Spark Streaming集成Kafka时,当数据量较小时默认配置一般都能满足我们的需要,但是当数据量大的时候,就需要进行一定的调整和优化。
合理的批处理时间(batchDuration)
几乎所有的Spark Streaming调优文档都会提及批处理时间的调整,在StreamingContext初始化的时候,有一个参数便是批处理时间的设定。如果这个值设置的过短,即个batchDuration所产生的Job并不能在这期间完成处理,那么就会造成数据不断堆积,最终导致Spark Streaming发生阻塞。而且,一般对于batchDuration的设置不会小于500ms,因为过小会导致SparkStreaming频繁的提交作业,对整个streaming造成额外的负担。在平时的应用中,根据不同的应用场景和硬件配置,我设在1~10s之间,我们可以根据SparkStreaming的可视化监控界面,观察Total Delay来进行batchDuration的调整,如下图:

合理的Kafka拉取量(maxRatePerPartition重要)
对于Spark Streaming消费kafka中数据的应用场景,这个配置是非常关键的,配置参数为:spark.streaming.kafka.maxRatePerPartition。这个参数默认是没有上线的,即kafka当中有多少数据它就会直接全部拉出。而根据生产者写入Kafka的速率以及消费者本身处理数据的速度,同时这个参数需要结合上面的batchDuration,使得每个partition拉取在每个batchDuration期间拉取的数据能够顺利的处理完毕,做到尽可能高的吞吐量,而这个参数的调整可以参考可视化监控界面中的Input Rate和Processing Time,如下图:
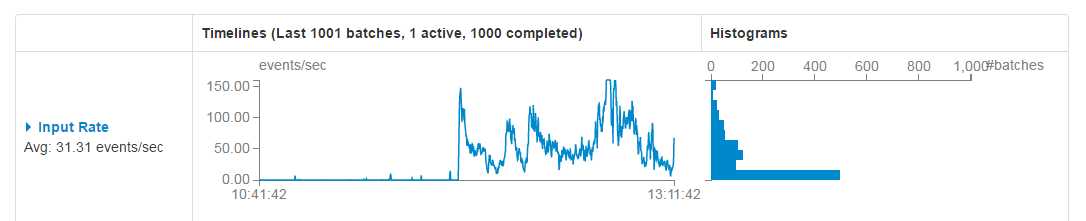

spark.streaming.kafka.maxRatePerPartition这个参数是控制吞吐量的,一般和spark.streaming.backpressure.enabled=true一起使用。那么应该怎么算这个值呢。
如例要10分钟的吞吐量控制在5000,0000,kafka分区是10个。
spark.streaming.kafka.maxRatePerPartition=8400这个值是怎么算的呢。如下是公式
spark.streaming.kafka.maxRatePerPartition的值 * kafka分区数 * (10 *60)(每秒时间)
缓存反复使用的Dstream(RDD)
Spark中的RDD和SparkStreaming中的Dstream,如果被反复的使用,最好利用cache(),将该数据流缓存起来,防止过度的调度资源造成的网络开销。可以参考观察Scheduling Delay参数,如下图:

