Spark SQL Parser简单来说就是将sql语句解析成为算子树的过程,在这个过程中,spark sql采用了antlr4来完成。
当执行spark.sql()方法时,会调用
Dataset.ofRows(self, sessionState.sqlParser.parsePlan(sqlText))
实际会调用:
/** Creates LogicalPlan for a given SQL string. */
override def parsePlan(sqlText: String): LogicalPlan = parse(sqlText) { parser =>
val tmp = astBuilder.visitSingleStatement(parser.singleStatement())
tmp match {
case plan: LogicalPlan => plan
case _ =>
val position = Origin(None, None)
throw new ParseException(Option(sqlText), "Unsupported SQL statement", position, position)
}
}
解析详细的操作如下:
protected def parse[T](command: String)(toResult: SqlBaseParser => T): T = {
logDebug(s"Parsing command: $command")
val oo = CharStreams.fromString(command)
logInfo(s"Parsing command: $oo")
val lexer = new SqlBaseLexer(new UpperCaseCharStream(CharStreams.fromString(command)))
lexer.removeErrorListeners()
lexer.addErrorListener(ParseErrorListener)
val tokenStream = new CommonTokenStream(lexer)
val parser = new SqlBaseParser(tokenStream)
parser.addParseListener(PostProcessor)
parser.removeErrorListeners()
parser.addErrorListener(ParseErrorListener)
try {
try {
// first, try parsing with potentially faster SLL mode
parser.getInterpreter.setPredictionMode(PredictionMode.SLL)
toResult(parser)
}
catch {
case e: ParseCancellationException =>
// if we fail, parse with LL mode
tokenStream.seek(0) // rewind input stream
parser.reset()
// Try Again.
parser.getInterpreter.setPredictionMode(PredictionMode.LL)
toResult(parser)
}
}
catch {
case e: ParseException if e.command.isDefined =>
throw e
case e: ParseException =>
throw e.withCommand(command)
case e: AnalysisException =>
val position = Origin(e.line, e.startPosition)
throw new ParseException(Option(command), e.message, position, position)
}
}
}
在这里面会利用antlr4来解析整个sql语句,首先会尝试使用比较快速的SLL方式来解析,如果失败会转而使用LL方式来解析。解析完成的sqlBaseParser会调用singleStatement()之后会构建整棵树
之后调用AstBuilder的visitSingleStatement来递归查看每个节点,来返回生成的LogicalPlan, 这一步,主要利用antlr4生成的代码,使用访问者模式来挨个查看各个节点的处理,返回对应的结果,其主要的实现是继承了SqlBaseBaseVisitor的AstBuild类中。
假设有一段sql如下:
SELECT * FROM NAME WHERE AGE > 10
那么它经过antlr4解析之后的树结构如下:
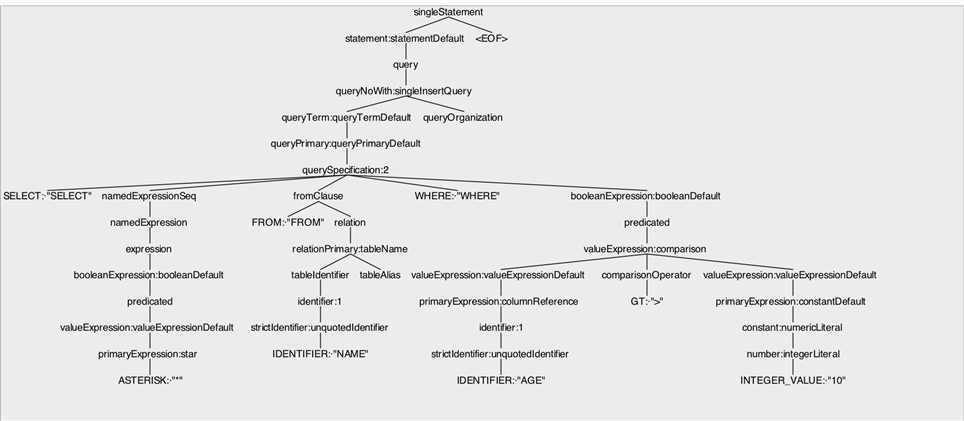
在AstBuilder.visitSingleStatement方法中:
override def visitSingleStatement(ctx: SingleStatementContext): LogicalPlan = withOrigin(ctx) {
val statement: StatementContext = ctx.statement
printRuleContextInTreeStyle(statement, 1)
visit(ctx.statement).asInstanceOf[LogicalPlan]
}
首先输入是SingleStatementContext,实际也就是上面树形图里面的根节点,之后获取了根节点下面的StatementContext,由上图可知实际获取的就是StatementDefaultContext,再来看看他的accept方法
@Override
public <T> T accept(ParseTreeVisitor<? extends T> visitor) {
if ( visitor instanceof SqlBaseVisitor ) return ((SqlBaseVisitor<? extends T>)visitor).visitStatementDefault(this);
else return visitor.visitChildren(this);
}
大多数的节点都是类似这样的实现,对某些特殊的节点例如FromClauseContext,在AstBuilder中有特殊的处理逻辑实现。所以AstBuilder解析整棵树都是通过遍历整棵树,形成logicalPlan。
在上面的整棵树里面在解析到QuerySpecification节点时,在这里面会触发形成logicalPlan的操作:
/**
* Create a logical plan using a query specification.
