RDD不仅是分布式的数据集合,更是Spark的核心。
RDD会跟踪应用每个块的所有转换(日志),也就是说,当RDD的某个分区数据丢失时会根据日志进行重新计算。
RDD是无Schema的数据结构。
1、RDD的生成
RDD的生成有三种方式,
1) .parallelize() 集合生成
2)外部文件或系统
3)通过其他RDD生成
外部文件或系统生成RDD通常可以是NTFS、FAT本地文件系统,或HDFS、S3、Cassandra这类的分布式文件系统。
可以支持多种数据格式,文本、parquet、JSON、Hive表以及使用JDBC驱动程序可读取的关系数据库中的数据。
2、转换-Transformation
转换是对数据集进行逻辑的处理,并未涉及数据的归并或分散。
官网参考:http://spark.apache.org/docs/latest/rdd-programming-guide.html#rdd-operations
map,该方法应用在每个RDD元素上,大多数情况是对每一行的转换。
filter,对RDD中的元素进行过滤,筛选符合条件的元素。
flatMap,应用在每个RDD上,每行看做一个列表。
distinct,返回列表中不同的值。
sample,返回数据集的随机样本。第一个参数指定采样是否应该替换,第二个参数定义返回数据的分数,第三个参数是伪随机数产生器的种子。
leftOuterJoin,和sql中的left join同理。
repaatition,对数据集进行重新分区,改变数据集分区的数量。会重组数据,对性能产生重大影响。
3、操作-Action
官网参考:http://spark.apache.org/docs/latest/rdd-programming-guide.html#actions
take,返回数据的多少行,优于count方法,take仅返回单个分区的数据。
collect,将所有RDD的元素返回给驱动程序。
reduce,减少RDD中的元素。rdd.map(lambda row:row[1]).reduce(lambda x,y: x+y)
count,统计RDD中元素的数量
saveAsTextFile,保存RDD为文本,每一个分区一个文件。
foreach,对每个RDD元素使用相同的函数。
4、宽窄依赖
窄依赖是指父RDD的每个分区只被子RDD的一个分区使用,宽依赖是父RDD的每个分区可能被多个子RDD分区所使用的。
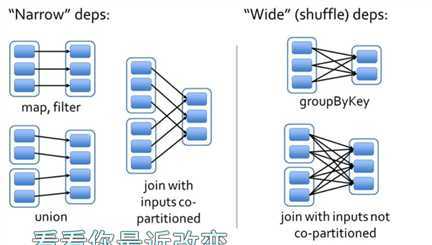
宽依赖会触发shuffle过程。
原文:https://www.cnblogs.com/wind-man/p/13394272.html