随着数据越来越多或者并发访问多时,系统的每一层都需要进行优化。增加服务器,冗余部署,限流等都是解决方案,那么对于 "有状态"的数据库怎样优化呢。数据库本身在IO CPU都有瓶颈。
下面讲讲数据库优化的几个阶段
数据库慢sql的记录配置
// 查看慢查询是否开启
show variables like ‘slow_query_log‘;
// 慢查询所规定的时间 MySQL5.21版以前long_query_time 参数的单位是秒,默认值是10。
// 这相当于说最低只能记录执行时间超过 1 秒的查询,怎么记录查询时间超过100毫秒的SQL语句记录呢?在mysql5.21+后版本支持毫秒记录
show variables like ‘long_query_time‘;
// 通过设置将其打开
set global slow_query_log=‘ON‘;
// 设置慢查询日志保存的位置
set global slow_query_log_file=‘/var/lib/mysql/test_1116.log‘;
mysql中 执行语句 exlplain [你的sql语句]
返回结果如下,其中最重要的字段为:id、type、key、rows、Extra
| 列名 | 描述 |
|---|---|
| id | 执行顺序 id越大越先执行,id相同从上到下 |
| select_type | 查询的类型,主要是用于区分普通查询、联合查询、子查询等复杂的查询 |
| partitions | 该列显示的为分区表命中的分区情况。非分区表该字段为空(null)。 |
| type | 查询使用了那种类型 |
| possible_keys | possible_keys 显示可能应用在这张表中的索引,一个或多个。查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询实际使用。 |
| key | 实际使用的索引,如果为NULL,则没有使用索引。(可能原因包括没有建立索引或索引失效) |
| key_len | 索引中使用的字节数,可通过该列计算查询中使用的索引的长度。在不损失精确性的情况下,长度越短越好。 |
| ref | 如果是使用的常数等值查询,这里会显示const,如果是连接查询,被驱动表的执行计划这里会显示驱动表的关联字段,如果是条件使用了表达式或者函数,或者条件列发生了内部隐式转换,这里可能显示为func |
| rows | 根据表统计信息及索引选用情况,大致估算出找到所需的记录所需要读取的行数,也就是说,用的越少越好 |
| filtered | 这个字段表示存储引擎返回的数据在server层过滤后,剩下多少满足查询的记录数量的比例,注意是百分比。 |
| Extra | 不适合在其他字段中显示,但是十分重要的额外信息 |
以下为表格中某些具体的说明
1、SIMPLE:简单的select查询,查询中不包含子查询或者union
2、PRIMARY:查询中包含任何复杂的子部分,最外层查询则被标记为primary
3、SUBQUERY:在select 或 where列表中包含了子查询
4、DERIVED:在from列表中包含的子查询被标记为derived(衍生),mysql或递归执行这些子查询,把结果放在零时表里
5、UNION:若第二个select出现在union之后,则被标记为union;若union包含在from子句的子查询中,外层select将被标记为derived
6、UNION RESULT:从union表获取结果的select
type包含的类型包括如下图所示的几种,从好到差依次是
system > const > eq_ref > ref > range > index > all
mysql对数据使用一个外部的索引排序,而不是按照表内的索引进行排序读取。也就是说mysql无法利用索引完成的排序操作成为“文件排序”
使用临时表保存中间结果,也就是说mysql在对查询结果排序时使用了临时表,常见于order by 和 group by
表示相应的select操作中使用了覆盖索引(Covering Index),避免了访问表的数据行,效率高
如果同时出现Using where,表明索引被用来执行索引键值的查找(参考上图)
如果没用同时出现Using where,表明索引用来读取数据而非执行查找动作
索引优点:不需要引入中间件,引入中间件就需要考虑的更多了。
需要思考的问题,那种索引在那些场景用?联合索引的最左匹配?索引建多少?索引的优缺点。
关于索引不再赘述有另外一篇文章。
什么场景下缓存?
在优化sql无法解决问题的情况下,才考虑搭建缓存。毕竟你使用缓存的目的,就是将复杂的、耗时的、不常变的执行结果缓存起来,降低数据库的资源消耗。
缺点:加入缓存时就向上一步所说的一样,加入了中间件,增加了系统的复杂性,引入中间件带来新的问题。需要考虑数据库和缓存之间的一致性。以及使用缓存可能出现缓存雪崩、缓存穿透、缓存击穿、热key提前加载等问题。
使用主从复制的架构,主节点即可读也可写,主要是写。从节点作为读节点。主从架构实现数据库备份,实现数据库负载均衡,提高数据库可用性。
那么怎么去做读操作,写操作?1. 可以在业务层中区分读写的请求,去请求不同的数据库。2. 利用中间件mycat或者altas做读写分离,数据库之间的同步操作。
主从数据库之间是怎样做数据同步的呢?
