哎,最近有点忙,备考复习不利,明天还要搬家,好难啊!!

本想着这周鸽了,但是想想还是不行,爬起来,更新一下,周更可不能断。偷懒一下,修改一下之前的一篇历史文章,重新发布一下。
ps: 发这篇文章的时候,正在打加赛,JD 加油!!
这是一个真实的生产事件,事件起因如下:
现有一个交易系统,每次产生交易都会更新相应账户的余额,出账扣减余额,入账增加余额。
为了保证资金安全,余额发生扣减时,需要比较现有余额与扣减金额大小,若扣减金额大于现有余额,扣减余额不足,扣减失败。
账户表(省去其他字段)结构如下:
CREATE TABLE `account`
(
`id` bigint(20) NOT NULL,
`balance` bigint(20) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4
COLLATE = utf8mb4_bin;扣减余额时,sql 语序如下所示:

ps:看到上面的语序,有没有个小问号?为什么相同查询了这么多次?
其实这些 SQL 语序并不在同个方法内,并且有些方法被抽出复用,所以导致一些相同查询结果没办法往下传递,所以只得再次从数据库中查询。
为了防止并发更新余额,在 t3 时刻,使用写锁锁住该行记录。若加锁成功,其他线程的若也执行到 t3,将会被阻塞,直到前一个线程事务提交。
t5 时刻,进入到下一个方法,再次获取账户余额,然后在 Java 方法内比较余额与扣减金额,若余额充足,在 t7 时刻执行更新操作。
上面的 SQL 语序看起来没有什么问题吧,实际也是这样的,账户系统已经在生产运行很久,没出现什么问题。但是这里需要说一个前提,系统数据库是 Oracle 。
但是从上面表结构,可以得知此次数据库被切换成 MySQL,系统其他任何代码以及配置都不修改(sql 存在小改动)。
就是这种情况下,并发执行发生余额多扣,即实际余额明明小于扣减金额,但是却做了余额更新操作,最后导致余额变成了负数。

下面我们来重现并发这种情况,假设有两个事务正在发执行该语序,执行顺序如图所示。
注意点:数据库使用的是 MySQL,默认事务隔离等级,即 RR。数据库记录为 id=1 balance=1000,假设只有当时只有这两个事务在执行。
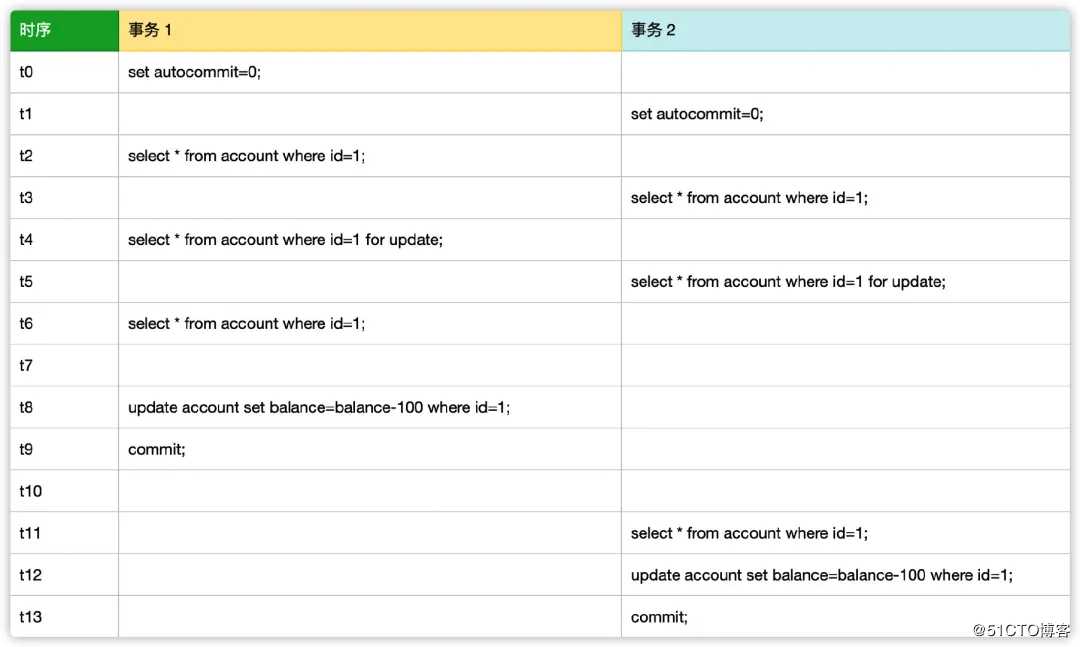
各位读者可以先思考一下,t2,t3,t4,t5,t6,t11 时刻余额多少。
下面贴一下事务隔离等级RR 下的答案。
事务 1 的查询结果为:
事务 2 的查询结果为:
有没有跟你想的结果的一样?
