监督学习
训练含有很多特征的数据集,不过数据集中的样本都有一个标签或目标。
监督学习是目前最常见的机器学习类型。给定一组样本(通常由人工标注),它可以学会将 输入数据映射到已知目标。
虽然监督学习主要包括分类和回归,但还有更多的奇特变体,主要包括如下几种:
无监督学习
训练含有很多特征的数据集,然后学习出这个数据集上有用的结构性质。在深度学习中,我们通常要学习生成数据集的整个概率分布,显式地,比如密度估计,或是隐式地,比如合成或去噪。还有一些其他的类型的无监督学习任务,例如聚类,将数据集分成相似样本的集合。
无监督学习是指在没有目标的情况下寻找输入数据的有趣变换,其目的在于数据可视化、 数据压缩、数据去噪或更好地理解数据中的相关性。无监督学习是数据分析的必备技能,在解 决监督学习问题之前,为了更好地了解数据集,它通常是一个必要步骤。降维(dimensionality reduction)和聚类(clustering)都是众所周知的无监督学习方法。
自监督学习
自监督学习是监督学习的一个特例,它与众不同,值得单独归为一类。自监督学习是没有 人工标注的标签的监督学习,你可以将它看作没有人类参与的监督学习。标签仍然存在(因为 总要有什么东西来监督学习过程),但它们是从输入数据中生成的,通常是使用启发式算法生 成的。
监督学习、自监督学习和无监督学习之间的区别有时很模糊, 这三个类别更像是没有明确界限的连续体。
强化学习
在强化学习中,智能体(agent)接收有关其环境的信息,并学会选择使某种奖励最大化的行动。 例如,神经网络会“观察”视频游戏的屏幕并输出游戏操作,目的是尽可能得高分,这种神经 网络可以通过强化学习来训练。
分类和回归术语表

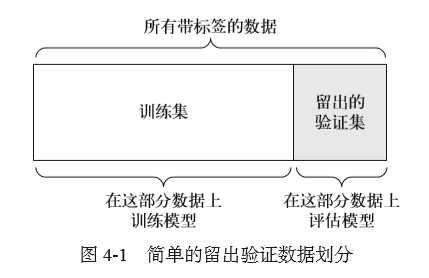
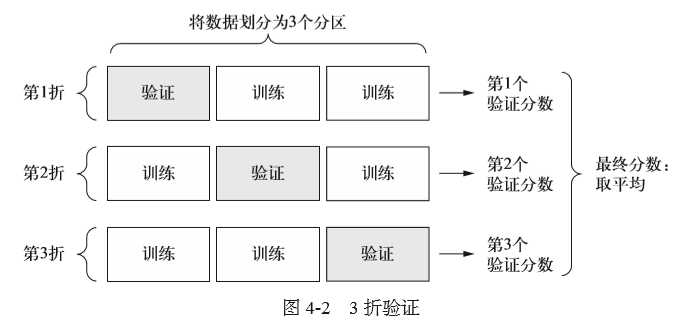
带有打乱数据的重复K折验证
如果可用的数据相对较少,而你又需要尽可能精确地评估模型,那么可以选择带有打乱数据的重复K 折验证(iterated K-fold validation with shuffling)。我发现这种方法在Kaggle 竞赛中特别有用。具体做法是多次使用 K 折验证,在每次将数据划分为 K 个分区之前都先将数据打乱。最终分数是每次K 折验证分数的平均值。注意,这种方法一共要训练和评估P×K 个模型(P 是重复次数),计算代价很大。
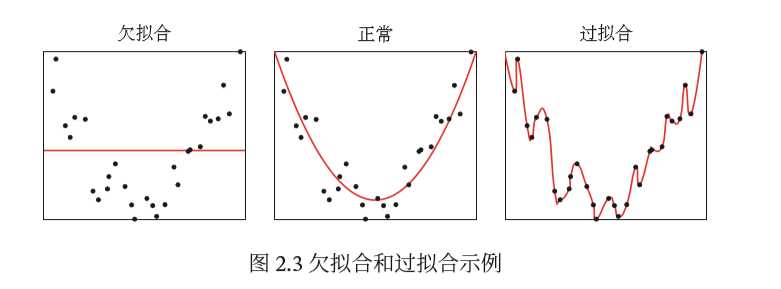
防止过拟合的最简单的方法就是减小模型大小,即减少模型中可学习参数的个数(这由层 数和每层的单元个数决定)。在深度学习中,模型中可学习参数的个数通常被称为模型的容量
奥卡姆剃刀(Occam’s razor)原理:如果一件事情有两种解释,那么最可能正 确的解释就是最简单的那个,即假设更少的那个。这个原理也适用于神经网络学到的模型:给定一些训练数据和一种网络架构,很多组权重值(即很多模型)都可以解释这些数据。简单模型比复杂模型更不容易过拟合。
这里的简单模型(simple model)是指参数值分布的熵更小的模型(或参数更少的模型,比 如上一节的例子)。因此,一种常见的降低过拟合的方法就是强制让模型权重只能取较小的值, 从而限制模型的复杂度,这使得权重值的分布更加规则(regular)。这种方法叫作权重正则化 (weight regularization),其实现方法是向网络损失函数中添加与较大权重值相关的成本(cost)。 这个成本有两种形式。
在 Keras 中,添加权重正则化的方法是向层传递权重正则化项实例(weight regularizer instance)作为关键字参数。
对某一层使用dropout,就是在训练过程中随机将该层的一些输出特征舍 弃(设置为0)。假设在训练过程中,某一层对给定输入样本的返回值应该是向量 [0.2, 0.5, 1.3, 0.8, 1.1]。使用dropout 后,这个向量会有几个随机的元素变成0,比如 [0, 0.5, 1.3, 0, 1.1]。dropout 比率(dropout rate)是被设为0 的特征所占的比例,通常在0.2~0.5 范围内。测试时没有单元被舍弃,而该层的输出值需要按dropout 比率缩小,因为这时比训练时 有更多的单元被激活,需要加以平衡。
在 Keras 中,你可以通过 Dropout 层向网络中引入dropout,dropout 将被应用于前面一层 的输出。
原文:https://www.cnblogs.com/Weber-security/p/13415947.html