特性:
1、字符串一旦创建,不可修改
2、一旦修改或者拼接,都会重新生成新字符串
# def replace(self, old, new, count=None) print("***replace替换***") print("jasonjasonjason".replace("a","bb")) # jbbsonjbbsonjbbson print("jasonjasonjason".replace("a","bb",1)) # jbbsonjasonjason print("jasonjasonjason".replace("a","bb",2)) # jbbsonjbbsonjason
# 将单词格式化为:首字母大写 v1 = str1.capitalize() print(v1) # Alex
# 将字符格式化为:全小写 # casefold功能更强大,会将法语等其他语言的字符也全部小写 v2 = str1.casefold() # alex v3 = str1.lower() # alex print(v2) print(v3)
# 转小写 # 判断是否全小写 print("***章节:小写***") print("LaSa".islower()) # False print("LaSa".lower()) # lasa print("LaSa".lower().islower()) # True
# ***章节:大写*** # 转大写 # 判断是否全大写 print("***章节:小写***") print("LaSa".isupper()) # False print("LaSa".upper()) # LASA print("LaSa".upper().isupper()) # True
def center(self, width, fillchar=None) : 居中填充,字符串格式化固定宽度,并居中
width:宽度
fillchar:填充字符,默认为空格
# def center(self, width, fillchar=None) # (居中)格式化固定宽度,并设定填充字符 v4 = str1.center(20, "-") print(v4) # --------aLex--------
ljust(self, width, fillchar=None) 左起,右填充
rjust(self, width, fillchar=None) 右起,左填充
# ljust(self, width, fillchar=None) 左起,右填充 # rjust(self, width, fillchar=None) 右起,左填充 print("填充") print("alex".ljust(20,"*")) # alex**************** print("alex".rjust(20,"*")) # ****************alex
def count(self, sub, start=None, end=None) 从start到end之间,统计子序列总数
# 从start到end之间,统计子序列总数 # sub: 子序列,即子字符串 # start: 起始位置 # end: 结束 string1 = ‘aLEx is a woman, who is a nurse‘ v5 = string1.count(‘is‘) print(v5)
str1 = ‘aLex‘ a = str1.startswith("a") # True print(a) e = str1.endswith("ex") # True print(e)
find
# 从[start,end)找子序列的第一个位置索引 # 无该子序列,则返回-1 test = "alexalex" v = test.find(‘ex‘,0,8) # 2 print(v)
index
# 从[start,end)找子序列的第一个位置索引 # index找不到子序列,则报异常 v1 = test.index(‘ex‘) print(v1)
format(kvargs**)
# 字符串中引用变量:{name}和{num} test = ‘i am {name}, age {num}‘ print(test) # i am {name}, age {num} # 为字符串中变量赋值 v = test.format(name=‘alex‘, num=19) print(v) # i am alex, age 19
format(args**)
format_map(mapping)
# 字符串中引用变量:{0}和{1} test = ‘i am {0}, age {1}‘ print(test) # i am {0}, age {1} # 为字符串中变量赋值 v = test.format(‘alex‘, 19) print(v) # i am alex, age 19 # 字符串中引用变量:{name}和{num} test = ‘i am {name}, age {num}‘ print(test) # i am {name}, age {num} # 为字符串中变量赋值 v = test.format(name=‘alex‘, num=19) print(v) # i am alex, age 19 v1 = test.format_map({"name":‘alex‘, "num":19}) print(v1) # i am alex, age 19
isalnum() isalpha()
test1 = "usdfd839" # 是否字母和数字组成的字符串 v = test1.isalnum() # True v1 = test1.isalpha() # False, 是否为字母序列 strTest = "abddfj" s1 = strTest.isalpha() # True, 是否为字母序列
isdecimal() :键盘数字
isdigit() :键盘数字、②等数字
isnumeric() :键盘数字、②、贰