*/
override def visitQuerySpecification(
ctx: QuerySpecificationContext): LogicalPlan = withOrigin(ctx) {
val from = OneRowRelation().optional(ctx.fromClause) {
visitFromClause(ctx.fromClause)
}
withQuerySpecification(ctx, from)
}
在visitFromClause中会去查看FromClause节点下面的Relation,同时如果有join操作的话,也会在其中解析join操作,生成from子树;
在from解析之后就是在withQuerySpecification中携带着from子树解析where,聚合、表达式等子节点形成一颗对整个sql解析之后的树结构。
/**
* Add a query specification to a logical plan. The query specification is the core of the logical
* plan, this is where sourcing (FROM clause), transforming (SELECT TRANSFORM/MAP/REDUCE),
* projection (SELECT), aggregation (GROUP BY ... HAVING ...) and filtering (WHERE) takes place.
*
* Note that query hints are ignored (both by the parser and the builder).
*/
private def withQuerySpecification(
ctx: QuerySpecificationContext,
relation: LogicalPlan): LogicalPlan = withOrigin(ctx) {
import ctx._
// WHERE
def filter(ctx: BooleanExpressionContext, plan: LogicalPlan): LogicalPlan = {
Filter(expression(ctx), plan)
}
// Expressions.
val expressions = Option(namedExpressionSeq).toSeq
.flatMap(_.namedExpression.asScala)
.map(typedVisit[Expression])
// Create either a transform or a regular query.
val specType = Option(kind).map(_.getType).getOrElse(SqlBaseParser.SELECT)
specType match {
case SqlBaseParser.MAP | SqlBaseParser.REDUCE | SqlBaseParser.TRANSFORM =>
// Transform
// Add where.
val withFilter = relation.optionalMap(where)(filter)
// Create the attributes.
val (attributes, schemaLess) = if (colTypeList != null) {
// Typed return columns.
(createSchema(colTypeList).toAttributes, false)
} else if (identifierSeq != null) {
// Untyped return columns.
val attrs = visitIdentifierSeq(identifierSeq).map { name =>
AttributeReference(name, StringType, nullable = true)()
}
(attrs, false)
} else {
(Seq(AttributeReference("key", StringType)(),
AttributeReference("value", StringType)()), true)
}
// Create the transform.
ScriptTransformation(
expressions,
string(script),
attributes,
withFilter,
withScriptIOSchema(
ctx, inRowFormat, recordWriter, outRowFormat, recordReader, schemaLess))
case SqlBaseParser.SELECT =>
// Regular select
// Add lateral views.
val withLateralView = ctx.lateralView.asScala.foldLeft(relation)(withGenerate)
// Add where.
val withFilter = withLateralView.optionalMap(where)(filter)
// Add aggregation or a project.
val namedExpressions = expressions.map {
case e: NamedExpression => e
case e: Expression => UnresolvedAlias(e)
}
val withProject = if (aggregation != null) {
withAggregation(aggregation, namedExpressions, withFilter)
} else if (namedExpressions.nonEmpty) {
Project(namedExpressions, withFilter)
} else {
withFilter
}
// Having
val withHaving = withProject.optional(having) {
// Note that we add a cast to non-predicate expressions. If the expression itself is
// already boolean, the optimizer will get rid of the unnecessary cast.
val predicate = expression(having) match {
case p: Predicate => p
case e => Cast(e, BooleanType)
}
Filter(predicate, withProject)
}
// Distinct
val withDistinct = if (setQuantifier() != null && setQuantifier().DISTINCT() != null) {
Distinct(withHaving)
} else {
withHaving
}
// Window
val withWindow = withDistinct.optionalMap(windows)(withWindows)
// Hint
hints.asScala.foldRight(withWindow)(withHints)
}
}
在这里解析后的算子树是未绑定的树结构算是unresolved LogicPlan。
总结,这一步的理解主要是spark中sqlBase.g4文件中的定义,然后就是对于观察者模式中生成的默认代码,其实大多数的代码规律都一样,之后就是AstBuild类中对某些节点逻辑重写;这里如果想仔细研究这步的话,可以参考上面,打开spark中的sqlBase.g4文件,然后在idea里面打开ANTLR Preview在里面输入sql,然后在sqlBase.g4文件里面选中singleExpression右击test Rule,然后看生成的树结构,其实对应的就是AstBuild树从上往下遍历的节点,这里面有的节点AstBuilder没有重写,直接遍历子节点,有的在AstBuilder里面有重写可以看看其具体逻辑,主要就是上面讲到的QuerySpecification、FromClauseContext、booleanDefault、nameExpression等。
Spark SQL Parser到Unresolved LogicPlan
原文:https://www.cnblogs.com/ldsggv/p/13380370.html