Scrapy一个开源和协作的框架,其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的,使用它可以以快速、简单、可扩展的方式从网站中提取所需的数据。但目前Scrapy的用途十分广泛,可用于如数据挖掘、监测和自动化测试等领域,也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。
Scrapy 是基于twisted框架开发而来,twisted是一个流行的事件驱动的python网络框架。因此Scrapy使用了一种非阻塞(又名异步)的代码来实现并发。整体架构大致如下
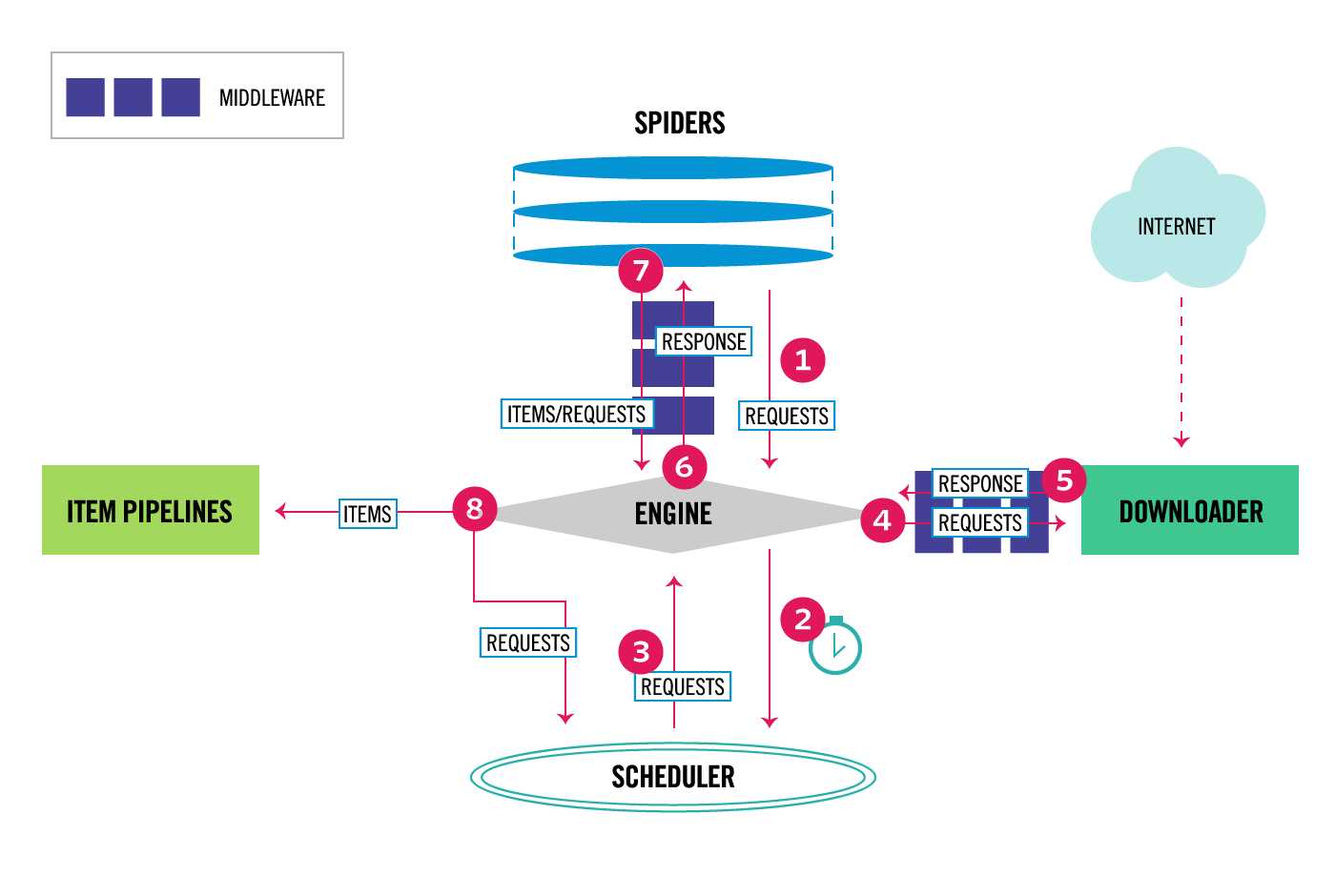
Components:
引擎负责控制系统所有组件之间的数据流,并在某些动作发生时触发事件。有关详细信息,请参见上面的数据流部分。
官网链接:https://docs.scrapy.org/en/latest/topics/architecture.html
总结:
#1 通用的网络爬虫框架,爬虫界的django #2 scrapy执行流程 5大组件 -引擎(EGINE):大总管,负责控制数据的流向 -调度器(SCHEDULER):由它来决定下一个要抓取的网址是什么,去重 -下载器(DOWLOADER):用于下载网页内容, 并将网页内 容返回给EGINE,下载器是建立在twisted这个高效的异步模型上的 -爬虫(SPIDERS):开发人员自定义的类,用来解析responses,并且提取items,或者发送新的请求request -项目管道(ITEM PIPLINES):在items被提取后负责处理它们,主要包括清理、验证、持久化(比如存到数据库)等操作 2大中间件 -爬虫中间件:位于EGINE和SPIDERS之间,主要工作是处理SPIDERS的输入和输出(用的很少) -下载中间件:引擎和下载器之间,加代理,加头,集成selenium # 3 开发者只需要在固定的位置写固定的代码即可(写的最多的spider)
原文:https://www.cnblogs.com/baicai37/p/13439700.html