import pandas as pd import matplotlib.pyplot as plt import numpy as np from pandas import DataFrame,Series %matplotlib inline states={‘SeriousDlqin2yrs‘:‘好坏客户‘, ‘RevolvingUtilizationOfUnsecuredLines‘:‘可用额度比值‘, ‘age‘:‘年龄‘, ‘NumberOfTime30-59DaysPastDueNotWorse‘:‘逾期30-59天笔数‘, ‘DebtRatio‘:‘负债率‘, ‘MonthlyIncome‘:‘月收入‘, ‘NumberOfOpenCreditLinesAndLoans‘:‘信贷数量‘, ‘NumberOfTimes90DaysLate‘:‘逾期90天笔数‘, ‘NumberRealEstateLoansOrLines‘:‘固定资产贷款量‘, ‘NumberOfTime60-89DaysPastDueNotWorse‘:‘逾期60-89天笔数‘, ‘NumberOfDependents‘:‘家属数量‘} # index_col=0将原始数据第0列的数字去掉 data = pd.read_csv(‘./rankingcard.csv‘,index_col=0) data.head()
# 修改列索引将上边字典映射其中 data.rename(columns=states,inplace=True) data.head() # 1为不好的客户
# 查看是否有重复行数据 data.duplicated().sum() # 609 # 删除重复的数据 data.drop_duplicates(inplace=True) # 恢复行索引 data.index = range(data.shape[0]) data.shape # (149391, 11)
# 查看哪列存在缺失数据 data.isnull().any(axis=0) 好坏客户 False 可用额度比值 False 年龄 False 逾期30-59天笔数 False 负债率 False 月收入 True 信贷数量 False 逾期90天笔数 False 固定资产贷款量 False 逾期60-89天笔数 False 家属数量 True dtype: bool # 查看缺失数据的个数 data.isnull().sum() 好坏客户 0 可用额度比值 0 年龄 0 逾期30-59天笔数 0 负债率 0 月收入 29221 信贷数量 0 逾期90天笔数 0 固定资产贷款量 0 逾期60-89天笔数 0 家属数量 3828 dtype: int64
家属人数列缺失数据比较少可以考虑直接删除,月收入缺失数据比较多,使用均值填充。