numTest = "123" v1 = numTest.isdecimal() # True,是否键盘数字 v2 = numTest.isdigit() # True,包括②等数字 print("②".isdigit()) # True print("贰".isdigit()) # False print("贰壹②".isnumeric()) # True print("Ⅱ".isdigit()) # False print("Ⅱ".isdecimal()) # False
def expandtabs(self, tabsize: int = 8):制表,输出
# def expandtabs(self, tabsize: int = 8) # expandtabs,制表: \n断句 \t对齐 # tabsize:长度,使用空格填充对齐 test2 = "username\temail\tpassword\nlaiying\tying@qq.com\t123\nlaiying\tying@qq.com\t123\nlaiying\tying@qq.com\t123" v2 = test2.expandtabs(20) print(v2)
print(v2)如下:
username email password
laiying ying@qq.com 123
laiying ying@qq.com 123
laiying ying@qq.com 123
# 反转大小写 print("aLex".swapcase()) # AlEX print("ALex".swapcase()) # alEX
是否正确命名规则,也包括关键字def class
# 是否正确的标识符:即是否正确命名规则,也包括关键字def class print("def".isidentifier()) # True print("class".isidentifier()) # True print("_123".isidentifier()) # True print("123".isidentifier()) # False print("userName".isidentifier()) # True
isprintable() 是否全部为可见字符
# isprintable() 是否全部为可见字符 # 不可见字符: \t \n \001 print("是否全部为可见字符") print("dfsdifhfd337&&***//".isprintable()) # True print("dfsdi\nfhfd337\001&&***//".isprintable()) # False print("dfsdifhfd337\001&&***//".isprintable()) # False
isspace()是否全部为空格
# isspace()是否全部为空格 print(" ".isspace()) # True print(" \t".isspace()) # True print(" \001".isspace()) # False print(" \n".isspace()) # True
istitle() 判断是否为标题
title() 转换为标题
print("是否为标题(只能判断英文)") print("Process finished with exit code 0".istitle()) # False print("Process finished with exit code 0".title()) # Process Finished With Exit Code 0 print("Process finished with exit code 0".title().istitle()) # True
将字符串中的每一个元素按指定分隔符进行拼接
print("将字符串中的每一个元素按指定分隔符进行拼接") print(" ".join("你是风儿我是沙")) # 你 是 风 儿 我 是 沙 print("_".join("你是风儿我是沙")) # 你_是_风_儿_我_是_沙 # 拼接字符串元素 v = "_".join("abcde") # 拼接列表元素 v = "_".join([‘jason‘, ‘rose‘]) # jason_rose
去除指定字符序列
去除匹配字符序列,优先最长字符序列,再依次删除匹配的短子序列
print("去除空格(包括\n \t) 和 去除指定字符序列") print(" haha ".lstrip()) print(" haha ".rstrip()) print(" haha ".strip()) print(" haha ".strip()) print("\n haha ".strip()) print("dfhahadf".lstrip(‘df‘)) # hahadf print("dfhahadf".rstrip(‘df‘)) # dfhaha print("dfhahadf".strip(‘df‘)) # haha
去除匹配字符序列,优先最长字符序列,再依次删除匹配的短子序列
ps:删除最长匹配后,剩余的序列再继续匹配删除
print("dfhahadf".rstrip(‘9adf‘)) # dfhah print("dfhahadf".rstrip(‘9adfah‘)) # 全删:从右开始删adf,再删ah,再删h,再删df
# 构建映射表:tr_tab = str.maketrans("abcdef","123456") # 执行映射替换:srcStr.translate(tr_tab) # 将对应位置的字符进行替换 # abcdef # 123456 # 构建映射表:str.maketrans("abcdef","123456") # 执行映射替换:srcStr.translate(tr_tab) tr_tab = str.maketrans("abcdef","123456") strList = "fasdfjbaczxjivewr;oifajmewirkcvxweafo;dsapojnsafdk" tranList = strList.translate(tr_tab) print(tranList) # 61s46j213zxjiv5wr;oi61jm5wirk3vxw516o;4s1pojns164k
def partition(self, sep) : 指定sep分隔,返回包含sep
def rpartition(self, sep): 从右开始,指定sep分隔,返回包含sep
