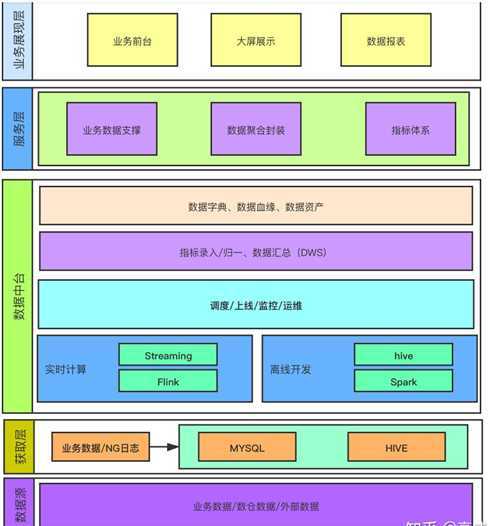
数据架构包含:数据采集层,数据调度平台、数据展示层
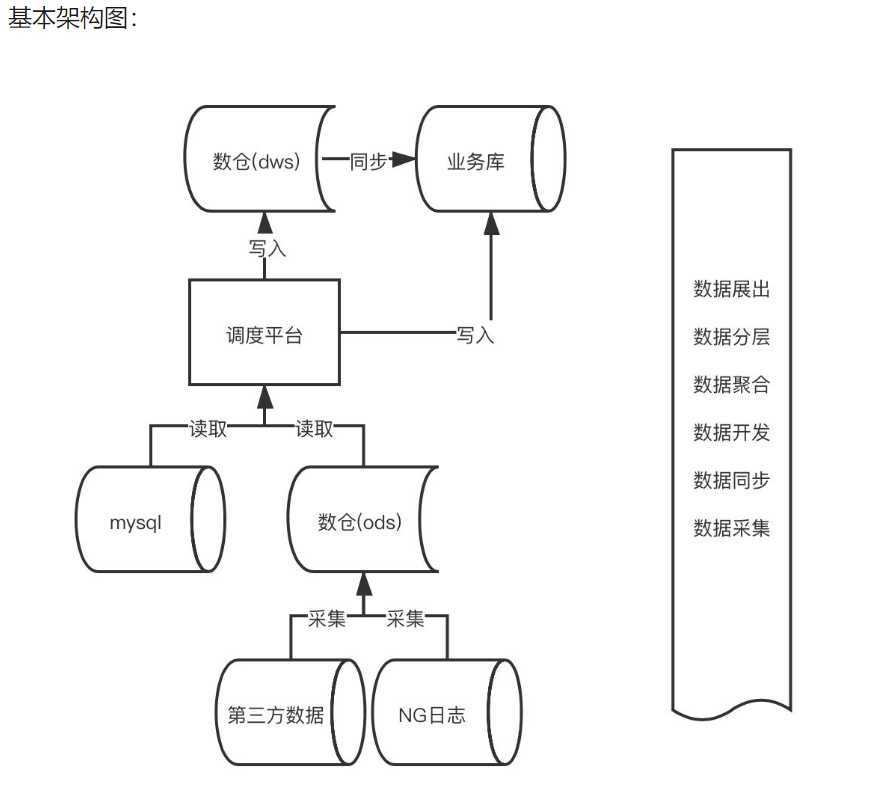
数据采集
埋点采集主要是离线数仓和实时采集,改进方案:NG -> Kafka -> StructuredStreaming/Flink,然后实时的需求直接走StructuredStreaming/Flink,获取实时的数据存到redis/ES等内存数据库中,可以做搜索推荐。离线的将数据存到HDFS中,第二天对昨天的日志进行合并(主要是合并小文件)
数据中台主要包含:数据治理、数据安全、数据质量
Hadoop的最核心的存储层叫做HDFS,全称是Hadoop文件存储系统,有了存储系统还要有分析系统maoreduce,mapreduce做分析太重,脸书开源了hive
Hadoop最开始设计是用来跑文件的,对于数据的批处理(batch data processing)能力较强,实时数据(streaming data processing) 使用spark 或flink
原文:https://www.cnblogs.com/Christbao/p/13385231.html