一:什么是正则?
正则就是用一些具有特殊含义的符号组合到一起(称为正则表达式)来描述字符或者字符串的方法。或者说:正则就是用来描述一类事物的规则。(在Python中)它内嵌在Python中,并通过 re 模块实现。正则表达式模式被编译成一系列的字节码,然后由用 C 编写的匹配引擎执行。
正则表达式:由一系列特殊字符拼接而成的表达式/规则,该表达式用于从一个大字符串中匹配出符合规则的子字符串
二:常用匹配模式(元字符)
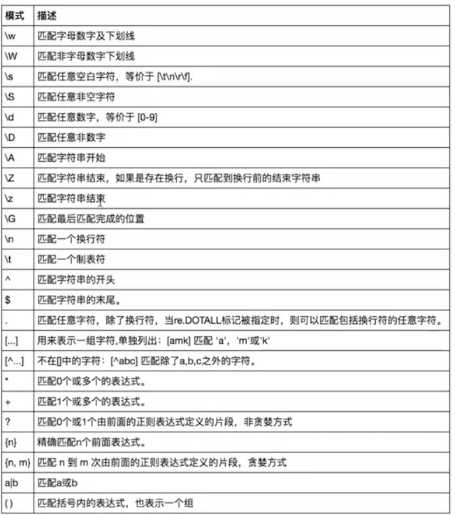
# 1、\w # print(re.findall(‘\w\w\w‘,"h ello 123_ (0")) # h ello 123_ (0 # \w\w\w # 2. \W # print(re.findall(‘\W‘,"h ello 123_ (0")) # 3、\s # print(re.findall(‘\s‘,"h e\tll\no 123_ (0")) # print(re.findall(‘\w\s‘,"h ello 123_ (0")) # 4、\S # print(re.findall(‘\S‘,"h e\tll\no 123_ (0")) # 5、\d # print(re.findall(‘\d‘,"h e\tll\no 123_ (0")) # 6、\D # print(re.findall(‘\D‘,"h e\tll\no 123_ (0")) # print(re.findall("a\db","a1b a2b a b aab aaaaaaaa1b a2c a22c a 3c")) # a1b a2b a b aab aaaaaaaa1b a2c a22c a 3c # a\db # ["a1b","a2b","a1b"] # 7、\n与\t # msg="""h e\tll\n\no 123_ (0 # \t1 # 2 # 3 # """ # print(re.findall(‘\n‘,msg)) # print(re.findall(‘\t‘,msg)) # print(re.findall(‘ ‘,msg)) # 8、^与$ # print(re.findall("^egon","egon asdf 213123 egonafsadfegon")) # egon asdf 213123 egonafsadfegon # ^egon # print(re.findall("egon$","egon asdf 213123 egonafsadfegon ")) # egon$ # print(re.findall("a\w\w\wc","ab12c3c a213c")) # print(re.findall("^a\w\w\wc$","ab_2c")) # 9、.与[] # 9.1 .:代表匹配一个字符,该字符可以是任意字符 # print(re.findall("a\db","a1b a2b aab aaaaaaab a+b a-b a c")) # print(re.findall("a\wb","a1b a2b aab aaaaaaab a+b a-b a c")) # print(re.findall("a.b","a1b a2b aab aaaaaaab a+b a-b a b a c")) # print(re.findall("a.b","a1b a2b aab aaaaaaab a\tb a-b a\nb a c",re.DOTALL)) # 9.2 []:代表匹配一个字符,我们可以指定该字符的范围 # print(re.findall("a[+-]b", "a1b a2b aab aaaaaaab a+b a-b a c")) # print(re.findall("a[.*/+-]b", "a.b a2b a*b a/b aab aaaaaaab a+b a-b a c")) # print(re.findall("a[a-z]b", "a.b a2b a*b a/b aab aaaaaaab a+b a-b a c")) # -放在[]内的开头或结果 # print(re.findall("a[a-zA-Z]b", "a.b a2b a*b a/b aAb aCb aab aaaaaaab a+b a-b a c")) # -放在[]内的开头或结果 # print(re.findall("a\db", "a.b a2b a*b a/b aAb aCb aab aaaaaaab a+b a-b a c")) # -放在[]内的开头或结果 # print(re.findall("a[0-9]b", "a.b a2b a*b a/b aAb aCb aab aaaaaaab a+b a-b a c")) # -放在[]内的开头或结果 # [^...]代表取反 # print(re.findall("a[^0-9]b", "a.b a2b a*b a/b aAb aCb aab aaaaaaab a+b a-b a c")) # -放在[]内的开头或结果 # 9.3 *: 左边那个字符出现0次或者无穷次 # print(re.findall("ab*","a ab abb abbbbbbbbbbbb bbbbbbbbb")) # a ab abb abbbbbbbbbbbb bbbbbbbbb # ab* # 9.4 +: 左边那个字符出现1次或者无穷次 # print(re.findall("ab+","a ab abb abbbbbbbbbbbb bbbbbbbbb")) # a ab abb abbbbbbbbbbbb bbbbbbbbb # ab+ # 9.5 {n,m}: 左边那个字符出现n次到m次 # print(re.findall("ab{0,}","a ab abb abbbbbbbbbbbb bbbbbbbbb")) # print(re.findall("ab*","a ab abb abbbbbbbbbbbb bbbbbbbbb")) # print(re.findall("ab{1,}","a ab abb abbbbbbbbbbbb bbbbbbbbb")) # print(re.findall("ab+","a ab abb abbbbbbbbbbbb bbbbbbbbb")) # print(re.findall("ab{2,5}","a ab abb abbb abbbb abbbbbbbb abbbbbbbbbbbb bbbbbbbbb")) # 9.6 ?: 左边那个字符出现0次到1次 # print(re.findall("ab?","a ab abb abbbbbbbbbbbb bbbbbbbbb")) # 9.7 .