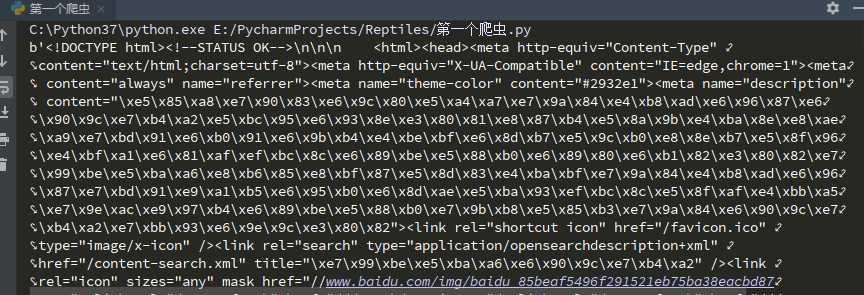
1 from urllib import request 2 3 url = r‘http://www.baidu.com‘ 4 5 # 发送请求,获取 6 response = request.urlopen(url).read() 7 8 # 1、打印获取信息 9 print(response) 10 11 # 2、打印获取信息的长度 12 print(len(response))
1 # 数据清洗,用【正则表达式】进行数据清洗 2 from urllib import request 3 import re # 正则表达式模块 4 5 url = r‘http://www.baidu.com‘ 6 7 # 发送请求,获取 8 response = request.urlopen(url).read().decode() # 解码---(编码endecode()) 9 10 # 1、获取title标签的内容 11 pat = r‘<title>(.*?)</title>‘ 12 13 data = re.findall(pat,response) 14 15 print(data)


原文:https://www.cnblogs.com/zibinchen/p/13436630.html