C/C++ 宏编程的艺术原文:《C/C++ 宏编程的艺术》,公众号 BOTManJL~

可以言传者,物之粗也;可以意致者,物之精也。——《庄子 · 秋水》
之前写过几篇关于 C/C++ 宏 (macro) 和 C++ 元编程 (metaprogramming) 的文章:
C++ 模板元编程 (template metaprogramming) 虽然功能强大,但也有 局限性:
所以,在需要直接 操作标识符 的情况下,还需要借助 宏,进行 预处理阶段的元编程:
#define/TOKEN1##TOKEN2/#TOKEN 定义 宏对象 (object-like macro) 和 宏函数 (function-like macro),可以实现 替换文本、拼接标识符、获取字面量 等功能最近,需要在单元测试中 自动生成调用 gmock 的代码:

介绍宏编程之前,先聊聊调试的问题。
很多人因为 “宏编程” 无法调试,而直接 “从入门到放弃” —— 不经意的 符号拼写错误、参数个数错误,导致文本 不能正确替换,从而带来 满屏的编译错误,最后 难以定位 问题所在 ——
由于宏代码会 在编译前全部展开,我们可以:
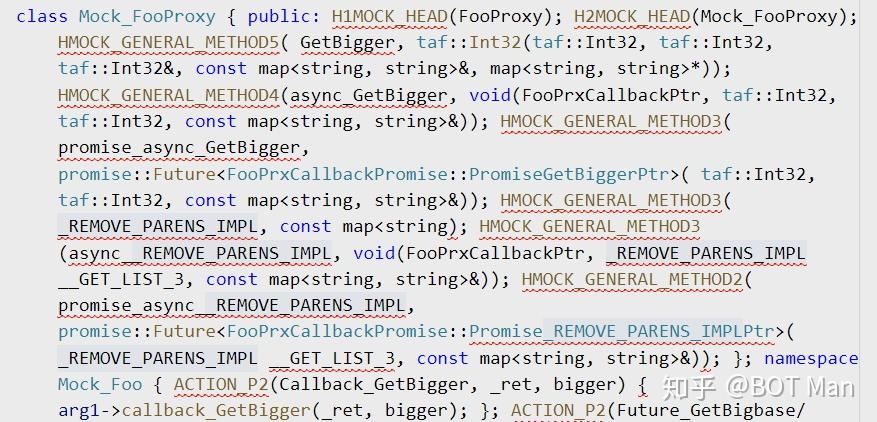
gcc -E 让编译器 在预处理结束后停止,不进行 编译、链接gcc -P 屏蔽编译器 输出预处理结果的 行标记 (linemarker),减少干扰clang-format 格式化后再输出#include 行于是,展开错误一目了然(很容易发现 _REMOVE_PARENS_IMPL 的展开错误):
和模板元编程不一样,宏编程 没有类型 的概念,输入和输出都是 符号 —— 不涉及编译时的 C++ 语法,只进行编译前的 文本替换:
a + 1 和 a+1 相同)FOO(bool, std::pair<int, int>) 被认为是 FOO() 有三个参数:bool / std::pair<int / int>)如果需要把 std::pair<int, int> 作为一个参数,一种方法是使用 C++ 的 类型别名 (type alias)(例如 using IntPair = std::pair<int, int>;),避免 参数中出现逗号(即 FOO(bool, IntPair) 只有两个参数)。
更通用的方法是使用 括号对 封装每个参数(下文称为 元组),并在最终展开时 移除括号(元组解包)即可:
#define PP_REMOVE_PARENS(T) PP_REMOVE_PARENS_IMPL T
#define PP_REMOVE_PARENS_IMPL(...) __VA_ARGS__
#define FOO(A, B) int foo(A x, B y)
#define BAR(A, B) FOO(PP_REMOVE_PARENS(A), PP_REMOVE_PARENS(B))
FOO(bool, IntPair) // -> int foo(bool x, IntPair y)
BAR((bool), (std::pair<int, int>)) // -> int foo(bool x, std::pair<int, int> y)
PP_REMOVE_PARENS(T) 展开为 PP_REMOVE_PARENS_IMPL T 的形式T 是一个 括号对,那么展开结果会变成 调用宏函数PP_REMOVE_PARENS_IMPL (...) 的形式PP_REMOVE_PARENS_IMPL(...) 再展开为参数本身 __VA_ARGS__(下文提到的 变长参数),即元组 T 的内容另外,常用宏函数 代替 特殊符号,用于下文提到的 惰性求值:
#define PP_COMMA() ,
#define PP_LPAREN() (
#define PP_RPAREN() )
#define PP_EMPTY()
在宏编程中,拼接标识符 (identifier concatenation / token pasting) 通过 ## 将宏函数的参数 拼接成其他符号,再进一步 展开为目标结果,是宏编程的 实现基础。
然而,如果一个 宏参数 用于 拼接标识符(或 获取字面量),那么它不会被展开(例如 BAR() 在拼接前不会展开为 bar):
#define FOO(SYMBOL) foo_ ## SYMBOL
#define BAR() bar
FOO(bar) // -> foo_bar
FOO(BAR()) // -> foo_BAR()
一种通用的方法是 延迟拼接操作(或 延迟 获取字面量 操作):
#define PP_CONCAT(A, B) PP_CONCAT_IMPL(A, B)
#define PP_CONCAT_IMPL(A, B) A##B
#define FOO(N) PP_CONCAT(foo_, N)
FOO(bar) // -> foo_bar
FOO(BAR()) // -> foo_bar
PP_CONCAT() 先展开参数,再传递给 PP_CONCAT_IMPL() 进行 实际拼接延伸阅读:使用 C++ 宏嵌套实现窄字符转换为宽字符 by bingoli 提到了 Win32 的 TEXT() 宏的原理。
另外,在 预扫描前后,宏函数都要求 参数个数必须匹配,否则无法展开:
PP_CONCAT(x PP_COMMA() y) // too few arguments (before prescan)
PP_CONCAT(x, PP_COMMA()) // too many arguments (after prescan)
x PP_COMMA() y 是一个参数x, PP_COMMA() 是三个参数借助 PP_CONCAT(),我们可以实现 非负整数增减(即 INC(N) = N + 1 / DEC(N) = N - 1):
#define PP_INC(N) PP_CONCAT(PP_INC_, N)
#define PP_INC_0 1
#define PP_INC_1 2
// ...
