前言:笔者之前是cv方向,因为工作原因需要学习NLP相关的模型,因此特意梳理一下关于NLP的几个经典模型,由于有基础,这一系列不会关注基础内容或者公式推导,而是更侧重对整体原理的理解。顺便推荐两个很不错的github项目——开箱即用的中文教程以及算法更全但是有些跑不通的英文教程。
得到更好更准确的词向量。和图像的表示方法不同,NLP中一般用向量来表示不同的单词,向量一般采用one-hot的方法来初始化,但是这样会带来两个问题:
因此诞生了word2vec模型,本质上和先做人脸分类、再根据人脸特征距离判断是不是一个人的思路很像,word2vec也是训练分类问题,从而得到更优的词向量表示。
word2vec包括两种结构:CBOW模型(根据周围的词预测中心词,多对一模型)与Skip-gram模型(根据中心词预测周围词,一对多模型),两者结构如下——
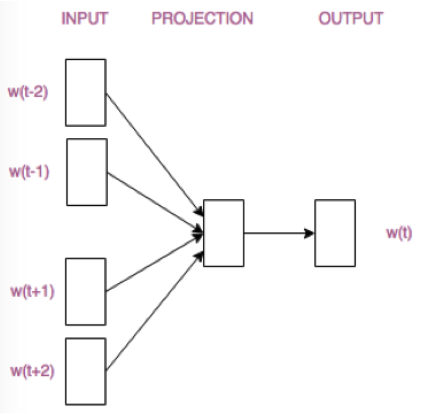
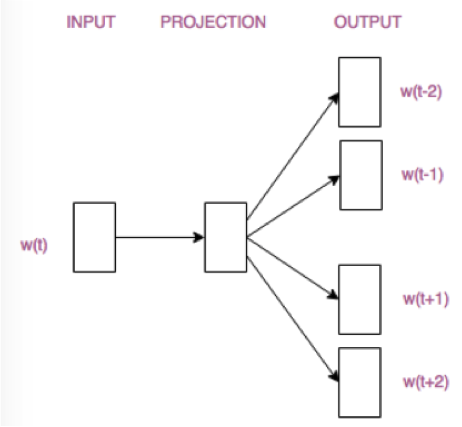
需要注意的是,word2vec只有一个隐层,输出层使用softmax等loss进行监督。隐层没有激活层,因此word2vec中词向量是其它词向量的线性组合。
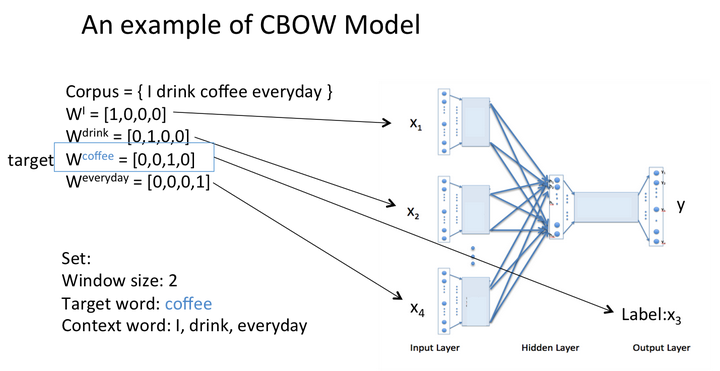
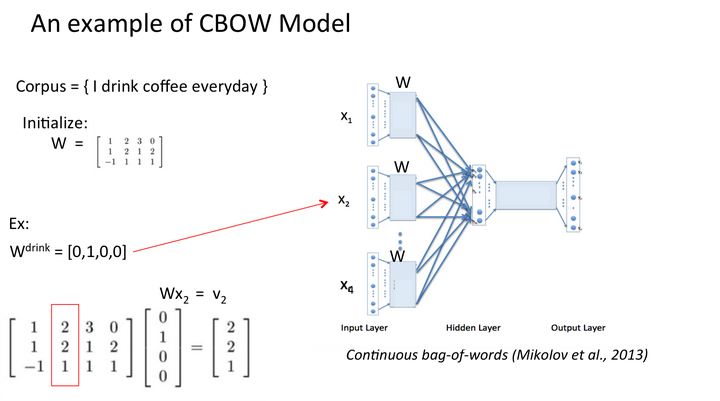
学习{I drink coffee everyday}一句话,其中coffee是中心词,window size设定为2
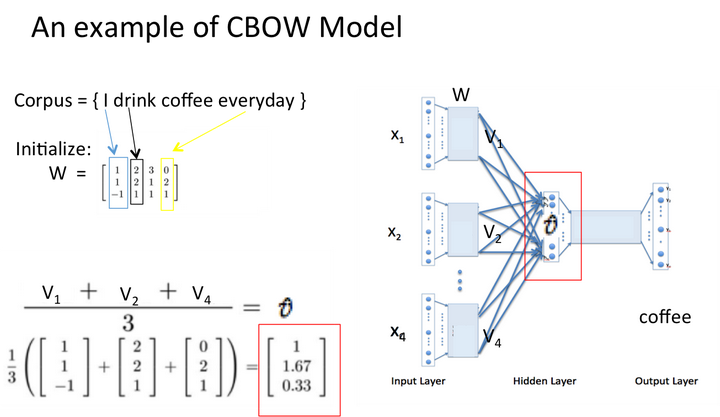
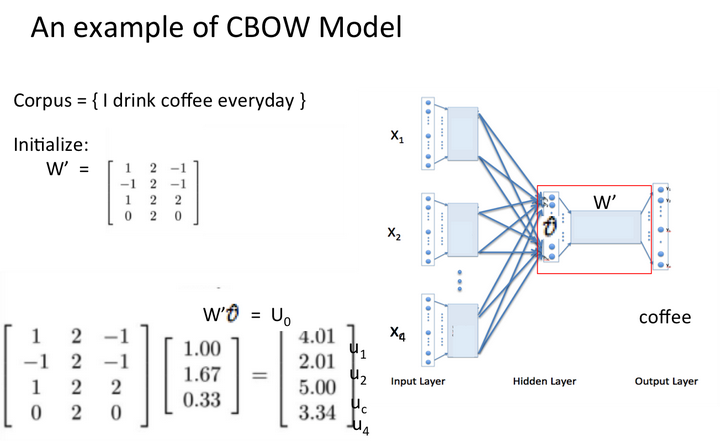
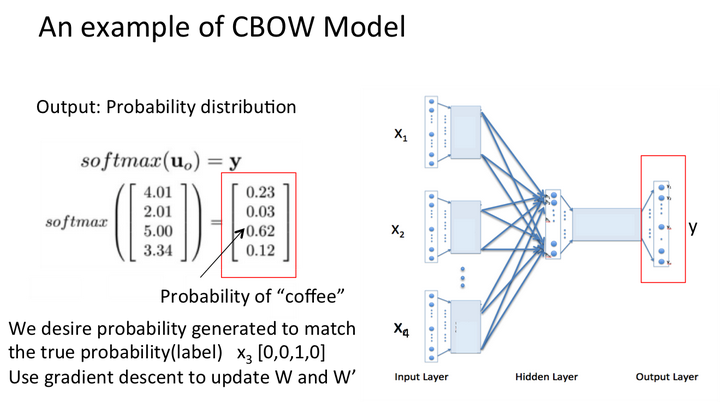
原文:https://www.cnblogs.com/lity/p/13454850.html