# 对‘家属数量‘带有空值的行删除 data = data.loc[data[‘家属数量‘].notnull()] # 对‘月收入‘带有空值的行用均值进行填充 # 新的填充方式:df.fillna({col:xxx}) data.fillna({‘月收入‘: data[‘月收入‘].mean()},inplace=True) # 恢复行索引 data.index = range(data.shape[0]) # 再次查看是否有缺失值 data.isnull().sum() 好坏客户 0 可用额度比值 0 年龄 0 逾期30-59天笔数 0 负债率 0 月收入 0 信贷数量 0 逾期90天笔数 0 固定资产贷款量 0 逾期60-89天笔数 0 家属数量 0 dtype: int64
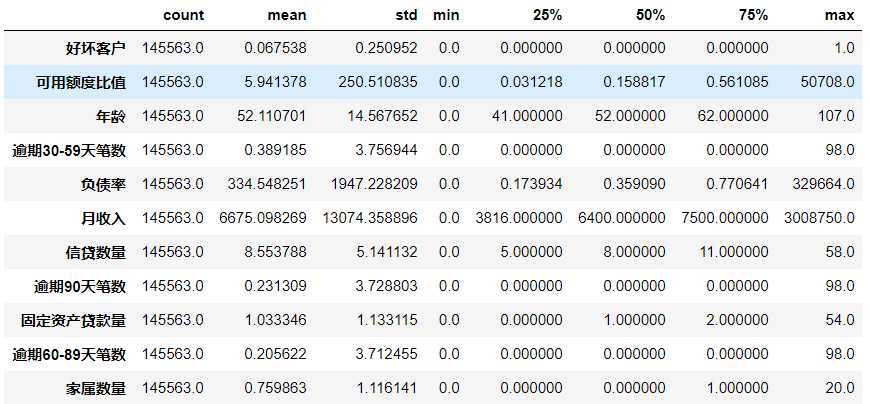
# 查看数据描述 data.describe().T
# 查看数据描述,通过列表指定所对应得比例,更容易发现问题,发现异常值如下 data.describe([0.1,0.25,0.5,0.75,0.9,0.99]).T
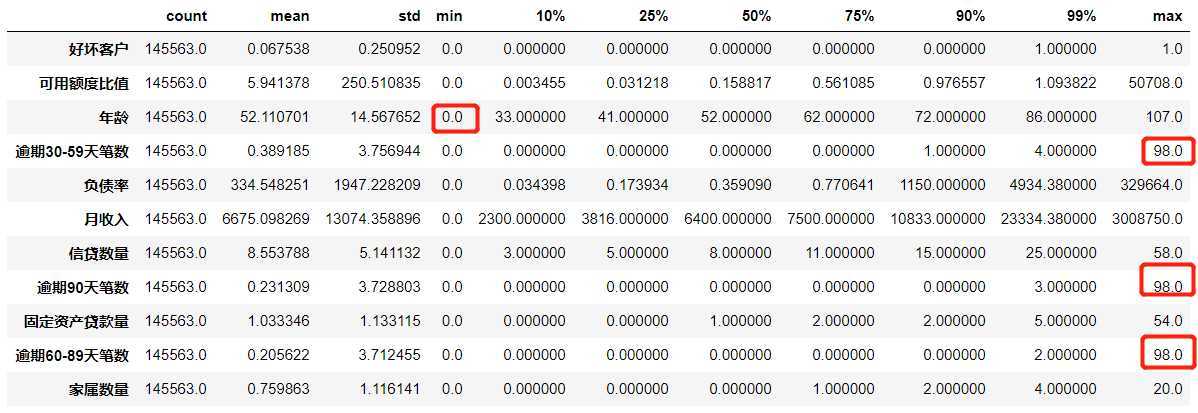
年龄的最小值居然有0,这不符合银行的业务需求,即便是儿童账户也要至少8岁,我们可以 查看一下年龄为0的人有多少
(data[‘年龄‘] == 0).sum() # 有一个年龄为0得数据 直接删除
data = data.loc[data[‘年龄‘] != 0]
# 将大于90天得统一去掉 data = data.loc[data[‘逾期30-59天笔数‘]<90] data = data.loc[data[‘逾期60-89天笔数‘]<90] data = data.loc[data[‘逾期90天笔数‘]<90] # 恢复索引 data.index = range(data.shape[0]) # 查看标签分布情况 data[‘好坏客户‘].value_counts() 0 135648 1 9706 Name: 好坏客户, dtype: int64 # 分布有点不均衡,但可以使用逻辑回归模型参数处理 data[‘好坏客户‘].value_counts() / data[‘好坏客户‘].value_counts().sum() 0 0.933225 1 0.066775 Name: 好坏客户, dtype: float64 data.shape # (145354, 11)
这里仅对年龄进行单变量分析
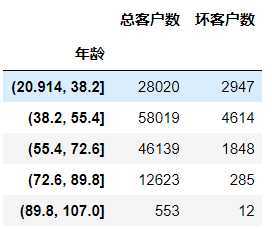
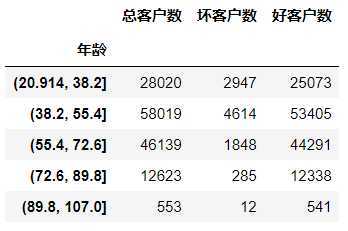
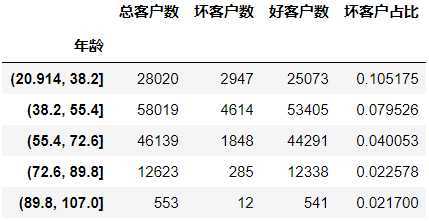
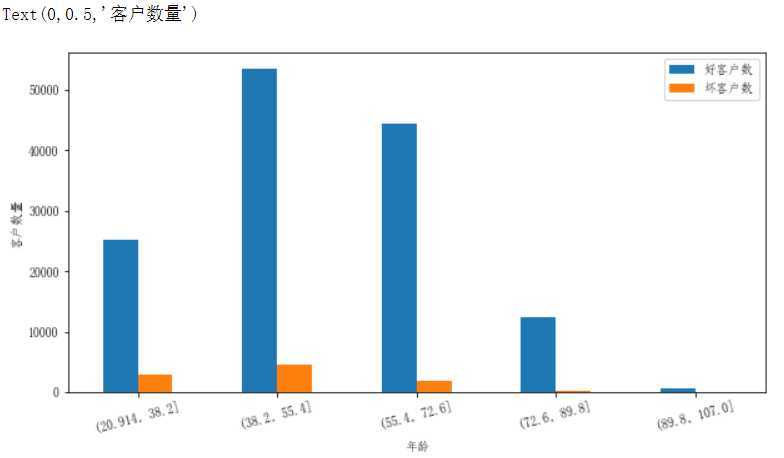
