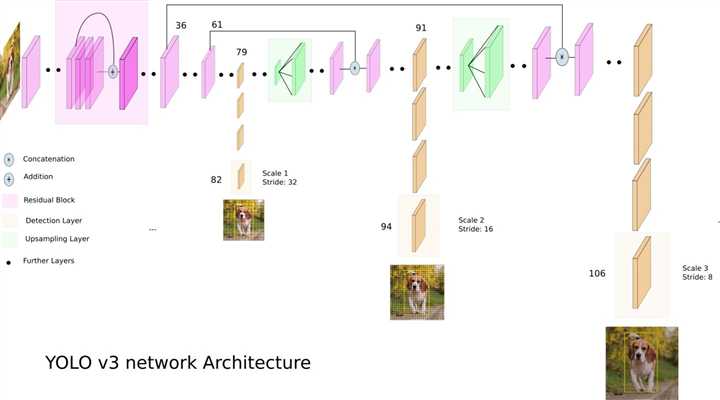
对三层作监督,分别重点检测大中小物体。
如果从未接触过检测算法,一定会对YOLOv3有别于其它CNN的诸多方面深表惊奇。惊奇可能意味着巧妙,也可能意味着不合理或者局限。在YOLOv3身上二者兼备。
Output and loss
需要监督的输出层如下。The shape of the detection kernel is 1 x 1 x (B x (5 + C) ).
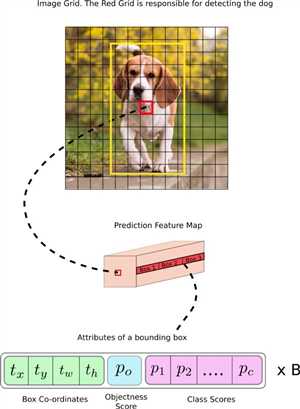
这里有如下令人惊奇之处。
- 输出格式。训练,总是把预测输出与ground truth作比对。我们通常碰到的任务,一个样本通常只(预测)输出一个值,例如,分类中的类别,回归中的实值。而YOLOv3的预测输出N个结构(可以把它理解为c语言的struct),N= cell number * B个,其中B一个cell能预测的bounding box数目(即每一层的anchor数目,实现中一般是取为3)。cell number三层分别为13*13, 26*26, 52*52。结构中有3类成员:bounding box attributes (x, y, w, h),置信度,类别。总共有(5+C)个,5是4 bounding box attributes and one object confidence,C是类个数。
- feature map用途。通常CNN的feature map往往只存在hidden层,最后在输出层通过full connection层或者average polling层转换为vector。而YOLOv3的feature map直接作为输出。通常不同channel用于表示图像的不同特征。而YOLOv3的不同channel不仅可以表达是图像特征,例如人、车这种类别,还可以表达坐标和置信度。
YOLOv3
原文:https://www.cnblogs.com/tracydzf/p/13493025.html