#define PP_INC_254 255
#define PP_INC_255 256
#define PP_DEC(N) PP_CONCAT(PP_DEC_, N)
#define PP_DEC_256 255
#define PP_DEC_255 254
// ...
#define PP_DEC_2 1
#define PP_DEC_1 0
PP_INC(1) // -> 2
PP_DEC(2) // -> 1
PP_INC(256) // -> PP_INC_256 (overflow)
PP_DEC(0) // -> PP_DEC_0 (underflow)
PP_INC(N)/PP_DEC(N) 先展开为 PP_INC_N/PP_DEC_N,再经过 二次扫描 展开为对应数值 N + 1/N - 1 的符号借助 PP_CONCAT(),我们可以实现 布尔类型(0 和 1)的 逻辑运算(与 / 或 / 非 / 异或 / 同或):
#define PP_NOT(N) PP_CONCAT(PP_NOT_, N)
#define PP_NOT_0 1
#define PP_NOT_1 0
#define PP_AND(A, B) PP_CONCAT(PP_AND_, PP_CONCAT(A, B))
#define PP_AND_00 0
#define PP_AND_01 0
#define PP_AND_10 0
#define PP_AND_11 1
PP_AND(PP_NOT(0), 1) // -> 1
PP_AND(PP_NOT(2), 0) // -> PP_AND_PP_NOT_20
PP_INC()/PP_DEC() 类似(符号拼接 + 二次展开)0 和 1)PP_NOT_2 来支持 PP_NOT(2),宏代码会急剧膨胀PP_NOT() 需要考虑 $N$ 种组合PP_AND() 则要考虑 $N^2$ 种组合为了支持更通用的 非负整数 的逻辑运算,可以先 将整数 转换成 布尔类型,而不是扩展 布尔类型 的逻辑运算:
#define PP_BOOL(N) PP_CONCAT(PP_BOOL_, N)
#define PP_BOOL_0 0
#define PP_BOOL_1 1
#define PP_BOOL_2 1
// ...
PP_AND(PP_NOT(PP_BOOL(2)), PP_BOOL(0)) // -> 0
PP_NOT(PP_BOOL(1000)) // -> PP_NOT_PP_BOOL_1000
PP_INC()/PP_DEC() 类似(符号拼接 + 二次展开)借助 PP_CONCAT() 和 PP_BOOL(),我们可以实现通用的 条件选择 表达式(PRED ? THEN : ELSE,其中 PRED 可以是 任意非负整数):
#define PP_IF(PRED, THEN, ELSE) PP_CONCAT(PP_IF_, PP_BOOL(PRED))(THEN, ELSE)
#define PP_IF_1(THEN, ELSE) THEN
#define PP_IF_0(THEN, ELSE) ELSE
#define DEC_SAFE(N) PP_IF(N, PP_DEC(N), 0)
DEC_SAFE(2) // -> 1
DEC_SAFE(1) // -> 0
DEC_SAFE(0) // -> 0
PP_IF() 先会根据转换后的条件 PP_BOOL(PRED) 选择 PP_IF_1 或 PP_IF_0 符号PP_IF_1()/PP_IF_0() 接受相同的参数,但分别展开为 THEN 或 ELSE 参数需要注意 PP_IF() 的参数会在 预扫描 阶段被完全展开(例如 PP_COMMA() 会被立即展开为逗号,导致参数个数错误):
#define PP_COMMA_IF(N) PP_IF(N, PP_COMMA(), PP_EMPTY())
PP_COMMA_IF(1) // -> PP_IF(1, , , ) (too many arguments after prescan)
常用的技巧是 惰性求值 (lazy evaluation),即 条件选择先 返回宏函数,再传递参数 延迟调用:
#define PP_COMMA_IF(N) PP_IF(N, PP_COMMA, PP_EMPTY)()
PP_COMMA_IF(0) // (empty)
PP_COMMA_IF(1) // -> ,
PP_COMMA_IF(2) // -> ,
#define SURROUND(N) PP_IF(N, PP_LPAREN, [ PP_EMPTY)() N PP_IF(N, PP_RPAREN, ] PP_EMPTY)()
SURROUND(0) // -> [0]
SURROUND(1) // -> (1)
SURROUND(2) // -> (2)
PP_COMMA_IF() 先借助 PP_IF() 返回 PP_COMMA 或 PP_EMPTY 符号PP_COMMA/PP_EMPTY 和后边的括号对 组成 PP_COMMA()/PP_EMPTY(),再继续展开为 逗号 或 空SYMBOL,可以使用 SYMBOL PP_EMPTY 作为参数,和后边的括号对 组成 PP_EMPTY()(例如 SURROUND() 使用的 [ 和 ])从 C++ 11 开始,宏函数支持了 变长参数 ...,接受任意个 宏参数(用逗号分隔):
__VA_ARGS__ 获取(也可以通过 #__VA_ARGS__ 获取 逗号 + 空格分隔 的参数字面量)__VA_ARGS__ 替换为空对于空参数,展开时需要处理 多余逗号 的问题:
#define log(format, ...) printf("LOG: " format, __VA_ARGS__)
log("%d%f", 1, .2); // -> printf("LOG: %d%f", 1, .2);
log("hello world"); // -> printf("LOG: hello world", );
log("hello world", ); // -> printf("LOG: hello world", );
为了解决这个问题,一些编译器(例如 gcc/clang)扩展了 , ## __VA_ARGS__ 的用法 —— 如果 不传变长参数,则省略前面的逗号:
#define log(format, ...) printf("LOG: " format, ## __VA_ARGS__)
log("%d%f", 1, .2); // -> printf("LOG: %d%f", 1, .2);
log("hello world"); // -> printf("LOG: hello world");
log("hello world", ); // -> printf("LOG: hello world", );
为了进一步处理 变长参数为空 的情况,C++ 20 引入了 __VA_OPT__ 标识符 —— 如果变长参数是空参数,不展开该符号(不仅限于逗号):
#define log(format, ...) printf("LOG: " format __VA_OPT__(,) __VA_ARGS__)
log("%d%f", 1, .2); // -> printf("LOG: %d%f", 1, .2);
log("hello world"); // -> printf("LOG: hello world");
log("hello world", ); // -> printf("LOG: hello world");
下文将借助 长度判空 和 遍历访问,实现 __VA_OPT__(,) 的功能。
借助 PP_CONCAT(),我们可以通过 下标访问 变长参数的 特定元素:
#define PP_GET_N(N, ...) PP_CONCAT(PP_GET_N_, N)(__VA_ARGS__)
#define PP_GET_N_0(_0, ...) _0
#define PP_GET_N_1(_0, _1, ...) _1
#define PP_GET_N_2(_0, _1, _2, ...) _2
// ...