--conf "spark.executor.extraJavaOptions=-XX:+UseConcMarkSweepGC"
在算子函数中使用到外部变量时,该变量会被序列化后进行网络传输(见“原则七:广播大变量”中的讲解)。
将自定义的类型作为RDD的泛型类型时(比如JavaRDD,Student是自定义类型),所有自定义类型对象,都会进行序列化。因此这种情况下,也要求自定义的类必须实现Serializable接口。
使用可序列化的持久化策略时(比如MEMORY_ONLY_SER),Spark会将RDD中的每个partition都序列化成一个大的字节数组。
对于这三种出现序列化的地方,我们都可以通过使用Kryo序列化类库,来优化序列化和反序列化的性能。Spark默认使用的是Java的序列化机制,也就是ObjectOutputStream/ObjectInputStream API来进行序列化和反序列化。但是Spark同时支持使用Kryo序列化库,Kryo序列化类库的性能比Java序列化类库的性能要高很多。官方介绍,Kryo序列化机制比Java序列化机制,性能高10倍左右。Spark之所以默认没有使用Kryo作为序列化类库,是因为Kryo要求最好要注册所有需要进行序列化的自定义类型,因此对于开发者来说,这种方式比较麻烦。
以下是使用Kryo的代码示例,我们只要设置序列化类,再注册要序列化的自定义类型即可(比如算子函数中使用到的外部变量类型、作为RDD泛型类型的自定义类型等):
// 创建SparkConf对象。
val conf = new SparkConf().setMaster(...).setAppName(...)
// 设置序列化器为KryoSerializer。
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
// 注册要序列化的自定义类型。
conf.registerKryoClasses(Array(classOf[MyClass1], classOf[MyClass2]))
结果
经过种种调试优化,我们最终要达到的目的是,Spark Streaming能够实时的拉取Kafka当中的数据,并且能够保持稳定,如下图所示:
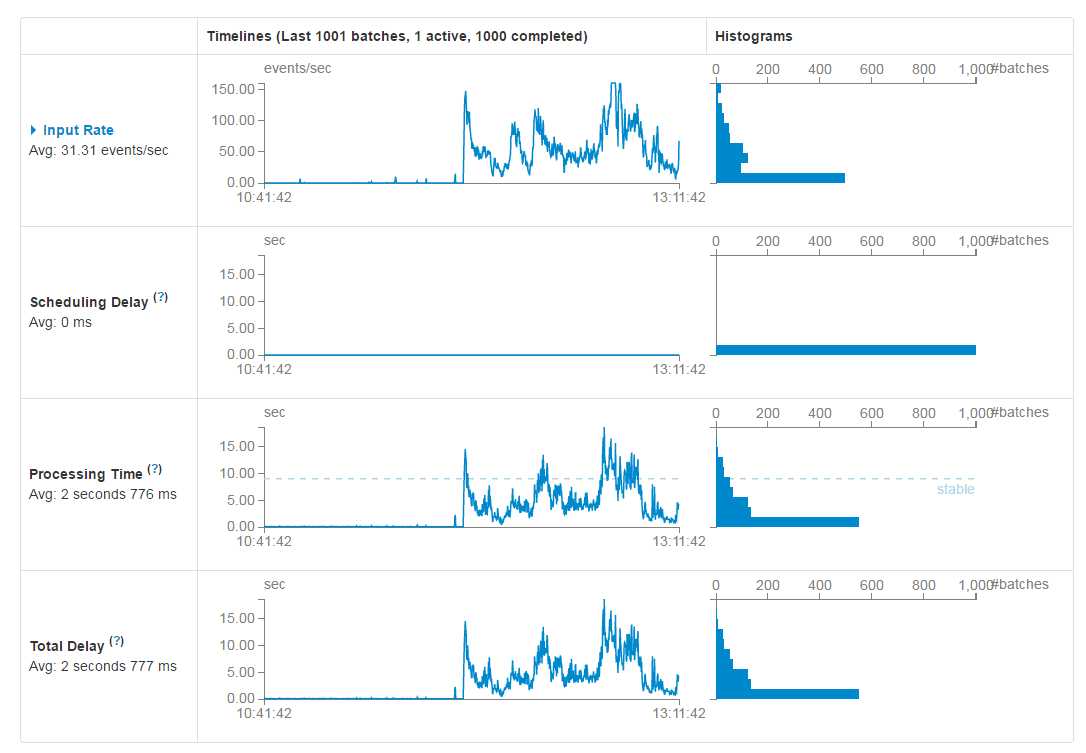
当然不同的应用场景会有不同的图形,这是本文词频统计优化稳定后的监控图,我们可以看到Processing Time这一柱形图中有一Stable的虚线,而大多数Batch都能够在这一虚线下处理完毕,说明整体Spark Streaming是运行稳定的。
附:
使用SparkStreaming集成kafka时有几个比较重要的参数:
(1)spark.streaming.stopGracefullyOnShutdown (true / false)默认fasle
确保在kill任务时,能够处理完最后一批数据,再关闭程序,不会发生强制kill导致数据处理中断,没处理完的数据丢失
(2)spark.streaming.backpressure.enabled (true / false) 默认false
开启后spark自动根据系统负载选择最优消费速率
(3)spark.streaming.backpressure.initialRate (整数) 默认直接读取所有
在(2)开启的情况下,限制第一次批处理应该消费的数据,因为程序冷启动 队列里面有大量积压,防止第一次全部读取,造成系统阻塞
(4)spark.streaming.kafka.maxRatePerPartition (整数) 默认直接读取所有
限制每秒每个消费线程读取每个kafka分区最大的数据量
注意:
只有(4)激活的时候,每次消费的最大数据量,就是设置的数据量,如果不足这个数,就有多少读多少,如果超过这个数字,就读取这个数字的设置的值
只有(2)+(4)激活的时候,每次消费读取的数量最大会等于(4)设置的值,最小是spark根据系统负载自动推断的值,消费的数据量会在这两个范围之内变化根据系统情况,但第一次启动会有多少读多少数据。此后按(2)+(4)设置规则运行
(2)+(3)+(4)同时激活的时候,跟上一个消费情况基本一样,但第一次消费会得到限制,因为我们设置第一次消费的频率了。
参考:
https://www.jianshu.com/p/2623a145c508
https://blog.csdn.net/u010454030/article/details/54629049
原文:https://www.cnblogs.com/fnlingnzb-learner/p/13429625.html