#对年龄进行分箱操作,分成5组 age_cut = pd.cut(data[‘年龄‘],bins=5) age_cut.value_counts() (38.2, 55.4] 58019 (55.4, 72.6] 46139 (20.914, 38.2] 28020 (72.6, 89.8] 12623 (89.8, 107.0] 553 Name: 年龄, dtype: int64 # 基于分组求出每个不同年龄段对应用户的数量 # 注意:对Series进行分组计数,使用另一个Series对其分组然后计数 (注意,以前没用过) sum_user_age = data[‘好坏客户‘].groupby(by=age_cut).count() 年龄 (20.914, 38.2] 28020 (38.2, 55.4] 58019 (55.4, 72.6] 46139 (72.6, 89.8] 12623 (89.8, 107.0] 553 Name: 好坏客户, dtype: int64 # 对各组的坏客户数 # 因为0是好用户,1是坏用户,求和0不会计入 bad_user_sum = data[‘好坏客户‘].groupby(by=age_cut).sum() 年龄 (20.914, 38.2] 2947 (38.2, 55.4] 4614 (55.4, 72.6] 1848 (72.6, 89.8] 285 (89.8, 107.0] 12 Name: 好坏客户, dtype: int64 # 级联 age_cut_group = pd.concat((sum_uer_age,bad_user_sum),axis=1) # 级联后发现列索引有问题,修改列索引 age_cut_group.columns = [‘总客户数‘,‘坏客户数‘]
# 添加一列好客户数量 age_cut_group[‘好客户数‘] = age_cut_group[‘总客户数‘] - age_cut_group[‘坏客户数‘]
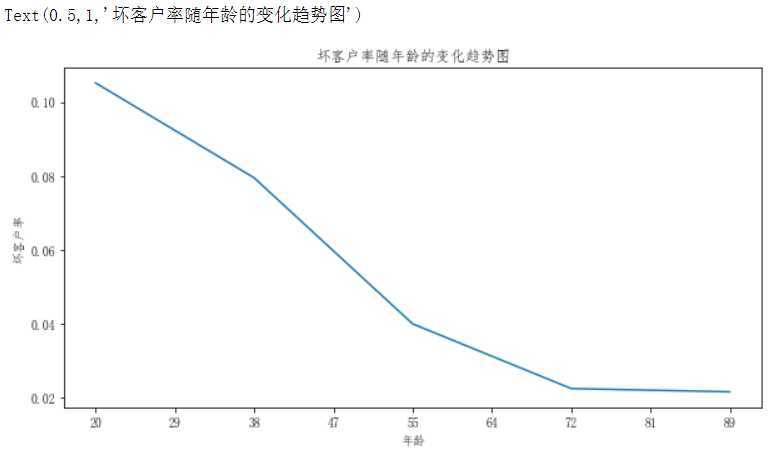
# 在添加一列坏客户占比 age_cut_group[‘坏客户占比‘] = age_cut_group[‘坏客户数‘] / age_cut_group[‘总客户数‘]
# 使用柱状图表示不同年龄段好坏客户的数量 # 指定后可以显示中文 from pylab import mpl mpl.rcParams[‘font.sans-serif‘] = [‘FangSong‘] # 指定默认字体 mpl.rcParams[‘axes.unicode_minus‘] = False # 解决保存图像是负号‘-‘显示为方块的问题 ax1 = age_cut_group[[‘好客户数‘,‘坏客户数‘]].plot.bar(figsize=(10,5)) ax1.set_xticklabels(age_cut_group.index,rotation=15) ax1.set_ylabel(‘客户数量‘)
# 绘制线型图 ax11 = age_cut_group["坏客户占比"].plot(figsize=(10,5)) ax11.set_xticklabels([0,20,29,38,47,55,64,72,81,89,98,107]) ax11.set_ylabel("坏客户率") ax11.set_title("坏客户率随年龄的变化趋势图")
原文:https://www.cnblogs.com/wgwg/p/13398503.html