------------恢复内容开始------------
point的格式标注的,如果你的算法数据加载入口是标注的VOC格式(一般都是),那你就不得不在保存的时候保存成VOC格式。在处理之前先对数据进行了封装,这样在处理的过程中比较方便,也可以使用字典进行简单的封装
class Data:
"""
封装图像和其对应的标注信息
"""
def __init__(self, name, boxes=None, img=None):
if boxes is None:
boxes = []
self.name = name
self.boxes = boxes
self.img = img
self.shape = img.shape
def append_box(self, box):
"""
向这个数据中添加标注框信息
:param box:
:return:
"""
self.boxes.append(box)
def set_name(self, name):
self.name = name
def set_img(self, img):
self.img = img
class Box:
"""
box类包含两个字段,一个是这个box的类别,一个是这个box的坐标信息[xmin,ymin,xmax,ymax]
"""
def __init__(self, label, cod):
self.label = label
self.cod = cod
def get_label(self):
return self.label
def get_cod(self):
return self.cod
def load_data(img_path, xml_path, flog_path, save_path):
"""
加载所有的图像和其标注,以标注文件为准,有的图像并没有标注,然后对其进行数据增强并保存
:param flog_path: 云雾图像所在目录
:param save_path: 数据集保存的根目录
:param img_path: 图像文件路径, tif格式
:param xml_path: 标注文件路径,VOC格式
:return:
"""
annotations = os.listdir(xml_path)
data_list = []
for annotation in annotations:
xml_file = open(os.path.join(xml_path, annotation), ‘br‘)
# 如果是解析标准的VOC标注此处更换函数voc2data
boxes = load_annotations(xml_file)
name = annotation.split(".")[0]
img = cv2.imread(os.path.join(img_path, name + ".tif"))
data = Data(name=name, boxes=boxes, img=img)
data_list.append(data)
def load_annotations(xml_file):
"""
解析标注文件中的信息,这个标注文件格式与标准的VOC不同,是我个人拿到的数据形式
:param xml_file:标注文件
:return: 标注文件中的坐标信息和所属类别,对应的图像名称等等信息
"""
boxes = []
# 解析文件
tree = ET.parse(xml_file)
# 获取根节点
root = tree.getroot()
# 获取目标节点
objects = root.find("objects")
for obj in objects.iter("object"):
# 找到这个标注框对应的标签
label = obj.find("possibleresult").find("name").text
x = []
y = []
# 找到这个框的坐标
for temp in obj.find("points").iter("point"):
xy = temp.text.split(",")
x.append(int(float(xy[0])))
y.append(int(float(xy[1])))
cod = [min(x), min(y), max(x), max(y)]
box = Box(label=label, cod=cod)
boxes.append(box)
return boxes
def voc2data(xml_file):
"""
解析标准VOC格式的标注文件获取其对应的box和所属的类别
:param xml_file:
:return:
"""
boxes = []
tree = ET.parse(xml_file)
root = tree.getroot()
for obj in root.iter("object"):
label = obj.find("name").text
bndbox = obj.find("bndbox")
xmin = int(bndbox.find("xmin").text)
ymin = int(bndbox.find("ymin").text)
xmax = int(bndbox.find("xmax").text)
ymax = int(bndbox.find("ymax").text)
boxes.append(Box(label=label, cod=[xmin, ymin, xmax, ymax]))
return boxes
以上我们就完成了数据的封装部分,后续就需要对这些封装起来的信息进行操作。后面的所有函数中的参数都是以data或者data的列表形式进行传递的

对于矩形图像,如果旋转的度数不是90的倍数,就意味着需要将旋转过后的图像进行裁剪或者缩小后进行背景补充才行。旋转的过程中标注文件也必须做相应的改动才能对应上。
def rot90(data):
"""
将data中的图像做一个旋转90度的处理,将其对应的标注信息也做对应的处理
:param data:
:return:
"""
img = data.img
img_new = np.rot90(img)
boxes_new = []
boxes = data.boxes
for box in boxes:
# 旋转90度,现在的x_min就是原来的y_min
cod = box.cod
x_min = cod[1]