#define PP_GET_N_8(_0, _1, _2, _3, _4, _5, _6, _7, _8, ...) _8
PP_GET_N(0, foo, bar) // -> foo
PP_GET_N(1, foo, bar) // -> bar
PP_GET_N() 的参数分为两部分:下标 N 和 变长参数 ...PP_CONCAT() 选择下标 I(从 0 开始)对应的 PP_GET_N_I 符号PP_GET_N_I() 接受至少 I + 1 个参数(其余的参数是变长参数),并返回第 I + 1 个参数(其余的变长参数直接丢弃)借助 PP_REMOVE_PARENS(),我们还可以通过 下标访问 元组 的特定元素:
#define PP_GET_TUPLE(N, T) PP_GET_N(N, PP_REMOVE_PARENS(T))
PP_GET_TUPLE(0, (foo, bar)) // -> foo
PP_GET_TUPLE(1, (foo, bar)) // -> bar
需要注意 变长参数的 长度必须大于 N,否则无法展开:
#define FOO(P, T) PP_IF(P, PP_GET_TUPLE(1, T), PP_GET_TUPLE(0, T))
FOO(0, (foo, bar)) // -> foo
FOO(1, (foo, bar)) // -> bar
FOO(0, (baz)) // -> PP_GET_N_1(baz) (too few arguments)
P == 0 的情况,FOO() 只返回 T 的第一个元素PP_GET_TUPLE(1, T) 仍会被展开,从而要求 T 有至少两个元素类似的,我们可以借助 惰性求值 避免该问题:
#define FOO(P, T) PP_IF(P, PP_GET_N_1, PP_GET_N_0) T
FOO(0, (foo, bar)) // -> foo
FOO(1, (foo, bar)) // -> bar
FOO(0, (baz)) // -> baz
PP_IF() 先返回 PP_GET_N_1 或 PP_GET_N_0 符号PP_REMOVE_PARENS(),再用 PP_GET_N_I (...) 元组解包P == 0 的情况,不会展开 PP_GET_N_1() 宏借助 PP_GET_N(),我们可以检查 变长参数是否为空:
#define PP_IS_EMPTY(...) PP_AND(PP_AND(PP_NOT(PP_HAS_COMMA(__VA_ARGS__)), PP_NOT(PP_HAS_COMMA(__VA_ARGS__()))), PP_AND(PP_NOT(PP_HAS_COMMA(PP_COMMA_V __VA_ARGS__)), PP_HAS_COMMA(PP_COMMA_V __VA_ARGS__())))
#define PP_HAS_COMMA(...) PP_GET_N_8(__VA_ARGS__, 1, 1, 1, 1, 1, 1, 1, 0, 0)
#define PP_COMMA_V(...) ,
PP_IS_EMPTY() // -> 1
PP_IS_EMPTY(foo) // -> 0
PP_IS_EMPTY(foo()) // -> 0
PP_IS_EMPTY(()) // -> 0
PP_IS_EMPTY(()foo) // -> 0
PP_IS_EMPTY(PP_EMPTY) // -> 0
PP_IS_EMPTY(PP_COMMA) // -> 0
PP_IS_EMPTY(, ) // -> 0
PP_IS_EMPTY(foo, bar) // -> 0
PP_IS_EMPTY(, , , ) // -> 0
PP_HAS_COMMA() 用于检查变长参数里 有没有逗号(原理类似下文的 PP_NARG())PP_COMMA_V() 用于 吃掉 (eat) 变长参数,并返回一个 逗号PP_COMMA_V __VA_ARGS__() 展开为逗号,即构成 PP_COMMA_V() 的形式__VA_ARGS__、__VA_ARGS__() 和 PP_COMMA_V __VA_ARGS__ 展开结果里 没有逗号,排除对上一个条件的干扰借助 PP_COMMA_IF() 和 PP_IS_EMPTY(),我们可以实现 C++ 20 的 __VA_OPT__(,) 功能:
#define PP_VA_OPT_COMMA(...) PP_COMMA_IF(PP_NOT(PP_IS_EMPTY(__VA_ARGS__)))
#define log(format, ...) printf("LOG: " format PP_VA_OPT_COMMA(__VA_ARGS__) __VA_ARGS__)
log("%d%f", 1, .2); // -> printf("LOG: %d%f", 1, .2);
log("hello world"); // -> printf("LOG: hello world");
log("hello world", ); // -> printf("LOG: hello world");
借助 PP_GET_N() 和 PP_VA_OPT_COMMA(),我们可以计算 变长参数的个数(长度):
#define PP_NARG(...) PP_GET_N(8, __VA_ARGS__ PP_VA_OPT_COMMA(__VA_ARGS__) 8, 7, 6, 5, 4, 3, 2, 1, 0)
PP_NARG() // -> 0
PP_NARG(foo) // -> 1
PP_NARG(foo()) // -> 1
PP_NARG(()) // -> 1
PP_NARG(()foo) // -> 1
PP_NARG(PP_EMPTY) // -> 1
PP_NARG(PP_COMMA) // -> 1
PP_NARG(, ) // -> 2
PP_NARG(foo, bar) // -> 2
PP_NARG(, , , ) // -> 4
__VA_ARGS__ PP_VA_OPT_COMMA(__VA_ARGS__) 和 8, ..., 0 一起传给 PP_GET_N(8, ...)__VA_ARGS__ 为空,等价与 PP_GET_N(8, 8, ..., 0),直接返回 第九个元素 0__VA_ARGS__ 非空,等价于 PP_GET_N(8, __VA_ARGS__, 8, ..., 0),变长参数 __VA_ARGS__ 把 8, ..., 0 向后推移,使得返回的 第九个元素 刚好是 __VA_ARGS__ 的参数个数8)另外,这里只能用 PP_GET_N(8, ...),而不能用 PP_GET_N_8():
PP_GET_N(0, 1 PP_COMMA() 2) // -> 1
PP_GET_N_0(1 PP_COMMA() 2) // -> 1 , 2
PP_GET_N_8(),没被展开的 __VA_ARGS__ PP_VA_OPT_COMMA(__VA_ARGS__) 8 会被当成 包含逗号 的 一个参数,而不是 多个参数PP_GET_N() 在把 __VA_ARGS__ 转发给 PP_GET_N_8() 时,会把 上述参数 展开为 多个参数借助 PP_CONCAT() 和 PP_NARG(),我们可以 遍历 (traverse) 变长参数:
#define PP_FOR_EACH(DO, CTX, ...) PP_CONCAT(PP_FOR_EACH_, PP_NARG(__VA_ARGS__))(DO, CTX, 0, __VA_ARGS__)
#define PP_FOR_EACH_0(DO, CTX, IDX, ...)