def split(self, sep=None, maxsplit=-1): 指定sep分隔,返回不包含sep,分隔次数maxsplit
def rsplit(self, sep=None, maxsplit=-1)
# 分隔 # print("***分隔***") print("testadfkajoeiawjfs".partition("a")) # (‘test‘, ‘a‘, ‘dfkajoeiawjfs‘) print("testadfkajoeiawjfs".rpartition("a")) # (‘testadfkajoei‘, ‘a‘, ‘wjfs‘) print("testadfkajoeiawjfs".split("a")) # [‘test‘, ‘dfk‘, ‘joei‘, ‘wjfs‘] print("testadfkajoeiawjfs".split("a",1)) # [‘test‘, ‘dfkajoeiawjfs‘] print("testadfkajoeiawjfs".split("a",2)) # [‘test‘, ‘dfk‘, ‘joeiawjfs‘] print("testadfkajoeiawjfs".rsplit("a",2)) # [‘testadfk‘, ‘joei‘, ‘wjfs‘] print("testadfkajoeiawjfs".split("a",6)) # [‘test‘, ‘dfk‘, ‘joei‘, ‘wjfs‘] print("testadfkajoeiawjfs".rsplit("a",6)) # [‘test‘, ‘dfk‘, ‘joei‘, ‘wjfs‘] print(v) # range(0, 100) in_str = "33+88" v1, v2 = in_str.split(‘+‘) print(in_str, ‘=‘, int(v1) + int(v2)) # 121
def splitlines(self, keepends=None) : keepends是否保留换行符,默认False
# 分隔,分页,换行 # def splitlines(self, keepends=None) : keepends是否保留换行符 print("fdahsf\niensdka\npoieafl\nfewascsakdn".splitlines()) # [‘fdahsf‘, ‘iensdka‘, ‘poieafl‘, ‘fewascsakdn‘] print("fdahsf\niensdka\npoieafl\nfewascsakdn".splitlines(False)) # [‘fdahsf‘, ‘iensdka‘, ‘poieafl‘, ‘fewascsakdn‘] print("fdahsf\niensdka\npoieafl\nfewascsakdn".splitlines(True)) # [‘fdahsf\n‘, ‘iensdka\n‘, ‘poieafl\n‘, ‘fewascsakdn‘]
print(len("first")) # 5 # Python3: len获取当前字符串中有几个字符 # Python27:len获取字符串占几个字节,utf8单个中文3字节 print(len("张五常")) # 3
字符串实际上就是字符的数组,所以也支持下标索引。
如果有字符串name = ‘abcdef‘,在内存中的实际存储如下:
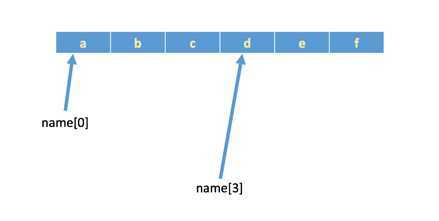
如果想取出部分字符,那么可以通过下标的方法,(注意python中下标从 0 开始)
name = ‘abcdef‘
print(name[0]) # a
print(name[1]) # b
print(name[-2]) //负数表示从右边开始:-2表示右边第二个
切片是指对操作的对象截取其中一部分的操作。字符串、列表、元组都支持切片操作。
切片的语法:[ 起始: 结束: 步长 ]
步长:表示下标变化的规律。
注意:选取的区间属于 [左闭 右开),即从"起始"位开始,到"结束"位的前一位结束(不包含结束位本身)。
ps: "结束"位,-1表示字符串序列最后一位,-2表示字符串序列倒数第二位,...以此类推。
我们以字符串为例讲解。
如果取出一部分,则可以在中括号[]中使用
# -*- coding:utf-8 -*- ‘‘‘ python中下标从 0 开始 ‘‘‘ name = ‘abcdef‘ print(name[0:3]) # 取 下标0~2 的字符 abc print(name[:3]) # 取 下标0~2 的字符 abc print(name[0:5]) # 取 下标为0~4 的字符 abcde print(name[3:5]) # 取 下标为3、4 的字符 de print(name[2:]) # 取 下标为2开始到最后的字符 cdef print(name[1:-1]) # 取 下标为1开始 到 最后第2个 之间的字符 bcde print(name[1:-1:2]) # 取 下标为1开始 到 最后第2个之间[1,-1)从前往后步长为2 返回 bd print(name[::2]) # 取头-尾间的字符,步长为2 ace print(name[5:1:2]) # 返回空 print(name[5:1:-2]) # [5,1)从后往前步长为-2 返回 fd print(name[1:5:2]) # [1,5)从前往后步长为2 返回 bd print(name[1:7:2]) # [1,7)从前往后步长为2 返回 bdf print(name[1:10:2]) # [1,10)从前往后步长为2 返回 bdf
while循环遍历
c_str = "索引,下标,获取字符串中的子串" index = 0 print("===while===") while index < len(c_str): v = c_str[index] print(v) index += 1 print("====while end===")
for循环遍历
print("***for***") for f_v in c_str: print(f_v) print("***for end***")
原文:https://www.cnblogs.com/LIAOBO/p/13363722.html