# 现在的y_min就是图像的宽减去原来的x_max
y_min = data.shape[1] - cod[2]
# 现在的x_max就是原来的y_max
x_max = cod[3]
# 现在的y_max就是图像的宽减去原来的x_min
y_max = data.shape[1] - cod[0]
box_new = Box(box.label, [x_min, y_min, x_max, y_max])
boxes_new.append(box_new)
data_new = Data(data.name + "_rot90", boxes_new, img_new)
return data_new
如果你想要实现逆时针选装180度,可以嵌套使用上面的rot90()函数

翻转是另外一种非常常用的数据增强方式,和上面的旋转一样,在实际应用场合中只是为了扩充后续更加复杂的数据增强方式的图像基数。
以下的代码实现了水平翻转,和旋转一样,标注文件需要做出相应的改变。
def flip_vertical(data):
"""
将data中的图像水平旋转
:param data:
:return:
"""
img = data.img.copy()
img_new = cv2.flip(img, 0)
boxes = data.boxes
boxes_new = []
for box in boxes:
cod = box.cod
y_min = data.shape[0] - cod[3]
y_max = data.shape[0] - cod[1]
x_min = cod[0]
x_max = cod[2]
cod_new = [x_min, y_min, x_max, y_max]
box_new = Box(box.label, cod_new)
boxes_new.append(box_new)
data_new = Data(data.name + "_flip", boxes_new, img_new)
return data_new

复制小目标这种数据增强方式主要针对小目标检测,通过将数据中面积较小的目标进行复制粘贴来达到使小目标数量增多的目的。理论依据出自论文《Augmentation for small object detection》
复制小目标首先要确认小目标,给什么样 的目标是小目标定一个标准
def paste(data):
"""
拷贝图像中的小目标,根据长宽的统计,划定面积小于300*300的为小目标
:param data:
:return:
"""
change = False
img_new = data.img.copy()
boxes = data.boxes.copy()
for index, box in enumerate(data.boxes):
cod = box.cod
length = cod[3] - cod[1]
width = cod[2] - cod[0]
area = length * width
if area < 20000:
# 如果有需要复制的目标,保存新的标注文件和图片
change = True
# 判定为小目标,把目标部分截取出来
cropped_img = data.img[cod[1]:cod[3], cod[0]:cod[2]]
# 获取随机位置
copy_cods = getRandomCod(data.shape, boxes, 5, width, length)
for cod in copy_cods:
img_new[cod[1]:cod[3], cod[0]:cod[2]] = cropped_img
boxes.append(Box(box.label, cod))
if change:
data_new = Data(name=data.name + "_small", img=img_new, boxes=boxes)
return data_new
else:
return None
上面的代码逻辑很简单,首先是对图中所有的目标进行一个分析,对面积小于20000的目标进行复制,这里用2000是因为我们的数据集图像尺寸是一致的,并且事先对标注框尺寸分布做了统计,如下图。
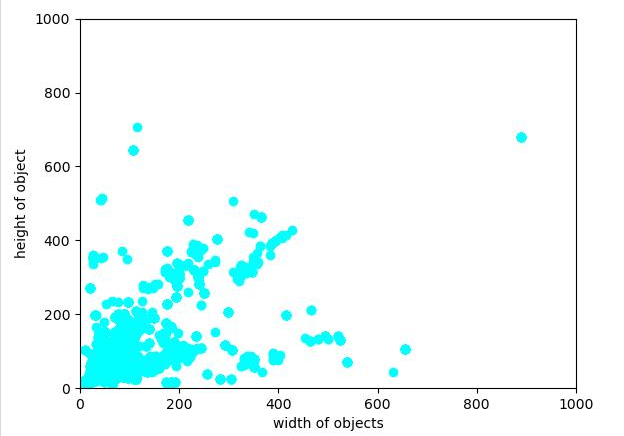
由论文中的思想,对于小目标的复制过程中,需要保证不与已经存在的标注框重合,所以需要iou检测。
def check_overlap(cod_1, cod_2):
"""
判断两个标注框是否重叠
:param cod_1:
:param cod_2:
:return: true or false
"""
# 计算交集
x_min = max(cod_1[0], cod_2[0])
y_min = max(cod_1[1], cod_2[1])
x_max = min(cod_1[2], cod_2[2])
y_max = min(cod_1[3], cod_2[3])
x = max(0, x_max - x_min)
y = max(0, y_max - y_min)
if x * y > 0:
return True
else:
return False
然后对每个小目标都随机取个位置进行粘贴,获取他们的位置。
def getRandomCod(shape, boxes, num, width, height):
"""
根据传入的图像尺寸和原始标注框的坐标信息来获取num个随机的标注框左上角坐标
:param height:
:param width:
:param num: 生成的随机标注框个数
:param shape: 图像本身的尺寸
:param boxes: 原始标注框的坐标信息
:return: 返回n个cod回去
"""
ret = []
for i in range(num):
while True:
x = random.randint(0, shape[1])
y = random.randint(0, shape[0])
cod_tmp = [x, y, x + width, y + height]
# 先检验是否越界
if check_overSize(cod_tmp, shape):
# 如果越界了,就重新生成坐标
continue
overlap = False
for box in boxes:
if check_overlap(box.cod, cod_tmp):