接着将事务隔离等级修改成 RC,同样再来思考一下 t2,t3,t4,t5,t6,t11 时刻余额。
再次贴下事务隔离等级RC 下的答案。
事务 1 的查询结果为:
事务 2 的查询结果为:
事务 1 的查询结果,大家应该会没有什么问题,主要疑问点应该在于事务 2,为什么换了事务隔离等级结果却不太一样?
下面我们先带着疑问,了解一下 MySQL 的相关原理 ,看完你就会明白这一切。
我们先来看下一个简单的例子,
事务隔离等级为 RR , id=1 balance=1000
 更新时序
更新时序
事务 1 将 id=1 记录 balance 更新为 900,接着事务 2 在 t5 时刻查询该行记录结果,很显然该行记录应该为 id=1 balance=1000。
如果 t5 查询最新结果 id=1 balance=900,这就读取到事务 1 未提交的数据,显然不符合当前事务隔离级别。
从上面例子可以看到 id=1 的记录存在两个版本,事务 1 版本记录为 balance=1000 ,事务 2 版本记录为 balance=900。
上述功能,MySQL 使用 MVCC 机制实现功能。
MVCC:Multiversion concurrency control,多版本并发控制。摘录一段淘宝数据库月报的解释:
多版本控制: 指的是一种提高并发的技术。最早的数据库系统,只有读读之间可以并发,读写,写读,写写都要阻塞。引入多版本之后,只有写写之间相互阻塞,其他三种操作都可以并行,这样大幅度提高了 InnoDB 的并发度。在内部实现中,与 Postgres 在数据行上实现多版本不同,InnoDB 是在 undolog 中实现的,通过 undolog 可以找回数据的历史版本。找回的数据历史版本可以提供给用户读(按照隔离级别的定义,有些读请求只能看到比较老的数据版本),也可以在回滚的时候覆盖数据页上的数据。在 InnoDB 内部中,会记录一个全局的活跃读写事务数组,其主要用来判断事务的可见性。
可以看到 MVCC 主要用来提高并发,还可以用来读取老版本数据。
在学习 MVCC 原理之前,首先我们需要了解 MySQL 记录结构。
 行记录
行记录
如上图所示,account 表一行记录,除了真实数据之外,还会存在三个隐藏字段,用来记录额外信息。
MySQL InnoDB 里面每个事务都会有一个唯一事务 ID,它在事务开始的时候会跟 InnoDB 的事务系统申请的,并且严格按照顺序递增的。
每次事务更新数据时,将会生成一个新的数据版本,然后会把当前的事务 id 赋值给当前记录的 DB_TRX_ID。并且数据更新记录(1,1000---->1,900)将会记录在 undo log(回滚日志)中,然后使用当前记录的 DB_ROLL_PTR 指向 und olog。
这样 MySQL 就可以通过 DB_ROLL_PTR 找到 undolog 推导出之前版本记录内容。
查找过程如下:
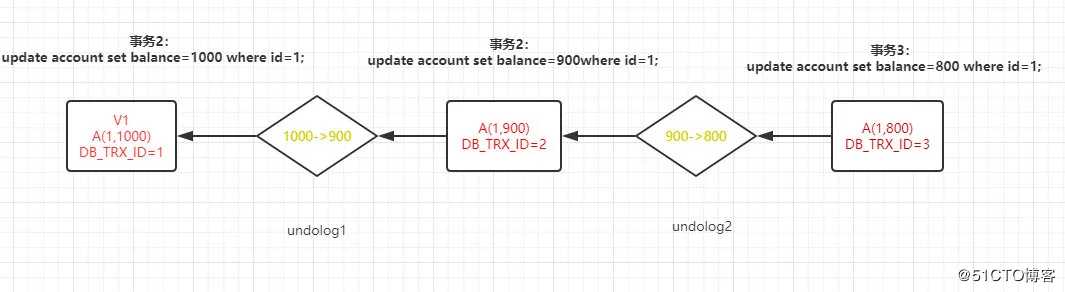
若需要知道 V1 版本记录,首先根据当前版本 V3 的 DB_ROLL_PTR 找到 undolog,然后根据 undolog 内容,计算出上一个版本 V2。以此类推,最终找到 V1 这个版本记录。
V1,V2 并不是物理记录,没有真实存在,仅仅具有逻辑意义。
一行数据记录可能同时存在多个版本,但并不是所有记录都能对当前事务可见。不然上面 t5 就可能查询到最新的数据。所以查找数据版本时候 MySQL 必须判断数据版本是否对当前事务可见。
