数据准备:
drop table if exists t1; /* 如果表t1存在则删除表t1 */
CREATE TABLE `t1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`a` int(11) DEFAULT NULL,
`b` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_a` (`a`),
KEY `idx_b` (`b`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4;
drop procedure if exists insert_t1; /* 如果存在存储过程insert_t1,则删除 */
delimiter ;;
create procedure insert_t1() /* 创建存储过程insert_t1 */
begin
declare i int; /* 声明变量i */
set i=1; /* 设置i的初始值为1 */
while(i<=10000)do /* 对满足i<=10000的值进行while循环 */
insert into t1(a,b,c,d) values(i,i,i,i); /* 写入表t1中a、b两个字段,值都为i当前的值 */
set i=i+1; /* 将i加1 */
end while;
end;;
delimiter ; /* 创建批量写入10000条数据到表t1的存储过程insert_t1 */
call insert_t1(); /* 运行存储过程insert_t1 */
insert into t1(a,b,c,d) values (null,10001,10001,10001),(10002,10002,10002,10002);
drop table if exists t2; /* 如果表t2存在则删除表t2 */
create table t2 like t1; /* 创建表t2,表结构与t1一致 */
alter table t2 engine =myisam; /* 把t2表改为MyISAM存储引擎 */
insert into t2 select * from t1; /* 把t1表的数据转到t2表 */
CREATE TABLE `t3` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`a` int(11) DEFAULT NULL,
`b` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB CHARSET=utf8mb4;
insert into t3 select * from t1; /* 把t1表的数据转到t3表 */
1.count(a) 和 count(*) 的区别
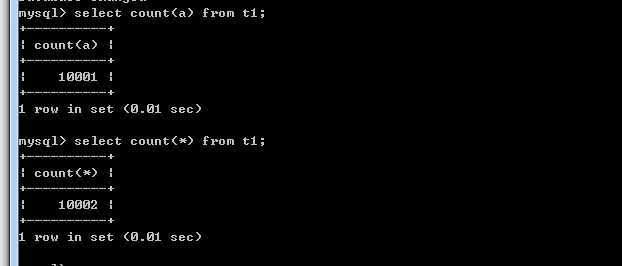
原因:实际在数据写入时,写入了 10002 行数据。因此,对 a 字段为 null 的这一行不做统计
显然,count(*)是要统计所有的行。因此,如果希望知道结果集的行数,最好使用 count(*)。
explain select count(*) from t2;
在 Extra 字段发现 “Select tables optimized away” 关键字,表示是从 MyISAM 引擎维护的准确行数上获取到的统计值。而 InnoDB 并不会保留表中的行数,因为并发事务可能同时读取到不同的行数。所以执行 count(*) 时都是临时去计算的,会比 MyISAM 引擎慢很多。
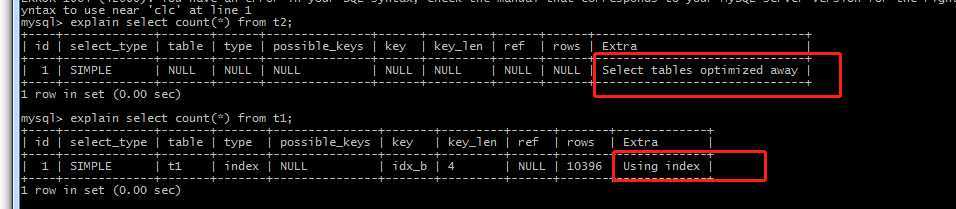
对比 MyISAM 引擎和 InnoDB 引擎 count(*) 的区别,可以知道:
在上面这个例子,InnoDB 表 t1 在执行 count(*) 时,为什么会走 b 字段的索引而不是走主键索引呢?下面我们分析下:
在 MySQL 5.7.18 之前,InnoDB 通过扫描聚簇索引来处理 count(*) 语句。
从 MySQL 5.7.18 开始,通过遍历最小的可用二级索引来处理 count(*) 语句。如果不存在二级索引,则扫描聚簇索引。但是,如果索引记录不完全在缓存池中的话,处理 count(*) 也是比较久的。
新版本为什么会使用二级索引来处理 count(*) 语句呢?
原因是 InnoDB 二级索引树的叶子节点上存放的是主键,而主键索引树的叶子节点上存放的是整行数据,所以二级索引树比主键索引树小。因此优化器基于成本的考虑,优先选择的是二级索引。所以 count(主键) 其实没 count (*) 快。
原文:https://www.cnblogs.com/php-json/p/13386906.html