nn.Conv2d的groups参数:
groups参数控制分组卷积,参数默认为1,即普通二维卷积。
当groups=1时:
conv = nn.Conv2d(in_channels=6, out_channels=6, kernel_size=1, groups=1)
conv.weight.data.size()
#torch.Size([6, 6, 1, 1])
当groups=2时:
conv = nn.Conv2d(in_channels=6, out_channels=6, kernel_size=1, groups=2)
conv.weight.data.size()
#torch.Size([6, 3, 1, 1])
当groups=in_channels时:
conv = nn.Conv2d(in_channels=6, out_channels=6, kernel_size=1, groups=6)
conv.weight.data.size()
#torch.Size([6, 1, 1, 1])
out_channels必须能被groups整除。
由于参数初始化不同,训练结果差异很大。固定参数方法如下
#cudnn确保精度。实际上影响不大,会导致计算效率降低
from torch.backends import cudnn
cudnn.benchmark = False # if benchmark=True, deterministic will be False
cudnn.deterministic = True
#pytorch设置随机种子
torch.manual_seed(seed) # 为CPU设置随机种子
torch.cuda.manual_seed(seed) # 为当前GPU设置随机种子
torch.cuda.manual_seed_all(seed) # 为所有GPU设置随机种子
#数据读取中的随即预处理。可对python,numpy设置随机种子
import random
import numpy as np
random.seed(seed)
np.random.seed(seed)
#dataloader中的读取顺序运行结果也会有差异
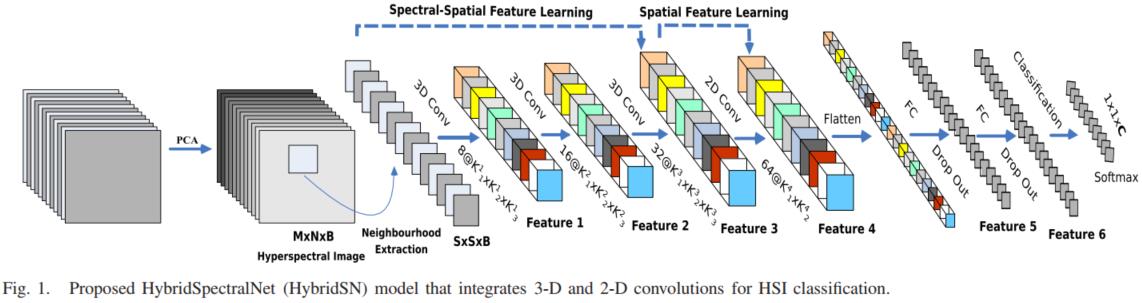 论文中最后一层是sotfmax+fc,然而在代码最后一层中加入sotfmax反而损失不下降。查阅官方文档发现是由于损失函数采用cross_entropy,而cross_entropy中这么描述his criterion combines
论文中最后一层是sotfmax+fc,然而在代码最后一层中加入sotfmax反而损失不下降。查阅官方文档发现是由于损失函数采用cross_entropy,而cross_entropy中这么描述his criterion combines log_softmax and nll_loss in a single function.,实现代码如下: def cross_entropy(input, target, weight=None, size_average=None, ignore_index=-100, reduce=None, reduction=‘mean‘):
if not torch.jit.is_scripting():
tens_ops = (input, target)
if any([type(t) is not Tensor for t in tens_ops]) and has_torch_function(tens_ops):
return handle_torch_function(
cross_entropy, tens_ops, input, target, weight=weight,
size_average=size_average, ignore_index=ignore_index, reduce=reduce,
reduction=reduction)
if size_average is not None or reduce is not None:
reduction = _Reduction.legacy_get_string(size_average, reduce)
return nll_loss(log_softmax(input, 1), target, weight, None, ignore_index, None, reduction)
总结:如果损失函数采用nn.CrossEntropyLoss(),那么最后一层不需要加softmax。
原文:https://www.cnblogs.com/Arsene-W/p/13457577.html