#define PP_FOR_EACH_1(DO, CTX, IDX, VAR, ...) DO(VAR, IDX, CTX)
#define PP_FOR_EACH_2(DO, CTX, IDX, VAR, ...) DO(VAR, IDX, CTX) PP_FOR_EACH_1(DO, CTX, PP_INC(IDX), __VA_ARGS__)
#define PP_FOR_EACH_3(DO, CTX, IDX, VAR, ...) DO(VAR, IDX, CTX) PP_FOR_EACH_2(DO, CTX, PP_INC(IDX), __VA_ARGS__)
// ...
#define DO_EACH(VAR, IDX, CTX) PP_COMMA_IF(IDX) CTX VAR
PP_FOR_EACH(DO_EACH, void, ) // (empty)
PP_FOR_EACH(DO_EACH, int, a, b, c) // -> int a, int b, int c
PP_FOR_EACH(DO_EACH, bool, x) // -> bool x
PP_FOR_EACH() 的参数分为三部分:元素的转换操作 DO、遍历的上下文参数 CTX 和 变长参数 ...DO() 接受三个参数:当前元素 VAR、对应下标 IDX 和 遍历的上下文 CTX,并返回元素 VAR 转换后的结果PP_CONCAT() 和 PP_NARG() 选择 变长参数长度 对应的 PP_FOR_EACH_I 符号PP_FOR_EACH_I() 的参数分为四部分:元素的转换操作 DO、遍历的上下文参数 CTX、当前元素下标 IDX 和 变长参数 ...DO() 和 变长参数 剩余元素 递归调用 I - 1 宏(下标更新为 IDX + 1)I == 0 时,展开为空,递归终止借助 PP_FOR_EACH() 和 上边的 DO_EACH()(借助其 PP_COMMA_IF(),并忽略 CTX),我们可以实现等效于 PP_VA_OPT_COMMA() 的功能:
#define log(format, ...) printf("LOG: " format PP_FOR_EACH(DO_EACH, , __VA_ARGS__))
log("%d%f", 1, .2); // -> printf("LOG: %d%f", 1, .2);
log("hello world"); // -> printf("LOG: hello world");
log("hello world", ); // -> printf("LOG: hello world");
借助 PP_CONCAT() 和 PP_IS_EMPTY(),我们可以 匹配任意的特定符号:
#define PP_IS_SYMBOL(PREFIX, SYMBOL) PP_IS_EMPTY(PP_CONCAT(PREFIX, SYMBOL))
#define IS_VOID_void
PP_IS_SYMBOL(IS_VOID_, void) // -> 1
PP_IS_SYMBOL(IS_VOID_, ) // -> 0
PP_IS_SYMBOL(IS_VOID_, int) // -> 0
PP_IS_SYMBOL(IS_VOID_, void*) // -> 0
PP_IS_SYMBOL(IS_VOID_, void x) // -> 0
PP_IS_SYMBOL(IS_VOID_, void(int, int)) // -> 0
IS_VOID_void:字面量是前缀 IS_VOID_ 和 目标结果 void的拼接,展开为空PP_CONCAT(PREFIX, SYMBOL) 把 前缀 和 参数 拼接为新的符号,并用 PP_IS_EMPTY() 检查拼接结果 展开后是否为空SYMBOL 是单个符号 void,才能展开为空借助 PP_IS_EMPTY(),我们还可以 检查符号序列 是否是元组:
#define PP_EMPTY_V(...)
#define PP_IS_PARENS(SYMBOL) PP_IS_EMPTY(PP_EMPTY_V SYMBOL)
PP_IS_PARENS() // -> 0
PP_IS_PARENS(foo) // -> 0
PP_IS_PARENS(foo()) // -> 0
PP_IS_PARENS(()foo) // -> 0
PP_IS_PARENS(()) // -> 1
PP_IS_PARENS((foo)) // -> 1
PP_IS_PARENS(((), foo, bar)) // -> 1
PP_EMPTY_V():用于 吃掉 变长参数,展开为空PP_IS_EMPTY() 检查 PP_EMPTY_V SYMBOL 拼接结果 展开后是否为空SYMBOL 符合 (...) 的形式,PP_EMPTY_V (...) 才能展开为空在 gmock-1.10.0 中,MOCK_METHOD() 借助 PP_IS_PARENS(),自动识别 参数是不是元组,再进行 选择性的 元组解包 —— 使用时可以只把 包含逗号的参数 变为元组,而其他参数保持不变:
#define PP_IDENTITY(N) N
#define TRY_REMOVE_PARENS(T) PP_IF(PP_IS_PARENS(T), PP_REMOVE_PARENS, PP_IDENTITY)(T)
#define FOO(A, B) int foo(A x, B y)
#define BAR(A, B) FOO(TRY_REMOVE_PARENS(A), TRY_REMOVE_PARENS(B))
FOO(bool, IntPair) // -> int foo(bool x, IntPair y)
BAR(bool, IntPair) // -> int foo(bool x, IntPair y)
BAR(bool, (std::pair<int, int>)) // -> int foo(bool x, std::pair<int, int> y)
由于 变长参数 只能表示 一维数据,如果需要处理 嵌套的多维数据,还需要高级的数据结构(例如 列表的每一项 包含多个属性,而每个属性 又是一个列表;参考 下文的 递归重入提到的 嵌套元组)。