# 如果相交的话,那么就直接break
overlap = True
break
else:
continue
if not overlap and len(ret) != 0:
for cod in ret:
if check_overlap(cod, cod_tmp):
overlap = True
break
if not overlap:
ret.append(cod_tmp)
break
else:
continue
return ret

对数据进行增强有一个常见的方式就是添加各种各样的噪声,从而让这些数据去训练网络的时候,能够使网络变得适应性更强,鲁棒性更强,对真实情况的泛化能力也越强。通常使用的有椒盐噪声,高斯噪声等等。但是这次由于数据集的独特性,所以使用了高斯模糊进行数据增强,这个实现起来很简单,使用opencv中的高斯滤波函数即可实现图像的效果,对应的标注文件位置不变。
def gaussian_blur(data):
"""
高斯模糊
:param data:
:return:
"""
img_new = data.img.copy()
img_new = cv2.GaussianBlur(img_new, (11, 11), 0)
data_new = Data(name=data.name + "_gaussian", boxes=data.boxes.copy(), img=img_new)
return data_new

我们的数据是遥感图像,所以在拍摄中会有很多的云雾,为了模拟在这种情况下的网络输入,使用认为添加云雾的方式来做数据增强。
我们事先采集了一些云雾的图像,这些图像对比度较强,除了云雾部分其余部分都是接近黑色的深色,这样天空背景对图像的影响比较小。
def add_flog(data, flog_list):
"""
:param data:
:param flog_list:保存云雾图像的绝对路径列表
:return:
"""
img_src = data.img.copy()
img_flog = cv2.imread(random.choice(flog_list))
if random.randint(0, 10) > 5:
img_flog = np.rot90(img_flog)
img_flog = cv2.resize(img_flog, img_src.shape[:2][::-1])
img_new = cv2.addWeighted(img_src, 0.6, img_flog, 0.4, 0)
data_new = Data(name=data.name + "_flog", boxes=data.boxes.copy(), img=img_new)
return data_new

为了进一步增加网络对小目标的泛化能力,我们对数据集中仅有大目标的图像进行了整体缩小,然后将边缘使用黑色填充,这样也是增加了小目标出现的频率。
def shrink(data):
"""
放大仅有小目标的图像
:param data:
:return:
"""
# num用于检测整张图像中是否仅有大目标,仍然是以20000为界
num = 0
for box in data.boxes:
cod = box.cod
area = (cod[3] - cod[1]) * (cod[2] - cod[0])
if area < 20000:
num += 1
if num == 0:
plate = np.zeros_like(data.img)
data_new = resize(data, shape=(plate.shape[1] // 2, plate.shape[0] // 2))
# 确保缩小图像在中间位置
shape = data_new.shape
plate[shape[0] // 2 :shape[0] // 2 + shape[0], shape[1] // 2: shape[1] + shape[1] // 2] = data_new.img.copy()
data_new.set_img(plate)
data_new.set_name(data.name + "_shrink")
return data_new
else:
return None

mosaic技术是YOLOv4的技巧之一,也是一种用于增强网络对小目标的泛化能力所使用的手段,见论文YOLOv4: Optimal Speed and Accuracy of Object Detection,思想就是随机读取四张图像,然后将这些图像随机进行数据增强,如翻转,旋转等等,然后进行组合,原文中四张图像的尺寸是不一致的。这里为了实现起来方便拼接,对四张图像的尺寸都做了统一处理,处理为长宽皆为600,然后进行组合。
def mosaic(data_list):
"""
mosaic技术需要四张图像才能做
:param data_list:
:return:
"""
img_1 = np.vstack((data_list[0].img.copy(), data_list[1].img.copy()))
img_2 = np.vstack((data_list[2].img.copy(), data_list[3].img.copy()))
img_new = np.hstack((img_1, img_2))
boxes_new = data_list[0].boxes.copy()
for box in data_list[2].boxes:
cod = box.cod
x_min = 600 + cod[0]
y_min = cod[1]
x_max = 600 + cod[2]
y_max = cod[3]
boxes_new.append(Box(label=box.label, cod=[x_min, y_min, x_max, y_max]))
for box in data_list[1].boxes:
cod = box.cod
x_min = cod[0]
y_min = cod[1] + 600
x_max = cod[2]
y_max = cod[3] + 600
boxes_new.append(Box(label=box.label, cod=[x_min, y_min, x_max, y_max]))
for box in data_list[3].boxes:
cod = box.cod