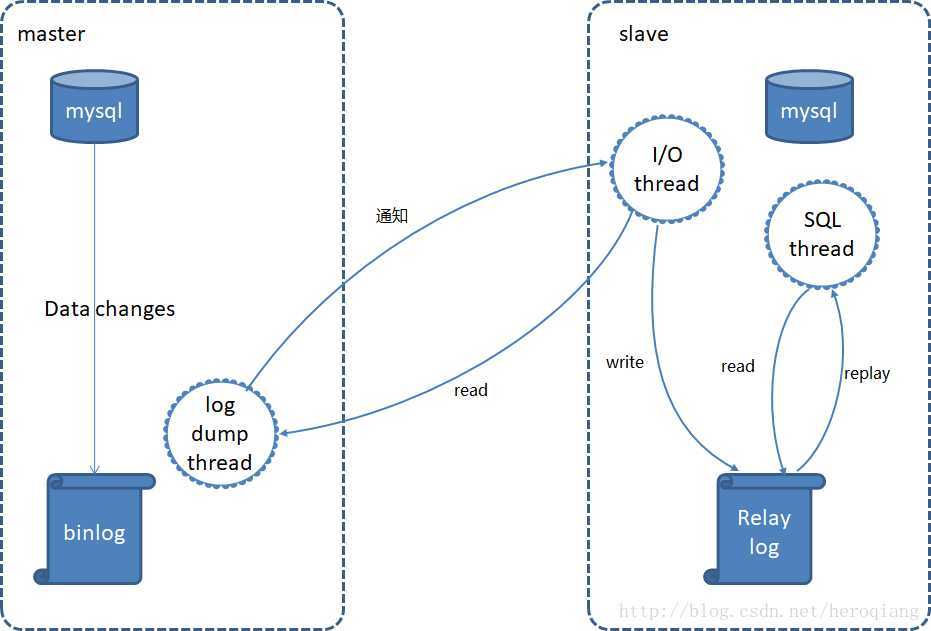
如图所示,主库有一个log dump线程,将binlog传给从库
从库有两个线程,一个I/O线程,一个SQL线程,I/O线程读取主库传过来的binlog内容并写入到relay log,SQL线程从relay log里面读取内容,写入从库的数据库。
使用 读写分离的数据量 标准。
此时复杂性增高,如何保证主从之间的一致性。中从之间的延迟问题怎么解决?在从库中对刚写完的数据进行查找时是找不到的。根据CAP定理,主从架构本来就是一种高可用架构,是无法满足一致性的
哪怕你采用同步复制模式或者半同步复制模式,都是弱一致性,并不是强一致性。所以,推荐还是利用缓存,来解决该问题。
步骤如下:
1、自己通过测试,计算主从延迟时间,建议mysql版本为5.7以后,因为mysql自5.7开始,多线程复制功能比较完善,一般能保证延迟在1s内。不过话说回来,mysql现在都出到8.x了,还有人用5.x的版本么。
2、数据库的写操作,先写数据库,再写cache,但是有效期很短,就比主从延时的时间稍微长一点。
3、读请求的时候,先读缓存,缓存不存在(这时主从同步已经完成),再读数据库。
如果主库崩了?数据在主库还未同步?