*: 匹配所有 # print(re.findall("a.*b","123 a1231-==-000b123123123123123b")) # 123 a1231-==-000b123123123123123b # a.*b # print(re.findall("a.*?b","123 a1231-==-000b123123123123123b")) # 例1: msg = ‘<a href="https://pan.baidu.com/s/1skWyTT7" target="_blank"><strong><span style="color: #ff0000;">原理图:https://pan.baidu.com/s/1skWyTT7</span></strong></a><a href="https://www.baidu/com">"点我啊"</a>‘ url_pattern = re.compile(‘href="(.*?)"‘) # res=url_pattern.findall(msg) # print(res) res=url_pattern.findall(‘<a href="www.sina.com.cn"></a>‘) print(res) # 例2: print(re.findall("a.*b","a1b a+b a-b a\nb a\tb",re.DOTALL)) # 10 ():分组 # print(re.findall(‘ab+‘,‘ababab123‘)) #[‘ab‘, ‘ab‘, ‘ab‘] # print(re.findall(‘(ab)+123‘,‘ababab123‘)) #[‘ab‘],匹配到末尾的ab123中的ab # ababab123 # (ab)(ab)(ab)(ab) # 10.1 取消分组 # print(re.findall(‘(?:ab)+123‘,‘ababab123‘)) #findall的结果不是匹配的全部内容,而是组内的内容,?:可以让结果为匹配的全部内容 # 11 |:或者 # print(re.findall("compan(?:ies|y)","Too many companies have gone bankrupt, and the next one is my company‘")) # Too many companies have gone bankrupt, and the next one is my company # compan(ies|y) # print(re.findall("\d+\.?\d*","as9fdasl333...4444df1111asdf3333dfadf333.44dafadf3.5555asdfsafd.5555")) # as9fdasldf1111asdf3333dfadf333.44dafadf3.5555asdfsafd.5555 # \d+\.?\d* # 12. \ # print(re.findall(‘a\\\\c‘,‘a\c a1c aac‘)) #对于正则来说a\\c确实可以匹配到a\c,但是在python解释器读取a\\c时,会发生转义,然后交给re去执行,所以抛出异常 # print(re.findall(r‘a\\c‘,‘a\c a1c aac‘)) #对于正则来说a\\c确实可以匹配到a\c,但是在python解释器读取a\\c时,会发生转义,然后交给re去执行,所以抛出异常
三、re模块提供的方法介绍
import re # print(re.findall(‘e‘,‘alex make love‘) ) #[‘e‘, ‘e‘, ‘e‘],返回所有满足匹配条件的结果,放在列表里 # print(re.search(‘e‘,‘alex make love‘)) #e,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。 # print(re.search("\d+\.?\d*","1.3 aa3.44aaa").group()) # print(re.search("\d+\.?\d*","asdfsadf")) # print(re.search("\d+\.?\d*"," 1.3 aa3.44aaa")) # print(re.match("\d+\.?\d*"," 1.3 aa3.44aaa")) # msg="egon:18-male=10" # print(msg.split(‘:‘)) # print(re.split(‘[:=-]‘,msg)) # msg=‘<a href="https://pan.baidu.com/s/1skWyTT7" target="_blank"><strong><span style="color: #ff0000;">原理图:https://pan.baidu.com/s/1skWyTT7</span></strong></a><a href="https://www.baidu/com">"点我啊"</a>‘ # print(re.findall(‘href=".*?"‘,msg))
原文:https://www.cnblogs.com/guojieying/p/13426215.html