boxes_new.append(Box(label=box.label, cod=[x + 600 for x in cod]))
data_new = Data(name=data_list[0].name + "_mosaic", img=img_new, boxes=boxes_new)
return data_new
为了减小内存的压力,这里选择每四张图像做一次处理,而不是所有的数据都加载进内存进行处理
def do_mosaic(data_list, result):
temp_list = []
data_list = random.sample(data_list, len(data_list))
for data in data_list:
if len(temp_list) < 4:
temp_list.append(resize(data))
if len(temp_list) == 4:
new_data = mosaic(temp_list)
result.append(new_data)
temp_list = temp_list[-3:]
return result
resize()函数的实现,这是一个工具函数,多个处理都用到了这个函数
def resize(data, shape=None):
"""
将图像缩放至600 * 600,方便拼接,
:param shape:
:param data:
:return:
"""
if shape is None:
shape = (600, 600)
img_new = cv2.resize(data.img.copy(), shape)
boxes = []
for box in data.boxes:
cod = box.cod
x_min = int(shape[0] / data.shape[1] * cod[0])
y_min = int(shape[0] / data.shape[0] * cod[1])
x_max = int(shape[1] / data.shape[1] * cod[2])
y_max = int(shape[1] / data.shape[1] * cod[3])
box_tmp = Box(label=box.label, cod=[x_min, y_min, x_max, y_max])
boxes.append(box_tmp)
data_new = Data(name=data.name, boxes=boxes, img=img_new)
return data_new

当load所有的数据之后,需要对这个列表进行处理, 以上的每个函数都是对data对象进行处理,但是实际要处理的是一个data的列表,为了少些for循环,所以用一个函数去对以上的每一种处理进行封装。
def do(func, data_list, ret, ext=None):
if ext is None:
for data in data_list:
new_data = func(data)
if new_data is not None:
ret.append(new_data)
else:
for data in data_list:
new_data = func(data, ext)
if new_data is not None:
ret.append(new_data)
为了节约时间使用多线程并行,因为每个线程间的读写都是不相互干扰的,所以不用使用锁
flog_list = os.listdir(flog_path)
flog_list = [os.path.join(flog_path, x) for x in flog_list]
ret = []
# 旋转,加雾,高斯模糊和反转使用并行
t1 = threading.Thread(target=do, args=(rot90, data_list, ret))
t1.start()
t1.join()
t2 = threading.Thread(target=do, args=(flip_vertical, data_list, ret))
t2.start()
t2.join()
t3 = threading.Thread(target=do, args=(gaussian_blur, data_list, ret))
t3.start()
t3.join()
t4 = threading.Thread(target=do, args=(add_flog, data_list, ret, flog_list))
t4.start()
t4.join()
# 小目标复制, 马赛克和大目标放大并行
data_list += ret
ret = []
print("processing 1")
t5 = threading.Thread(target=do, args=(copy_small, data_list, ret))
t5.start()
t5.join()
t6 = threading.Thread(target=do, args=(shrink, data_list, ret))
t6.start()
t6.join()
t7 = threading.Thread(target=do_mosaic, args=(data_list,ret))
t7.start()
t7.join()
data_list += ret
save(data_list, save_path)
有了经过处理之后的数据,这些数据目前还在内存中,需要将这些数据存到本地(也可以将这些代码放到网络处理数据数据输入的部分也可以)
def save(data_list, save_path):
annotation_path = os.path.join(save_path, "Annotations")
img_path = os.path.join(save_path, "JPEGImages")
if not os.path.exists(annotation_path):
os.mkdir(annotation_path)
if not os.path.exists(img_path):
os.mkdir(img_path)
for data in data_list:
img = data.img
name = os.path.join(img_path, data.name +".tif")