MySQL 会在事务开始后建立一个一致性视图(并不是立刻建立\),在这个视图中,会保存所有活跃的事务(还未提交的事务\)。
假设当前事务保存活跃事务数组为如下图。
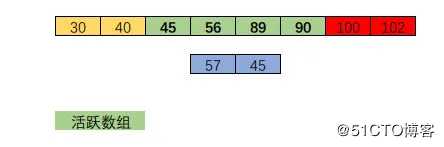
判断版本对于当前事务是否可见时,基于以下规则判断:
4 这个规则可能比较绕,结合上面图片比较好理解。
以上判断规则可能比较抽象,看不懂,没事,我们再用大白话解释一下:
一致性视图只会在 RR 与 RC 下才会生成,对于 RR 来说,一致性视图会在第一个查询语句的时候生成。而对于 RC 来说,每个查询语句都会重新生成视图。
MySQL 使用 MVCC 机制,可以读取之前版本数据。这些旧版本记录不会且也无法再去修改,就像快照一样。所以我们将这种查询称为快照读。
当然并不是所有查询都是快照读,select .... for update/ in share mode 这类加锁查询只会查询当前记录最新版本数据。我们将这种查询称为当前读。
讲完原理之后,我们回过头分析一下上面查询结果的原因。
这里我们将上面答案再贴过来。

事务隔离级别为 RR,t2,t3 时刻两个事务由于查询语句,分别建立了一致性视图。
t4 时刻,由于事务 1 使用 select.. for update 为 id=1 这一行上了一把锁,然后获取到最新结果。而 t5 时刻,由于该行已被上锁,事务 2 必须等待事务 1 释放锁才能继续执行。
t6 时刻根据一致性视图,不能读取到其他事务提交的版本,所以数据没变。t8 时刻余额扣减 100,t9 时刻提交事务。
此时最新版本记录为 id=1 balance=900。
由于事务 1 事务已提交,行锁被释放,t5 成功获取到锁。由于 t5 是当前读,所以查询的结果为最新版本数据(1,900)。
重点来了,当前这条记录的最新版本数据为 (1,900),但是最新版本事务 id,却是事务 2 创建之后未提交的事务,位于活跃事务数组中。所以最新记录版本对于事务 2 是不可见的。
没办法只能根据 undolog 去读取上一版本记录 (1,1000) ,这个版本记录刚好对于事务 2 可见,所以 t11 的记录为 (1,1000)。
而当我们将事务隔离等级修改成 RC,每次都会重新生成一致性视图。所以 t11 时刻重新生成了一致性视图,这时候事务 1 已提交,当前最新版本的记录对于事务 2 可见,所以 t11 的结果将会变为 (1,900)。
MySQL 默认事务隔离等级为 RR,每一行数据(InnoDB)的都可以有多个版本,而每个版本都有独一的事务 id。
MySQL 通过一致性视图确保数据版本的可见性,相关规则总结如下:
[1] https://dev.mysql.com/doc/refman/8.0/en/innodb-multi-versioning.html[2] http://mysql.taobao.org/monthly/2017/12/01/[3] http://mysql.taobao.org/monthly/2018/11/04/[4] https://dev.mysql.com/doc/refman/8.0/en/innodb-consistent-read.html
原文:https://blog.51cto.com/10448399/2516617