----------------------------------------------------------------------------------------------------------------
1.数据仓库(Data Warehouse)定义
Bill Inmon对数仓的定义是:一个面向主题的、集成的、随时间变化的、非易失的数据集合,用于支持管理者的决策过程。
个人理解:面向主题即 企业的运营或需求主题并按主题划分对数据进行分类
集成即 多数据源集成
随时间变化即 源数据可能存在变化的可能性,如目标居住地迁移
非易失即 数仓数据需要可靠的全量存储
2.数仓好处
1.数据模型设计
数据模型是对现实世界数据特征的抽象,数据模型的设计方法就是对数据进行归纳和概括的方法。
2.方法选择
业界主要的模型设计方法论有两种:
a.数据仓库之父 Bill Inmon 提出的范式建模,又叫 ER 建模,主张站在企业角度自上而下进行数据模型构建
b.大师Ralph Kimball 倡导的维度建模方法,主张从业务需求出发自下而上构建数据模型
3.维度建模模式
a.星形模式(Star Schema)
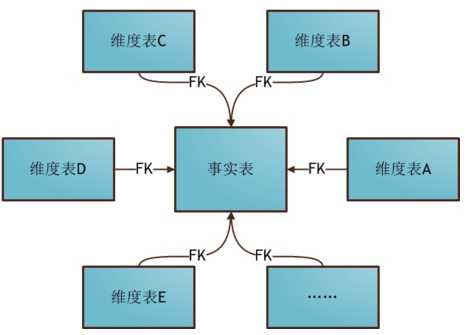
星形模式的维度建模由一个事实表和一组维表成,
具有以下特点:
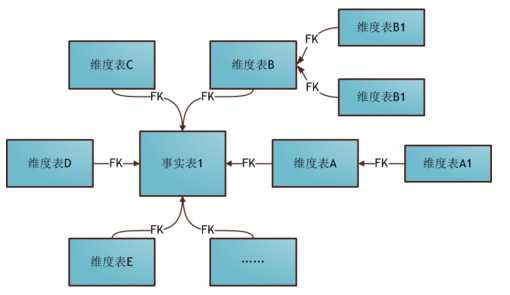
雪花模式是对星形模式的扩展,每个维表可继续向外连接多个子维表.
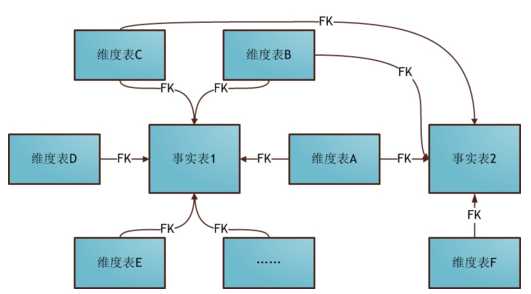
星座模式也是星型模式的扩展
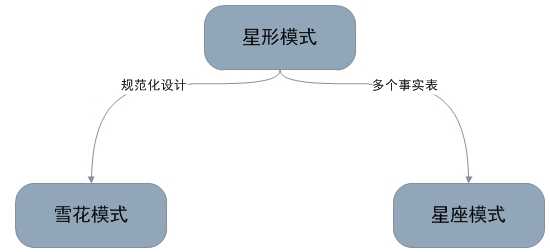
雪花模式是将星型模式的维表进一步划分,使各维表均满足规范化设计。而星座模式则是允许星形模式中出现多个事实表。
1.数仓分层概述
数据仓库标准架构分为三层(或三层以上),分别是ODS(操作性数据)、DW(数据仓库)、DM(数据集市).
2.数仓架构设计
实践过程中数仓搭建通常为:ods-dwd-dws-ads
ODS:Operation Data Store
原始数据
DWD(数据清洗/DWI) data warehouse detail
数据明细详情,去除空值,脏数据,超过极限范围的
明细解析
具体表
DWS(宽表-用户行为,轻度聚合) data warehouse service
服务层--留存-转化-GMV-复购率-日活
轻度聚合对DWD
ADS(APP/DAL/DF)-出报表结果 Application Data Store
做分析处理同步到RDS数据库里边
1.常见数仓工具
azkaban,oozie,kettle等
2.udf
udf(user define function)是hive等框架提供的自定义函数扩展功能,通过udf可以极大地扩展hive的处理能力。
3.hive中udf分类
udf:普通函数,只对单行数据产生作用 1->1
udaf:a-aggregation 用户定义聚合函数,可对多行数据产生作用 n->1
udtf:t-table_generation 可以解决输入一行输出多行 1->n
原文:https://www.cnblogs.com/coder-ydq/p/13463319.html