数据库管理系统DBMS是现代应用中不可或缺的一部分,其中一个重要原因是其隐藏了外存管理的细节,并为应用层提供了高效、易用的数据检索Retrieval与持久化Persistence功能。
外存具有容量大、成本低、断电非易失等优点,但同时也存在寻址慢、访问粒度粗的问题:
数据库的读写性能取决于外存访问效率,而优化外存访问的手段有:
Buffer、读缓存Cache的方式,将热点数据临时存储在内存,避免频繁的外存访问WAL对写操作进行优化,将随机写操作简化为顺序的追加操作Index来组织数据,通过有序性提高检索效率预写日志系统 WALWrite-Ahead Logging是一种用于提高数据库写性能的常见手段,被广泛应用于持久化数据库中。
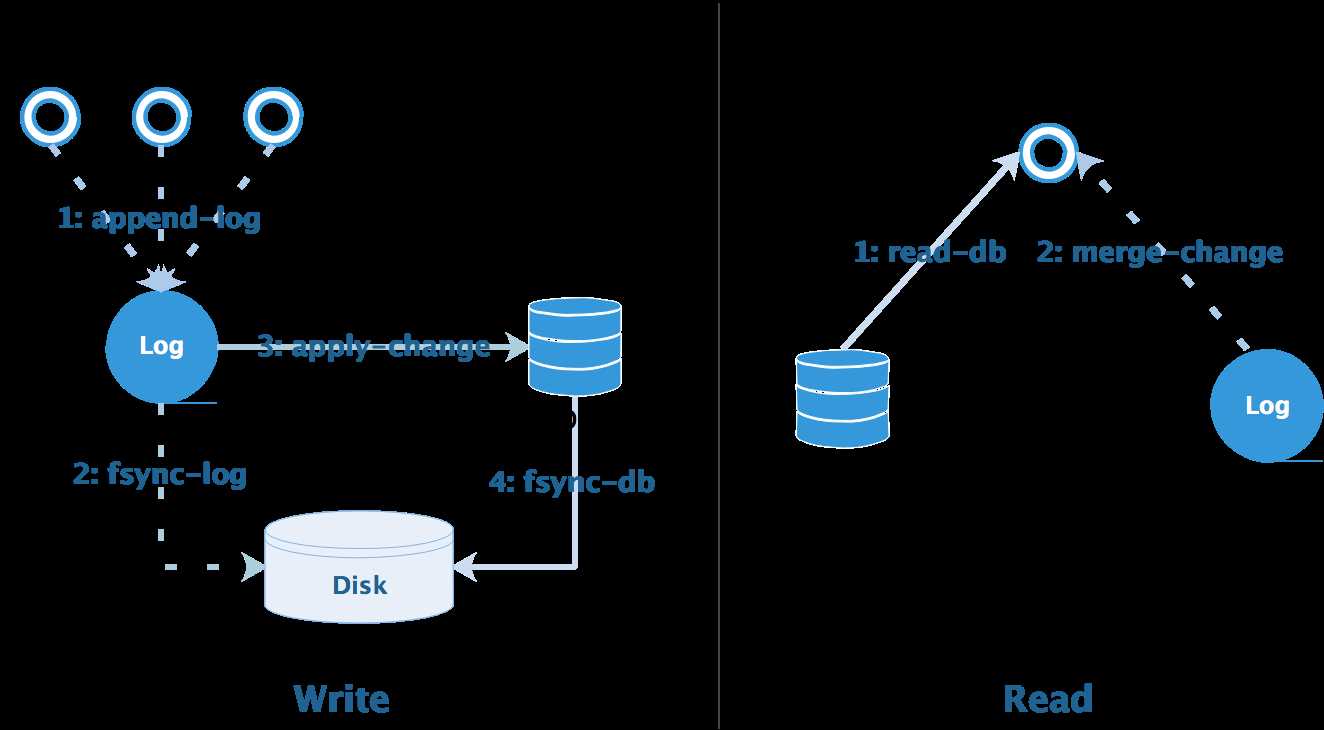
数据库中的状态可以分为两部分:
WAL 的核心思想是 日志先行 :
由于追加 WAL 是顺序的,可以将随机的磁盘IO转换为顺序的磁盘IO,减少磁盘巡道时间,从而能够更有效地提升了磁盘的吞吐量。
数据库重启过程中会检查 WAL 日志,任何尚未附加到 DB 数据页的记录都将从日志记录中重放,每次提交事务时不再需要(为了保证数据安全)把数据页冲刷到磁盘,有效地提升了事务吞吐量。
WAL 只允许在尾部追加数据 Append-Only ,不允许修改日志记录。这种不变性 Immutability 有利于并发控制:删改数据只能通过追加新的日志实现,因此修改前无需对数据加锁,直接在日志末尾追加新的记录即可。
然而 WAL 的体积也不可能无限增长,系统需要周期性周期性的清理无用的日志记录,减少文件碎片,释放磁盘空间。
索引是一种附加的数据结构,以牺牲空间和写入速度为代价,换取更快的检索速度。最常用的索引结构莫过于 Hash 与 Tree:
O(1)O(log2n)由于数据库需要管理海量的数据,因此 Tree 便成为外存索引的不二之选。
下面介绍其中最具代表性两类索引结构:B-Tree 与 LSM-Tree
最基础的 Tree 莫过于二叉查找树。其查找数据的方式,就是从根节点开始逐层向下遍历,直到找到目标节点。但是当数据量比较大的时候,会有以下问题:
B-Tree 是一种用于处理海量数据的平衡多路查找树,其主要改进是对二叉树中间节点进行了合并,通过平衡算法和分叉因子 b,可以将树高度控制在logbn 的级别,对外存访问更为友好:
这意味着:只需要很少的磁盘 IO,就能够对大量的数据进行高效的查找操作。
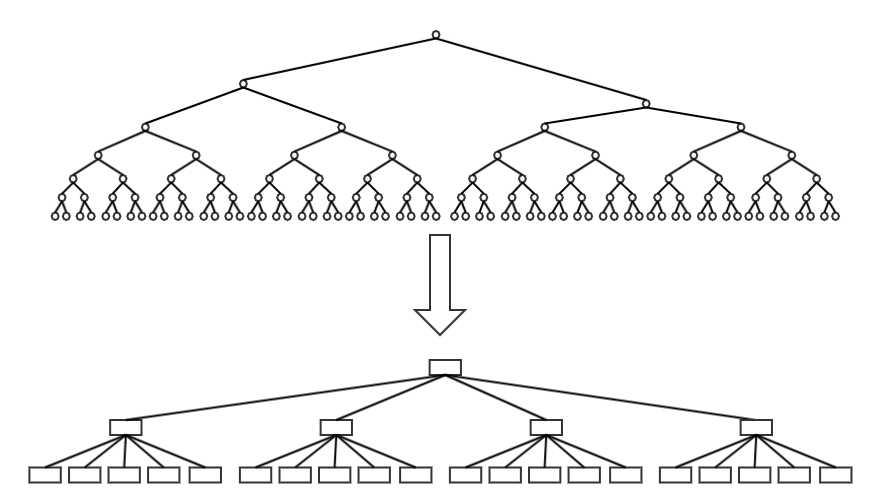
B-Tree 在作为外存索引使用时:
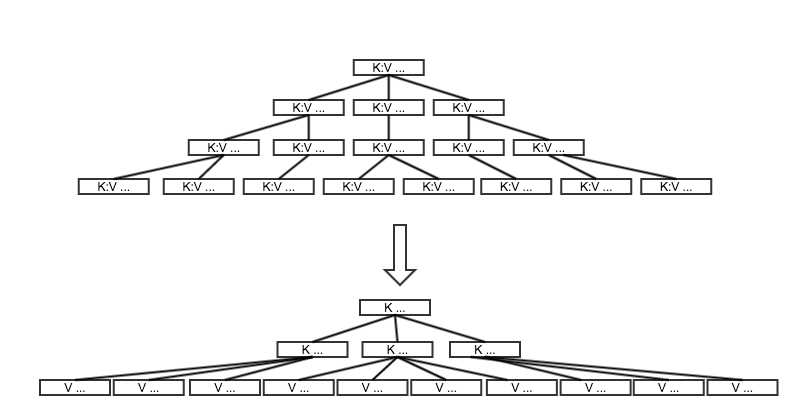
block,操作系统使用逻辑页page管理应用程序的地址映射)B+Tree 是对 B-Tree 的进一步改进:将 Key 与 Value 进行分离,非叶节点只保存 Key,所有 Value 下沉到叶子节点。
每个中间节点可以容纳更多的 Key,进一步提高了中间节点的密度,在相同的数据量下,树的高度要比 B-Tree 更低。
在任何系统中,日志都是不可或缺的重要组成部分,之前所说
LSM-Tree 的全称是 Log-Structured Merge Tree,相较于一种索引结构,其本质更接近于一整套完整的索引维护机制:
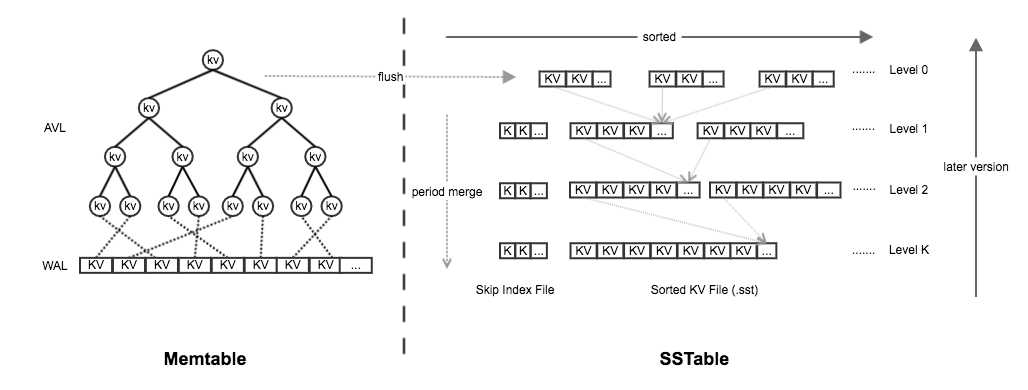
LSM-Tree 大致可以分为两部分:
Memtable: 常驻内存的 KV 查找树 + 无序的 WAL 文件SSTable (Sorted String Table): 一组存储在磁盘的不可变文件(稀疏索引部分可选),存储有序的键值对先将数据写入 WAL 文件,然后修改内存中的 AVL,因此最优情况下,每次写操作只有一次磁盘 I/O。
删除操作并不会直接删除磁盘中的内容,而是将删除标记(tombstone)写入 Memtable。当 Memtable 增大到一定程度后,则会转换为 Immutable Memtable 并产生一个新的 Memtable 接受写操作。
后台会启动一个合并线程,当 Immutable Memtable 达到一定数量,合并线程会将其写入磁盘(Flush),生成 Level 0 的 SSTable 文件。
当 Level N 的 SSTable 文件数量到达阈值之后,会进行合并压缩(Compaction)操作,在 Level N+1 生成新的 SSTable 文件。