单表行数超过 500 万行或者单表容量超过 2GB,才推荐进行分库分表。如果预计三年后的数据量根本达不到这个级别,请不要在创建表时就分库分表。
当一张表的数据达到几千万时,查询一次所花的时间会变长。业界公认MySQL单表容量在 1千万 以下是最佳状态,因为这时它的BTREE索引树高在3~5之间。
主要两个维度,对于数据库垂直拆分或是水平拆分。对于表是垂直拆分还是水平拆分。垂直拆分也算是按业务进行划分,把常用的字段放一起,不常用的放一起。水平拆分指数据维度的拆分,比如按id散列分,按时间范围分等。
垂直拆分原则一般是如下三点:
(1)把不常用的字段单独放在一张表。
(2)把常用的字段单独放一张表
(3)经常组合查询的列放在一张表中(联合索引)。
垂直拆分 分库
以表为依据,按照业务归属不同,将不同的表拆分到不同的库中。
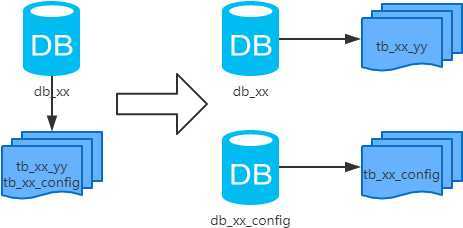
垂直拆分 分表
按字段为依据,按照字段的活跃性,将表中的字段拆分到不同表中。
结果:每个表的结构都不一样。之前的select * 现在需要从两个表里面查出来,这两个表之间有关联字段。
水平拆分不如垂直拆分,用垂直拆分,分成不同模块后,发现单模块的压力过大,你完全可以给该模块单独做优化,例如提高该模块的机器配置等。如果是水平拆分,拆成两张表,代码需要变动,然后发现两张表还不行,再变代码,再拆成三张表的?水平拆分模块间耦合性太强,成本太大,不是特别推荐。
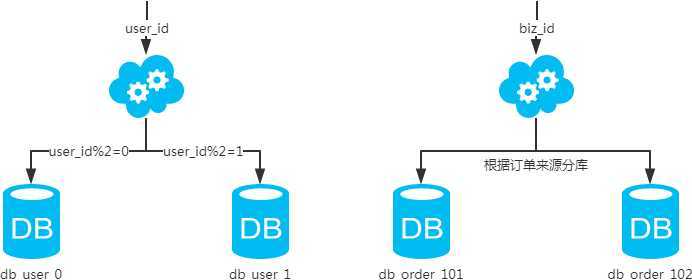
水平拆分 分库
以字段为依据,按照一定策略(hash、range等),将一个库中的数据拆分到多个库中。
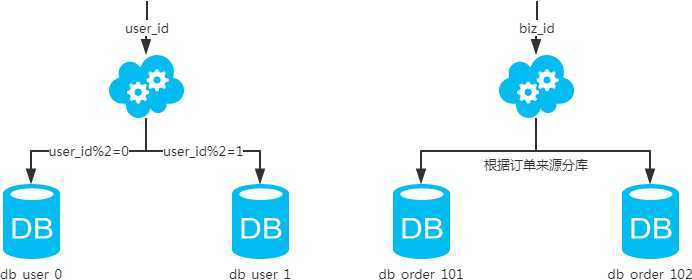
结果:每个库的结构都一样,每个库的数据都不一样。所有库的病机是全部数据。
水平拆分 分表
以字段为依据,按照一定策略(hash、range等),将一个表中的数据拆分到多个表中。
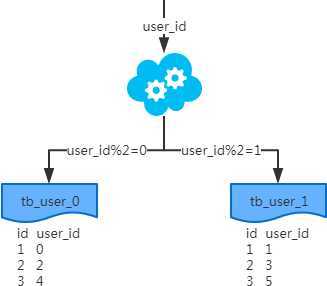
分库分表产生的问题:
sharding的中间件大概可以分成两大类,一种是基于jdbc的lib组件,一种是基于代理(Proxy)的中间件。
基于jdbc的lib组件,好处在于易于和Java服务集成、轻量;易于上手,无运维成本;业务直接到数据库,少一层proxy理论上性能更好。基于Proxy的中间件,需要在所有的数据源中间搭一个Proxy服务,Java的数据源只连接到Proxy上,由Proxy负责底层的分库分表,以及请求路由,优势在于解耦性比较高;可以找专门的DBA负责和运维Proxy,分库分表操作对于Java程序员透明化;易于实现监控、数据迁移、连接管理等功能;劣势就是运维成本的增加,小公司可能没有预算请专门的DBA和运维人员来做这个解耦工作。
lib组件包括:当当网sharding-sphere、蘑菇街TSharding;就是jar包使用起来无需额外部署,无其他依赖。
基于Proxy的中间件:TDDL、DBProxy、Atlas、oneproxy、vitess、mycat、cobar等。
分库分表如何平缓部署项目,平稳升级?
夜间部署,出现问题 回滚第二天晚上接着弄
双写部署法
最好的方式还是binlog,消息队列对代码有严重的侵入性,会产生大量非业务代码,因为你要组装消息体。
双写部署带来的问题:
有一种方法是,只验关键性的几个字段是否一致。
还有一种是 ,一次取50条(不一定50条,具体自己定,我只是举例),然后像拼字符串一样,拼在一起。用md5进行加密,得到一串数值。新库一样如法炮制,也得到一串数值,比较两串数值是否一致。如果一致,继续比较下50条数据。如果发现不一致,用二分法确定不一致的数据在0-25条,还是26条-50条。以此类推,找出不一致的数据,进行记录即可。
除了数据库,项目是如何平缓升级部署的?此处不延展讲,作为拓展。 部署的策略对比
原文:https://www.cnblogs.com/wei57960/p/13382877.html