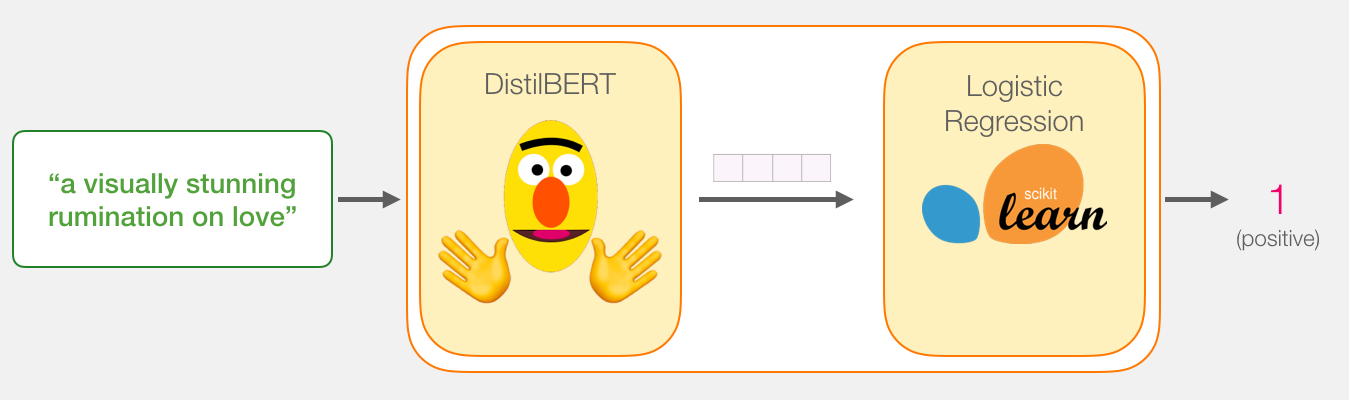
我们将在下一部分中讨论培训内容以及整个过程的代码。
原文:https://www.cnblogs.com/tfknight/p/13359602.html