SSTable 分为多层,单个文件的大小通常是上一层的 10 倍,每层可以同时包含多个 sst 文件,每个文件由多个 block 组成,其大小约为 32K,是磁盘 IO 的基本单位。
第 Level i (i > 0) 层的 SSTable 满足:
首先中 Memtable 中进行查找,如果找不到,则按 Level 0、Level 1、... 的方式逐层向下遍历.
一个 Key 可能同时存在于多层 SSTable 中,这种情况下以层数最小的记录为准
为了提高热点数据的读取效率,提供了 sstable block cache 的功能,用于缓存读取数据。
某些不存在的 Key 可能会导致较深的无用查找,通过使用 BloomFIlter 对 Key 进行过滤可以规避这一问题。
对于读写负载较高的数据库,性能瓶颈很有可能是磁盘的读写频率。在这种情况下,读写放大会显著影响性能:
在磁盘带宽一定的情况下,放大效应越明显,每次对数据库的读写操作造成磁盘IO越多,每秒钟能处理的数据库操作次数越小
| Write | B-Tree | LSM-Tree |
|---|---|---|
| 最优 |
|
|
| 最坏 |
|
|
LST-Tree 平均只需要写一次磁盘,即写 WAL, 在少数情况下,一次写入也有可能造成多次写磁盘操作。
| Read | B-Tree | LSM-Tree |
|---|---|---|
| 最优 |
|
|
| 最坏 |
|
|
LST-Tree 由于引入了 SSTable 格式,最坏情况下读取次数不可控。
LSM-Tree 有着更小的写放大效应,B-Tree 有着更小的读放大效应。
LSM-Tree 能够承载更高的写入吞吐量,B-Tree 在随机读的情况下能够提供更稳定的性能保障。
LSM-Tree 本身就是一种对读写的 trade-off,用更大的读放大效应换取更小的写放大效应。
更进一步的,LSM-Tree 可以通过调整合并策略Merge Policy在读写放大之间进行权衡。
| 优点 | 缺点 | |
|---|---|---|
| B-Tree |
|
|
| LSM-Tree |
|
|
原文:https://www.cnblogs.com/buttercup/p/12991585.html