BOOST_PP 定义了四种数据结构:
nil 标识结束符例如,一组数据的三个元素 分别是 f(12) / a + 1 / foo:
(f(12), a + 1, foo)(f(12))(a + 1)(foo)(f(12), (a + 1, (foo, PP_NIL)))(3, (f(12), a + 1, foo))另外,元组 () 表示 包含一个空元素的 一元组,而不是 不包含任何元素的 空元组(序列、列表、数组 不涉及这个问题)。
关于上述数据结构的基本运算(下标访问、长度计算、遍历访问、增删元素、类型转换),推荐阅读 BOOST_PP 源码。
因为自参照宏 (self referential macro) 不会被展开 —— 在展开一个宏时,如果遇到 当前宏 的符号,则不会继续展开,避免无限展开(infinite expansion)—— 所以宏不支持 递归 / 重入。
例如,PP_FOR_EACH() 在遍历 两层嵌套元组 时,DO_EACH_1() 无法展开 内层元组,结果保留 PP_FOR_EACH(...) 的形式:
#define OUTER(N, T) PP_FOR_EACH(DO_EACH_1, N, PP_REMOVE_PARENS(T))
#define DO_EACH_1(VAR, IDX, CTX) PP_FOR_EACH(DO_EACH_2, CTX.PP_GET_TUPLE(0, VAR), PP_REMOVE_PARENS(PP_GET_TUPLE(1, VAR)))
#define DO_EACH_2(VAR, IDX, CTX) CTX .VAR = VAR;
// -> PP_FOR_EACH(DO_EACH_2, obj.x, x1, x2) PP_FOR_EACH(DO_EACH_2, obj.y, y1)
OUTER(obj, ((x, (x1, x2)), (y, (y1))))
一种解决方法是,在 预扫描 阶段,先展开 内层元组,再把展开结果 作为参数,传递给 外层元组,从而避免 递归调用(但不一定适用于所有场景):
#define OUTER(N, T) PP_FOR_EACH(DO_EACH_1, N, PP_REMOVE_PARENS(T))
#define DO_EACH_1(VAR, IDX, CTX) CTX.VAR;
#define INNER(N, T) PP_FOR_EACH(DO_EACH_2, N, PP_REMOVE_PARENS(T))
#define DO_EACH_2(VAR, IDX, CTX) PP_COMMA_IF(IDX) CTX .VAR = VAR
// -> obj.x.x1 = x1; obj.x.x2 = x2; obj.y.y1 = y1;
OUTER(obj, (INNER(x, (x1, x2)), INNER(y, (y1))))
另一种解决方法是,定义另一个相同功能的宏 PP_FOR_EACH_INNER(),用于内层循环,从而避免和外层循环冲突(如果遍历三层嵌套,则需要再定义一个类似的宏):
#define PP_FOR_EACH_INNER(DO, CTX, ...) PP_CONCAT(PP_FOR_EACH_INNER_, PP_NARG(__VA_ARGS__)) (DO, CTX, 0, __VA_ARGS__)
#define PP_FOR_EACH_INNER_0(DO, CTX, IDX, ...)
#define PP_FOR_EACH_INNER_1(DO, CTX, IDX, VAR, ...) DO(VAR, IDX, CTX)
#define PP_FOR_EACH_INNER_2(DO, CTX, IDX, VAR, ...) DO(VAR, IDX, CTX) PP_FOR_EACH_INNER_1(DO, CTX, PP_INC(IDX), __VA_ARGS__)
// ...
#define OUTER(N, T) PP_FOR_EACH(DO_EACH_1, N, PP_REMOVE_PARENS(T))
#define DO_EACH_1(VAR, IDX, CTX) PP_FOR_EACH_INNER(DO_EACH_2, CTX.PP_GET_TUPLE(0, VAR), PP_REMOVE_PARENS(PP_GET_TUPLE(1, VAR)))
#define DO_EACH_2(VAR, IDX, CTX) CTX .VAR = VAR;
// -> obj.x.x1 = x1; obj.x.x2 = x2; obj.y.y1 = y1;
OUTER(obj, ((x, (x1, x2)), (y, (y1))))
上文提到的 PP_FOR_EACH() 主要用于 遍历 变长参数的元素,输出长度和输入相同。但有时候,我们仍需要一个用于 迭代 (iterate) 的 条件循环 PP_WHILE(),最后只输出一个结果:
#define PP_WHILE PP_WHILE_1
#define PP_WHILE_1(PRED, OP, VAL) PP_IF(PRED(VAL), PP_WHILE_2, VAL PP_EMPTY_V) (PRED, OP, PP_IF(PRED(VAL), OP, PP_EMPTY_V)(VAL))
#define PP_WHILE_2(PRED, OP, VAL) PP_IF(PRED(VAL), PP_WHILE_3, VAL PP_EMPTY_V) (PRED, OP, PP_IF(PRED(VAL), OP, PP_EMPTY_V)(VAL))
#define PP_WHILE_3(PRED, OP, VAL) PP_IF(PRED(VAL), PP_WHILE_4, VAL PP_EMPTY_V) (PRED, OP, PP_IF(PRED(VAL), OP, PP_EMPTY_V)(VAL))
#define PP_WHILE_4(PRED, OP, VAL) PP_IF(PRED(VAL), PP_WHILE_5, VAL PP_EMPTY_V) (PRED, OP, PP_IF(PRED(VAL), OP, PP_EMPTY_V)(VAL))
// ...
