Bidirectional LSTM-CRF Models for Sequence Tagging. 2015
在2015年,本文第一个提出使用BiLSTM-CRF来做序列标注任务,BiLSTM-CRF模型的优势有三点:
尽管如此,BiLSTM-CRF的成绩只达到了接近SOTA的水准。
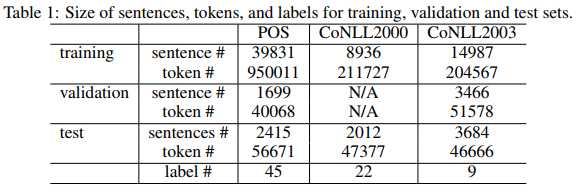
本文在三个数据集上做了测评,Penn TreeBank(PTB)词性标注数据集、CoNLL 2000组块分析(chunking)数据集、CoNLL 2003命名实体标注数据集。
其中,词性标注就是给每个词标上句法角色,比如名词、动词、形容词等等;组块分析是给每个词打上短语类型,比如B-NP表示名词短语的开头;命名实体识别则是给词打上人名、地名、组织名等类型。
数据集的规模如下所示:
有三种,第一种是拼写特征,比如开头字母、大小写、词的构成;第二种是上下文特征,使用unigram特征和bi-grams特征;第三种是词嵌入。
这里面的上下文特征到底是什么样的,论文没有细讲,一笔带过了。。。
在特征连接上,使用了一个技巧:
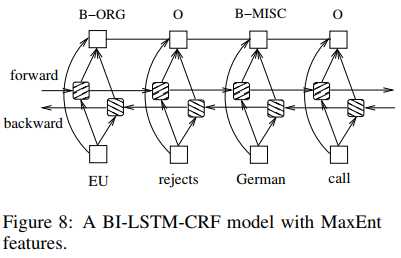
就是把拼写和上下文特征和输出连接起来,不仅可以加速训练,还可以带来相似的标注准确率(有点残差连接的感觉)。
实验的一些经验之谈:
下面是各个LSTM衍生模型的实验结果对比:
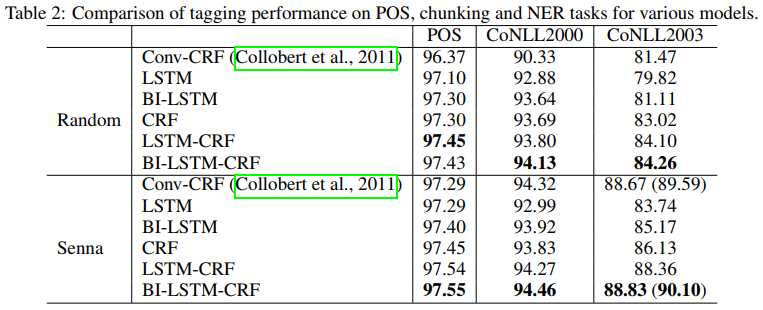
可以看到,在所有基于LSTM的模型中,BiLSTM-CRF表现最好。
接下来还有一些ablation study,只使用词嵌入特征,而不使用拼写特征和上下文特征的对比:
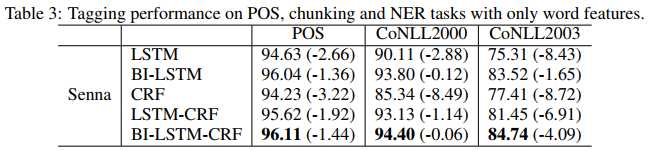
可以看出CRF非常依赖于人工特征;而基于LSTM的模型,BiLSTM和BiLSTM-CRF对此影响较小,具有一定的鲁棒性(词性标注和组块分析是比较小,但是NER上都四个百分点了,这还小吗?)。
再来看看和其他一些模型的对比:
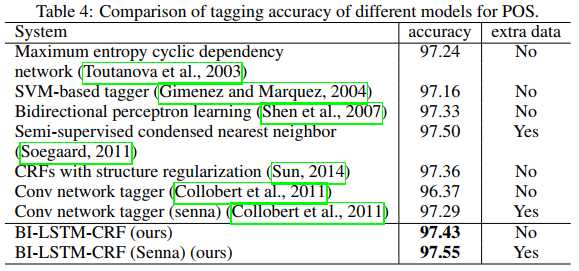
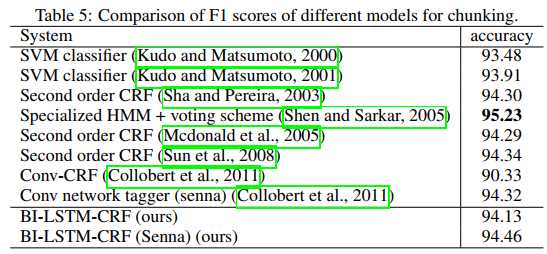
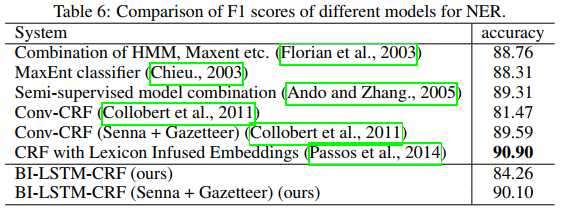
可以看到BiLSTM-CRF不能说是最好,只能说接近SOTA。
原文:https://www.cnblogs.com/YoungF/p/13488220.html