cv2.imwrite(name, img)
print("saving image %s to %s" %(data.name +".tif", img_path))
tree = data2xml(data)
tree.write(os.path.join(annotation_path, data.name +".xml"), "utf-8", True)
print("saving annotation %s to %s" % (data.name +".xml", annotation_path))
将data中的数据转化成xml的ElementTree对象
def data2xml(data):
"""
将data中的数据解析成xml格式的tree
:param data:
:return:
"""
root = ET.Element("annotation")
folder = ET.SubElement(root, "folder")
folder.text = "VOC"
filename = ET.SubElement(root, "filename")
filename.text = data.name + ".tif"
size = ET.SubElement(root, "size")
width = ET.SubElement(size, "width")
height = ET.SubElement(size, "height")
depth = ET.SubElement(size, "depth")
width.text = str(data.shape[1])
height.text = str(data.shape[0])
depth.text = str(data.shape[2])
source = ET.SubElement(root, "source")
database = ET.SubElement(source, "database")
database.text = "高分软件大赛"
for box in data.boxes:
obj = ET.SubElement(root, "object")
name = ET.SubElement(obj, "name")
name.text = box.label
bndbox = ET.SubElement(obj, "bndbox")
xmin = ET.SubElement(bndbox, "xmin")
ymin = ET.SubElement(bndbox, "ymin")
xmax = ET.SubElement(bndbox, "xmax")
ymax = ET.SubElement(bndbox, "ymax")
xmin.text = str(box.cod[0])
ymin.text = str(box.cod[1])
xmax.text = str(box.cod[2])
ymax.text = str(box.cod[3])
truncated = ET.SubElement(obj, "truncated")
truncated.text = ‘0‘
difficult = ET.SubElement(obj, "difficult")
difficult.text = ‘0‘
pretty_xml(element=root, indent=‘\t‘, newline=‘\n‘)
tree = ET.ElementTree(root)
return tree
对保存好的数据随机选择几个做可视化
def random_check(save_path, num):
"""
随机可视化检查save_path下num个样本
:param save_path:
:param num:
:return:
"""
temp_path = os.path.join(save_path, "tmp")
if not os.path.exists(temp_path):
os.mkdir(temp_path)
font = cv2.FONT_HERSHEY_SIMPLEX
annotation_path = os.path.join(save_path, "Annotations")
img_path = os.path.join(save_path, "JPEGImages")
xml_list = os.listdir(annotation_path)
xml_list = random.sample(xml_list, num)
xml_list = [os.path.join(annotation_path, xml) for xml in xml_list]
for xml in xml_list:
tree = ET.parse(xml)
root = tree.getroot()
img = None
img_name = ‘‘
try:
img_name = root.find("filename").text
img = cv2.imread(os.path.join(img_path, img_name))
except IOError:
RuntimeError("no such file")
except TypeError:
RuntimeError("xml tag error")
for obj in root.iter("object"):
name = obj.find("name").text
box = obj.find("bndbox")
xmin = int(box.find("xmin").text)
ymin = int(box.find("ymin").text)
xmax = int(box.find("xmax").text)
ymax = int(box.find("ymax").text)
img = cv2.putText(img, name, (xmin, ymin), font, 1.2, (255,255,255), 2)
cv2.rectangle(img,(xmin, ymin), (xmax, ymax), (255,0,0),2)
cv2.imwrite(os.path.join(temp_path, img_name), img)
------------恢复内容结束------------
原文:https://www.cnblogs.com/xsliu/p/13482381.html