#define PRED(VAL) PP_GET_TUPLE(1, VAL)
#define OP(VAL) (PP_GET_TUPLE(0, VAL) + PP_GET_TUPLE(1, VAL), PP_DEC(PP_GET_TUPLE(1, VAL)))
PP_GET_TUPLE(0, PP_WHILE(PRED, OP, (x, 2))) // -> x + 2 + 1
PP_WHILE() 接受三个参数:循环条件谓词 PRED、迭代操作运算 OP 和 初始值 VALPRED() 接受 当前值 VAL 作为参数,并返回 非负整数OP() 接受 当前值 VAL 作为参数,并返回 迭代后的下一个 VAL 值PP_FOR_EACH() 类似,PP_WHILE_I() 根据 PRED(VAL) 选择展开方式PRED(VAL) != 0,递归调用 I + 1 宏,并传入 OP(VAL) 作为 下一轮迭代的 当前值PRED(VAL) == 0,展开为 VAL,并 跳过 OP(VAL),递归终止PP_WHILE 从 PP_WHILE_1 开始迭代和 PP_FOR_EACH() 不同,不需要定义 PP_WHILE_INNER(),就可以在循环展开时重入 —— 如果 当前递归状态 是 I,重入代码可以使用 任意 I 以后的宏:
PP_WHILE_2() 时,只有 PP_WHILE_1 和 PP_WHILE_2 正在展开,所以 PRED()/OP() 可以使用 PP_WHILE_3() 及以后的宏PRED(VAL)/OP(VAL) 只在参数里展开,在下一轮迭代的 PP_WHILE_3() 展开时,不会构成递归调用为了支持方便的递归调用,BOOST_PP 提出了自动推导当前递归状态的方法:
#define PP_WHILE PP_CONCAT(PP_WHILE_, PP_AUTO_DIM(PP_WHILE_CHECK))
#define PP_AUTO_DIM(CHECK) PP_IF(CHECK(2), PP_AUTO_DIM_12, PP_AUTO_DIM_34)(CHECK)
#define PP_AUTO_DIM_12(CHECK) PP_IF(CHECK(1), 1, 2)
#define PP_AUTO_DIM_34(CHECK) PP_IF(CHECK(3), 3, 4)
#define PP_WHILE_CHECK(N) PP_CONCAT(PP_WHILE_CHECK_, PP_WHILE_##N(0 PP_EMPTY_V, , 1))
#define PP_WHILE_CHECK_1 1
#define PP_WHILE_CHECK_PP_WHILE_1(PRED, OP, VAL) 0
#define PP_WHILE_CHECK_PP_WHILE_2(PRED, OP, VAL) 0
#define PP_WHILE_CHECK_PP_WHILE_3(PRED, OP, VAL) 0
#define PP_WHILE_CHECK_PP_WHILE_4(PRED, OP, VAL) 0
// ...
#define OP_1(VAL) (PP_GET_TUPLE(0, PP_WHILE(PRED, OP_2, (PP_GET_TUPLE(0, VAL), PP_GET_TUPLE(1, VAL), PP_GET_TUPLE(1, VAL)))), PP_DEC(PP_GET_TUPLE(1, VAL)))
#define OP_2(VAL) (PP_GET_TUPLE(0, VAL) + PP_GET_TUPLE(2, VAL) * PP_GET_TUPLE(1, VAL), PP_DEC(PP_GET_TUPLE(1, VAL)), PP_GET_TUPLE(2, VAL))
PP_GET_TUPLE(0, PP_WHILE(PRED, OP_1, (x, 2))) // -> x + 2 * 2 + 2 * 1 + 1 * 1
PP_WHILE_CHECK(I) 用于检查 I 对应的 PP_WHILE_I() 是否可用0 PP_EMPTY_V 作为谓词,调用 PP_WHILE_I()PP_WHILE_I() 正在展开,此处不会再被展开,和前缀 PP_WHILE_CHECK_ 拼接为 PP_WHILE_CHECK_PP_WHILE_I(0 PP_EMPTY_V, , 1) 的形式,最后展开为 0PP_WHILE_I() 没有使用,此处先被展开为 1,再和前缀 PP_WHILE_CHECK_拼接为 PP_WHILE_CHECK_1 的形式,最后展开为 1PP_AUTO_DIM() 用于推导 最小可用的递归状态 I4,那么先检查 2 是否可用;如果可用再尝试 1,否则检查 3PP_WHILE 通过 PP_AUTO_DIM(PP_WHILE_CHECK) 推导出的 PP_WHILE_I 保证总是可用不过,在展开PP_WHILE()时,当前递归状态总是确定的,实际上不需要推导。所以 BOOST_PP 建议尽量传递状态,而不是自动推导:
PP_WHILE_I() 展开时,把 下一个状态的下标 I + 1(连同当前 VAL)传给 PRED(PP_INC(I), VAL) 和 OP(PP_INC(I), VAL)PRED()/OP() 可以直接使用 I + 1 对应的宏(及 I + 1 以后的宏),无需再用 PP_AUTO_DIM() 推导可用的下标当然,自动推导 和 传递状态 也可以用于实现 PP_FOR_EACH() 的递归重入:
PP_FOR_EACH 定义为 PP_AUTO_DIM(PP_FOR_EACH_CHECK) 推导出的 PP_FOR_EACH_D 符号(自动推导)PP_FOR_EACH_D 再定义 不同变长参数个数 I 对应的 PP_FOR_EACH_D_I,然后用 上文提到的方法 遍历所有参数DO() 时,可以额外传递 下一个状态的下标 D + 1(传递状态)PP_FOR_EACH_D_I 重载CHAOS_PP 提出了一种基于延迟展开的递归调用方法:
#define PP_WHILE_RECURSIVE(PRED, OP, VAL) PP_IF(PRED(VAL), PP_WHILE_DEFER, VAL PP_EMPTY_V) (PRED, OP, PP_IF(PRED(VAL), OP, PP_EMPTY_V)(VAL))
#define PP_WHILE_INDIRECT() PP_WHILE_RECURSIVE
#define PP_WHILE_DEFER PP_WHILE_INDIRECT PP_EMPTY PP_EMPTY PP_EMPTY()()()()
// -> PP_WHILE_INDIRECT PP_EMPTY PP_EMPTY()()()
PP_WHILE_DEFER
// -> PP_WHILE_INDIRECT PP_EMPTY()()
PP_IDENTITY(PP_WHILE_DEFER)
// -> PP_WHILE_INDIRECT ()
PP_IF(1, PP_WHILE_DEFER, )
// -> PP_WHILE_RECURSIVE
PP_IDENTITY(PP_IF(1, PP_WHILE_DEFER, ))
