
灰阶分割
根据区域必须满足的属性规则给其硬编码一个便签,例如根据区域的像素灰度强度。例如区域分裂与聚合算法
此算法递归地将图像拆分为子区域,直到可以分配标签,然后通过合并具有相同标签的相邻子区域。
缺点:由于必须是基于硬编码的规则,仅仅根据灰阶信息对于复杂的case很难表示,比如人体。需要特征提取及一些优化技巧来更好的学习表示复杂的个体类别。
条件随机场
定义:CRF 是一类用于结构化预测的统计建模方法。
而将先验知识:邻接的区域像素往往具有相同的标签类别-----这种先验加入建模。与离散分类器不同,CRF可以在预测之前考虑"相邻上下文",例如像素之间的邻接关系。因此成为语义分割的理想方法之一。
图像中的每个像素都与一组有限的可能状态关联。在语义分割任务重,这个状态就是目标标签。将状态(或标签) u 分配给单个像素 (x) 的成本称为一元损失。
为了对像素之间的关系进行建模,我们还考虑将一对标签 (u,v) 分配给一对像素 (x,y) ,这样产生的过程成本称为二元成本。
因此我们可以考虑图像中的由一对邻接像素构成的像素对 (网格 条件随机场);也可以同时建模图像中的所有像素对的关系----不再限于邻接像素对,即稠密 条件随机场。
所有像素的这种一元损失(或二元损失)之和称为随机场的势---Energy。最小化场势,以获得更好的分割结果。
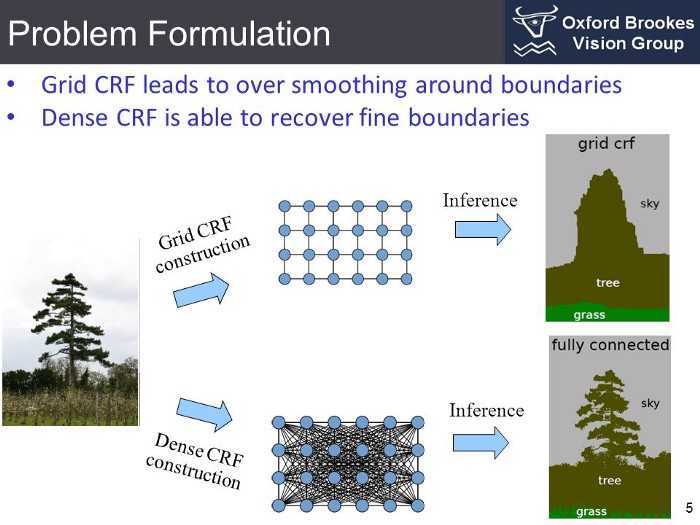
深度学习已经大大简化了实现语义分割的pipeline,并取得了不错的效果。
缺点:这种基本架构尽管有效,但是:
以上问题的解决发展:
U-Net
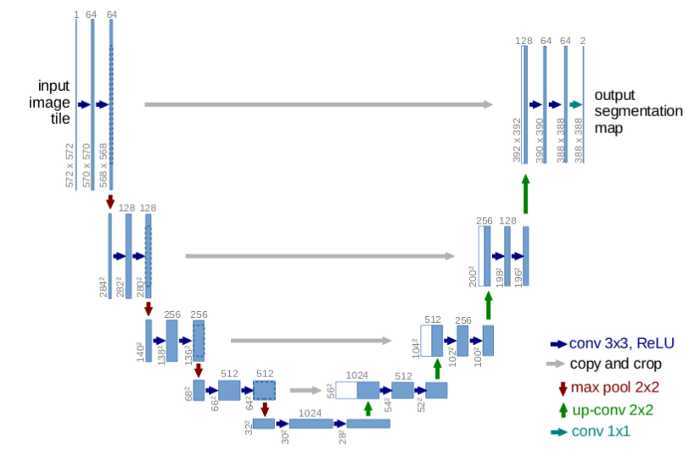
将卷积层的输出(分辨率大些)crop后, 跳层连接( 到反卷积得到的对应level特征图(分辨率小些)上。
跨层连接实现了梯度的更好传播,而且提供了图像的多尺度信息。
大尺度(Unet图示中的高层layer,分辨率高)有助于模型更好的分类,识别高层语义信息。
小尺度(Unet图示中的低层layer,分辨率小)有助于模型更好的分割和定位,识别低层语义信息,如位置等。
提拉米苏模型
