论文地址:https://arxiv.org/abs/1612.08242
网络结构:
大多数检测框架依赖于VGG-16作为的基本特征提取器。VGG-16是一个强大的,准确的分类网络,但它是不必要的复杂。在单张图像224×224分辨率的情况下VGG-16的卷积层运行一次前馈传播需要306.90亿次浮点运算。YOLO框架使用基于Googlenet架构的自定义网络。这个网络比VGG-16更快,一次前馈传播只有85.2亿次的操作。然而,它的准确性比VGG-16略差。在ImageNet上,对于单张裁剪图像,224×224分辨率下的top-5准确率,YOLO的自定义模型获得了88.0%,而VGG-16则为90.0%。YOLOv2使用Darknet-19网络,有19个卷积层和5个最大池化层。相比YOLOv1的24个卷积层和2个全连接层精简了网络,仅仅需要55.8亿次操作,在imageNet的224*224分辨率下仍然能达到top1:72.9% 和top5:91.2%的准确性,每一个convolutional后面都加有BN.
backbone结构:
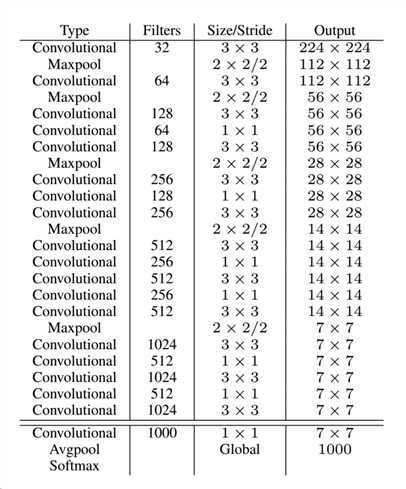
Detection architecture,route中,一个数字,表示将前面的层的输出拿过来,二个数字表示将两个层的输出concat在一起,reorg表示将输出的结果进行reshape.
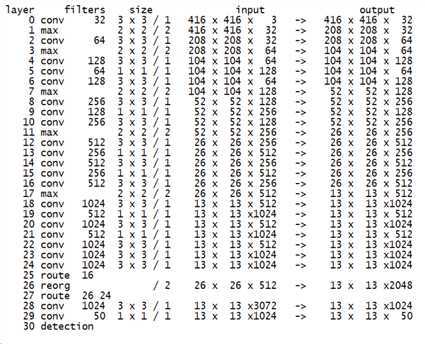
YOLOv2 训练的三个阶段:
分类网络训练完后,就该训练检测网络了,作者去掉了原网络最后一个卷积层,转而增加了三个3 * 3 * 1024的卷积层,在最后在增加一个1 * 1的卷积层,输出维度是检测所需的数量。对于VOC数据集,预测5种boxes大小,每个box包含5个坐标值和20个类别,所以总共是5 * (5+20)= 125个输出维度。同时也添加了转移层(passthrough layer ),从最后那个3 * 3 * 512的卷积层连到倒数第二层,使模型有了细粒度特征。添加anchor box后,将分辨率更改为416×416,因为模型以32的因子下采样,所以最后输出的大小为13*13,这样做是想要特征图中大小为奇数,有一个中心单元格.
利用Kmeans聚类,解决了anchor boxes的尺寸选择问题.
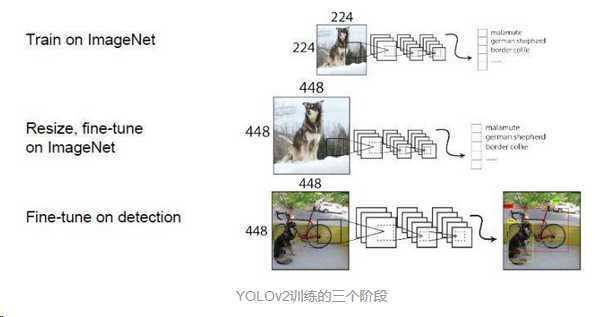
网络在特征图(13 *13 )的每个cell上预测5个bounding boxes,每一个bounding box预测5个坐标值:tx,ty,tw,th,to。如果这个cell距离图像左上角的边距为(cx,cy)以及该cell对应的box维度(bounding box prior)的长和宽分别为(pw,ph),那么对应的box为:
原文:https://www.cnblogs.com/magicpig666/p/10516792.html