PP_WHILE_I() 类似,PP_WHILE_RECURSIVE() 在 PRED(VAL) != 0 的情况下,展开为调用 PP_WHILE_DEFER 宏(即 PP_WHILE_INDIRECT PP_EMPTY PP_EMPTY PP_EMPTY()()()())的形式PP_EMPTY() 起到了 延迟展开 的作用PP_WHILE_DEFER 会被原地展开为 PP_WHILE_INDIRECT PP_EMPTY PP_EMPTY()()(),即其中一组 PP_EMPTY() 展开为空,然后 停止展开PP_WHILE_DEFER 作为参数传给 PP_IF() 时,一组 PP_EMPTY() 再展开为空;再作为 PP_IF() 的结果传出时,一组 PP_EMPTY() 又展开为空;最后得到 PP_WHILE_INDIRECT(),然后 停止展开PP_EMPTY()PP_WHILE_RECURSIVE() 展开时PP_WHILE_DEFER 内的 PP_EMPTY() 数量不足,就不会形成 PP_WHILE_INDIRECT(),而直接变为 PP_WHILE_RECURSIVEPP_WHILE_RECURSIVE 不能继续展开,即使使用下文提到的 PP_EXPAND() 也不行在每次循环结束后,得到的 PP_WHILE_INDIRECT(),需要先 手动展开 为 PP_WHILE_RECURSIVE,再进入下一轮迭代,直到 PRED(VAL) == 0 为止:
#define PP_EXPAND(...) __VA_ARGS__
// -> PP_WHILE_INDIRECT() (PRED, OP, (x + 2, 1))
PP_WHILE_RECURSIVE(PRED, OP, (x, 2))
// -> PP_WHILE_INDIRECT() (PRED, OP, (x + 2 + 1, 0))
PP_EXPAND(PP_WHILE_RECURSIVE(PRED, OP, (x, 2)))
// -> (x + 2 + 1, 0)
PP_EXPAND(PP_EXPAND(PP_WHILE_RECURSIVE(PRED, OP, (x, 2))))
PP_WHILE_RECURSIVE(),就需要嵌套几次 PP_EXPAND()PP_WHILE_RECURSIVE() 的延迟展开机制需要注意 上述方法 不一定适用于所有编译器,一般建议使用 PP_WHILE()。
借助 PP_WHILE() 和 PP_INC()/PP_DEC(),我们可以实现 非负整数加法:
#define PP_ADD(X, Y) PP_GET_TUPLE(0, PP_WHILE(PP_ADD_P, PP_ADD_O, (X, Y)))
#define PP_ADD_P(V) PP_GET_TUPLE(1, V)
#define PP_ADD_O(V) (PP_INC(PP_GET_TUPLE(0, V)), PP_DEC(PP_GET_TUPLE(1, V)))
PP_ADD(0, 2) // -> 2
PP_ADD(1, 1) // -> 2
PP_ADD(2, 0) // -> 2
PP_ADD() 从二元组 (X, Y) 开始迭代PP_ADD_O() 返回 (X + 1, Y - 1)PP_ADD_P() 是 Y == 0,此时的 X 为所求(可能上溢)借助 PP_WHILE() 和 PP_DEC(),我们还可以实现 非负整数减法:
#define PP_SUB(X, Y) PP_GET_TUPLE(0, PP_WHILE(PP_SUB_P, PP_SUB_O, (X, Y)))
#define PP_SUB_P(V) PP_GET_TUPLE(1, V)
#define PP_SUB_O(V) (PP_DEC(PP_GET_TUPLE(0, V)), PP_DEC(PP_GET_TUPLE(1, V)))
PP_SUB(2, 2) // -> 0
PP_SUB(2, 1) // -> 1
PP_SUB(2, 0) // -> 2
PP_SUB() 从二元组 (X, Y) 开始迭代PP_SUB_O() 返回 (X - 1, Y - 1)PP_SUB_P() 是 Y == 0,此时的 X 为所求(可能下溢)借助 PP_WHILE() 和 PP_ADD(),我们可以实现 非负整数乘法:
#define PP_MUL(X, Y) PP_GET_TUPLE(0, PP_WHILE(PP_MUL_P, PP_MUL_O, (0, X, Y)))
#define PP_MUL_P(V) PP_GET_TUPLE(2, V)
#define PP_MUL_O(V) (PP_ADD(PP_GET_TUPLE(0, V), PP_GET_TUPLE(1, V)), PP_GET_TUPLE(1, V), PP_DEC(PP_GET_TUPLE(2, V)))
PP_MUL(1, 2) // -> 2
PP_MUL(2, 1) // -> 2
PP_MUL(2, 0) // -> 0
PP_MUL(0, 2) // -> 0
PP_MUL() 从三元组 (R, X, Y) 开始迭代(R 初始值为 0)PP_MUL_O() 返回 (R + X, X, Y - 1)(此处的 PP_ADD() 内部调用 PP_WHILE() 宏,构成 递归重入)PP_MUL_P() 是 Y == 0,此时的 R 为所求(可能上溢)除法和取模运算 基于 数值比较,见下文。
借助 PP_WHILE() 和 PP_DEC(),我们还可以实现 等于比较:
#define PP_CMP(X, Y) PP_WHILE(PP_CMP_P, PP_CMP_O, (X, Y))
#define PP_CMP_P(V) PP_AND(PP_BOOL(PP_GET_TUPLE(0, V)), PP_BOOL(PP_GET_TUPLE(1, V)))
#define PP_CMP_O(V) (PP_DEC(PP_GET_TUPLE(0, V)), PP_DEC(PP_GET_TUPLE(1, V)))
#define PP_EQUAL(X, Y) PP_IDENTITY(PP_EQUAL_IMPL PP_CMP(X, Y))
#define PP_EQUAL_IMPL(RX, RY) PP_AND(PP_NOT(PP_BOOL(RX)), PP_NOT(PP_BOOL(RY)))
PP_EQUAL(1, 2) // -> 0
PP_EQUAL(1, 1) // -> 1
PP_EQUAL(1, 0) // -> 0
PP_CMP() 从二元组 (X, Y) 开始迭代PP_CMP_O() 返回 (X - 1, Y - 1)(同 PP_SUB_O())PP_CMP_P() 是 X == 0 || Y == 0,此时的 (X, Y) 为所求(不会下溢)(RX, RY) 只有三种情况:RX == 0 && RY == 0 / RX != 0 && RY == 0 / RX == 0 && RY != 0PP_EQUAL() 返回 RX == 0 && RY == 0 的布尔值PP_WHILE_RECURSIVE(),PP_EQUAL_IMPL PP_CMP(X, Y) 在 PP_CMP() 展开为 (RX, RY) 后,仍需要借助 PP_IDENTITY() 手动展开 PP_EQUAL_IMPL(RX, RY)类似的,我们还可以实现 小于比较:
#define PP_LESS(X, Y) PP_IDENTITY(PP_LESS_IMPL PP_CMP(X, Y))
#define PP_LESS_IMPL(RX, RY) PP_AND(PP_NOT(PP_BOOL(RX)), PP_BOOL(RY))