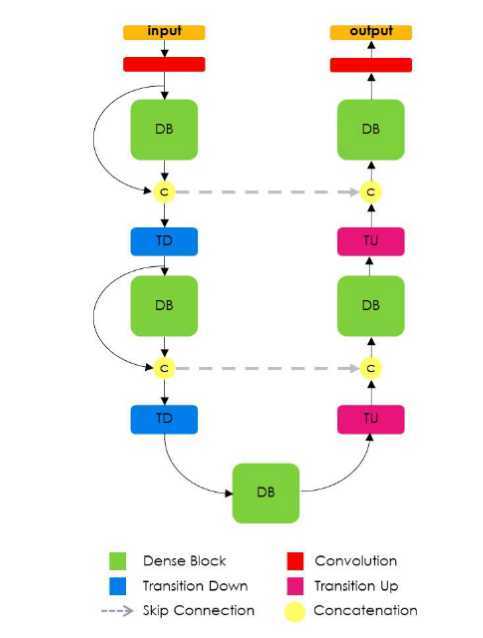
其中的DenseBlock就是卷积-反卷积。然后再拼接上DB前面的所有特征图作为下面的输入。
优点:参数效率高,可以更好的get到很前面的信息
缺点:深度学习框架的实现决定了这种大量的concat操作很占内存(img2col典型的空间换时间),因此需要更大的显存。
多尺度方法
通过卷积核金字塔得到不同尺度的特征图,然后再差值到相同分辨率来信息融合
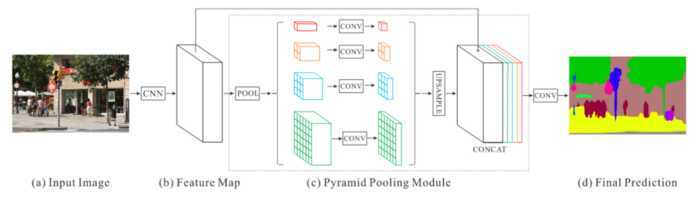
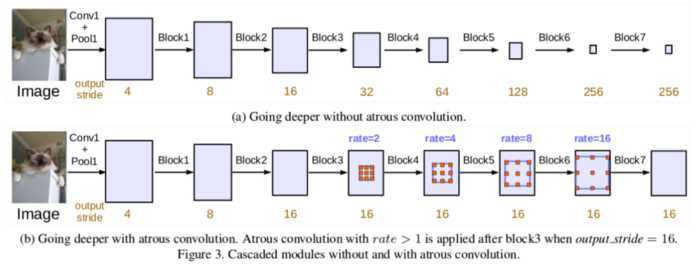
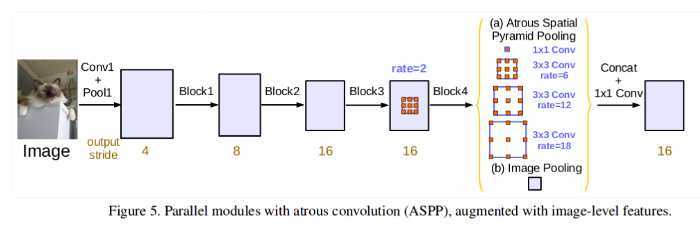
通过不同rate的膨胀卷积来获取多尺度信息
其中多个膨胀卷积块的使用方式:
级联
并联
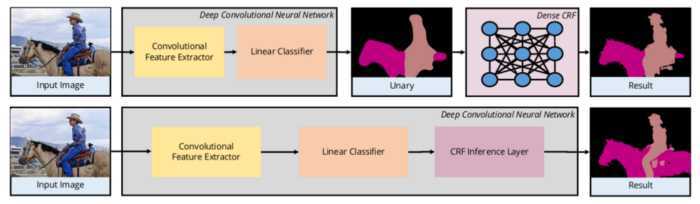
由于语义分割任务本身的特点,也需要特殊的损失函数
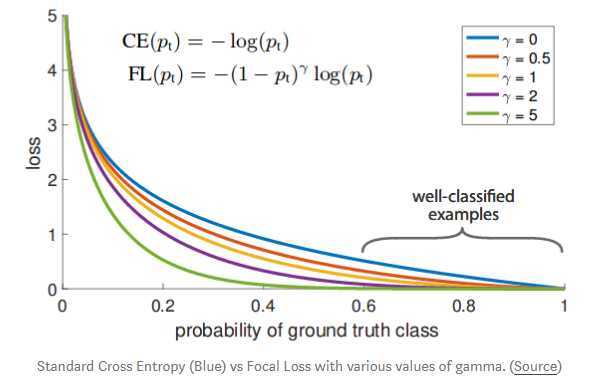
因此,为了让模型专注于困难样本,给标注的交叉熵损失函数加上一个焦点系数(一个预测置信度的函数),预测置信度越高,则使简单样本的损失很快接近0,这样损失会尽可能被难样本主导,模型能够更好的学习难样本。
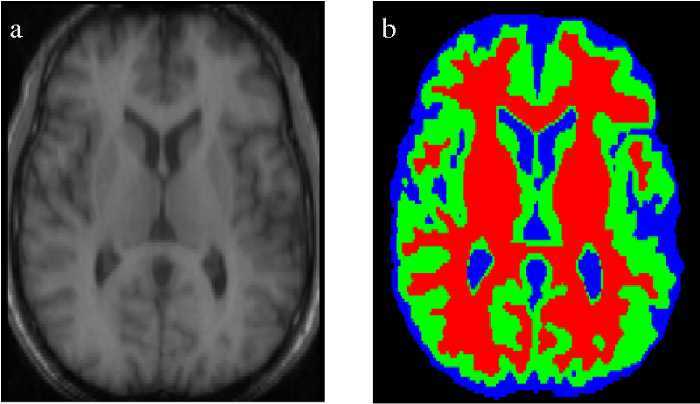
医疗图像分割
识别异常如肿瘤,通过3D分割图来估算器官组织的体积
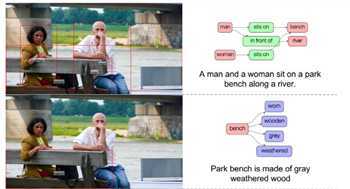
场景理解
语义分割是场景理解及视觉问答VQA的基础
场景理解的目标:输出一个标题或场景图
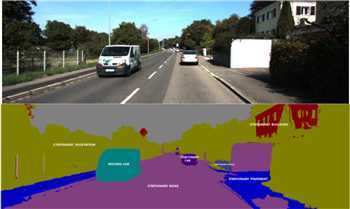
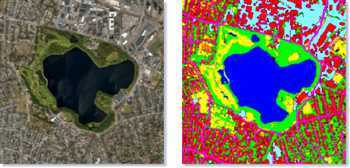
遥感地图处理
确定道路,湖泊,物体类别及区块类别等
时尚工厂
提取衣服,redress换装
原文:https://www.cnblogs.com/Henry-ZHAO/p/13392736.html