PP_LESS(0, 1) // -> 1
PP_LESS(1, 2) // -> 1
PP_LESS(1, 1) // -> 0
PP_LESS(2, 1) // -> 0
PP_CMP() 的结果,PP_LESS() 返回 RX == 0 && RY != 0 的布尔值其他比较方式(不等于、大于、小于等于、大于等于)可以通过 PP_EQUAL()/PP_LESS() 的 布尔运算 得到。
借助 PP_IF() 和 PP_LESS(),我们可以获取 最大值 / 最小值:
#define PP_MIN(X, Y) PP_IF(PP_LESS(X, Y), X, Y)
#define PP_MAX(X, Y) PP_IF(PP_LESS(X, Y), Y, X)
PP_MIN(0, 1) // -> 0
PP_MIN(1, 1) // -> 1
PP_MAX(1, 2) // -> 2
PP_MAX(2, 1) // -> 2
借助 PP_WHILE() 和 PP_SUB()/PP_LESS(),我们可以实现 非负整数除法 / 取模:
#define PP_DIV_BASE(X, Y) PP_WHILE(PP_DIV_BASE_P, PP_DIV_BASE_O, (0, X, Y))
#define PP_DIV_BASE_P(V) PP_NOT(PP_LESS(PP_GET_TUPLE(1, V), PP_GET_TUPLE(2, V))) // X >= Y
#define PP_DIV_BASE_O(V) (PP_INC(PP_GET_TUPLE(0, V)), PP_SUB(PP_GET_TUPLE(1, V), PP_GET_TUPLE(2, V)), PP_GET_TUPLE(2, V))
#define PP_DIV(X, Y) PP_GET_TUPLE(0, PP_DIV_BASE(X, Y))
#define PP_MOD(X, Y) PP_GET_TUPLE(1, PP_DIV_BASE(X, Y))
PP_DIV(2, 1), PP_MOD(2, 1) // -> 2, 0
PP_DIV(1, 1), PP_MOD(1, 1) // -> 1, 0
PP_DIV(0, 1), PP_MOD(0, 1) // -> 0, 0
PP_DIV(1, 2), PP_MOD(1, 2) // -> 0, 1
PP_DIV_BASE() 从三元组 (R, X, Y) 开始迭代(R 初始值为 0)PP_DIV_BASE_O() 返回 (R + 1, X - Y, Y)(此处的 PP_SUB() 内部调用 PP_WHILE() 宏,构成 递归重入)PP_DIV_BASE_P() 是 X >= Y,此时的 R 为商、X 为余数(R 可能上溢,X 不会下溢)有时候,可以使用 C++ 模板 处理 类型,不必完全依赖于宏。例如把函数的 class 类型参数转为 const T&,而其他类型参数保持 T:
template <typename T, bool Condition = std::is_class_v<T>>
using maybe_cref_t =
std::conditional_t<Condition,
std::add_lvalue_reference_t<std::add_const_t<T>>,
T>;
#define MAKE_ARG(TYPE, IDX, _) PP_COMMA_IF(IDX) maybe_cref_t<TYPE> PP_CONCAT(v, IDX)
// -> void foo(maybe_cref_t<int> v0, maybe_cref_t<std::string> v1);
// -> void foo(int v0, const std::string& v1);
void foo(PP_FOR_EACH(MAKE_ARG, , int, std::string));
maybe_cref_t<int> 和 maybe_cref_t<std::string>int 和 const std::string&本文的用法 主要参考 以下资料:
MOCK_METHOD()自动推导 参数个数本文主要介绍了宏编程的常用方法,但可能存在不足:
PP_IS_SYMBOL() 不能检查 以非标识符开头的参数)实际应用场景中,建议使用成熟的预处理库。
如果有什么问题,欢迎交流。
Delivered under MIT License © 2020, BOT Man
请问一下,如果想同时声明一个枚举和对应同名的字符串。。用宏编程有没有比较优雅的方式。。
追加到最后了 https://godbolt.org/z/3a8Txc
高质量文章。
我觉得还是 lisp 那种 ast 层面的宏做 metaprogramming 比较舒坦,c 这个宏用得太憋屈了。。
根本原因是:C 的宏常常被 “滥用于” 元编程[捂脸][捂脸][捂脸]
Julia 吸收了 Lisp 这一优点。https://docs.julialang.org/en/v1/manual/metaprogramming/
东方宏模乡(确信
哪里都有越共 [捂脸]
宏元编程难得的好文章,总结的很全面。boost 的 pp 库的使用体验很糟糕,接口的设计很不正交。好几年前,我也写了一个 pp 库,感觉用起来比 boost 的那个破 pp 库要方便。用宏搞图灵完备,一言难尽,实在是模板元编程搞不定,才会动用宏,又往往能起死回生,真是不可思议。有空我也写篇文章,说点不一样的宏故事
期待一下~~~
奇怪的姿势增加了
请问一下,如果想同时声明一个枚举和对应同名的字符串。。用宏编程有没有比较优雅的方式。。
#define ENUM(NAME, ...) enum class NAME { __VA_ARGS__ }; \
std::map<NAME, const char*> PP_CONCAT(NAME, Map) = { PP_FOR_EACH(ENUM_IMPL_EACH, NAME, __VA_ARGS__) }
#define ENUM_IMPL_EACH(VAR, IDX, CTX) PP_COMMA_IF(IDX) { CTX::VAR, PP_STRINGFY(VAR) }
追加到最后了 https://godbolt.org/z/3a8Txc
想问一下用宏的好处是啥(除了代码看起来清爽),感觉用了宏不利于单步调试,没办法看清具体的值
没有好处,实在没办法再用(我的场景是生成一些不需要调试的代码,所以用了宏)
感谢。宏如何实现返回多级指针?比如,VOID(N) 表示一个 n 级的 void 指针
可以详细描述一下需求吗?[好奇]
c 写多维数组内存分配,二维数组返回二级指针 double **, 三维数组返回 double ***,如果我要申请 1-6 维素组,就得写 6 个函数,如何写一个函数接受维数参数,然后可以泛化申请任意维度的数组的内存?可以实现吗
我来一个釜底抽薪,为什么不写一个生成 c++ 代码的程序,而要用这么麻烦的宏编程。另外我觉得 c++ 的模板也是搞的很麻烦。
你说的轮子已经有很多了 [捂脸]
全文完
写在前面如何调试特殊符号符号拼接自增自减逻辑运算布尔转换条件选择惰性求值变长参数下标访问长度判空长度计算遍历访问符号匹配数据结构递归重入条件循环延迟展开数值运算数值比较结合模板参考资料写在最后
原文:https://www.cnblogs.com/cx2016/p/13451958.html