Solr是一个独立的企业级搜索应用服务器, 用户可以通过http请求访问这个服务器, 获取或者写入对应的内容, 其底层是Lucene.
?途径1: 官网网址: http://lucene.apache.org/ 与Lucene的官网是同一个
?途径2: 下载历史版本的网址: http://archive.apache.org/dist/lucene/solr/
--bin solr脚本文件
--contrib solr依赖文件
--dist solr依赖文件
--docs solr使用文档
--example solr实例
solr内置服务器默认端口8983
访问localhost:8080/solr打开solr管理界面
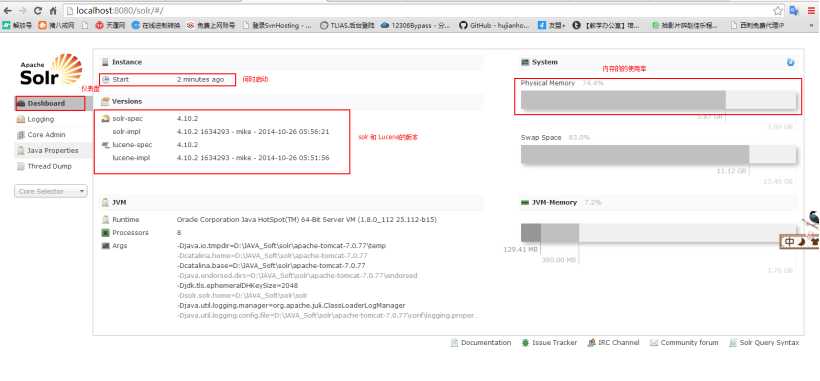
选择索引库,在solr管理界面的Core Selector选择索引库
在solr配置中的collextion1复制一份为collection2,并删除collection2的data文件夹,修改core.properties配置文件将其中的name属性改为当前collection2。在solr管理界面上就可以选择collection2索引库。

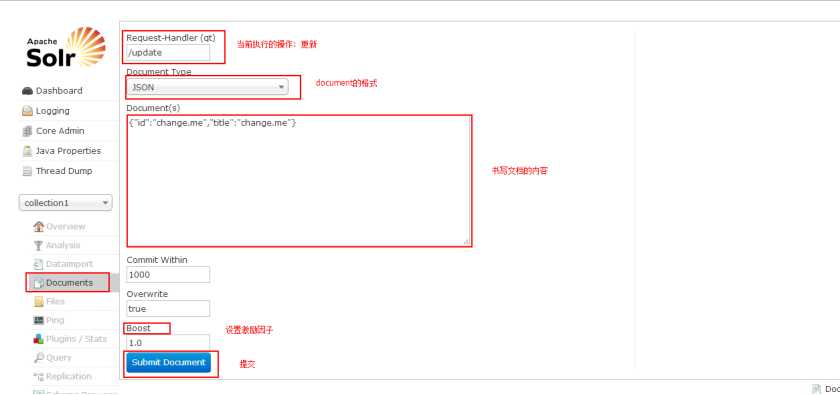
solrconfig.xml 配置文件主要定义了 solr 的一些处理规则,包括索引数据的存放 位置,更新,删除,查询的一些规则配置。
一般此文件不需要进行修改, 采取默认即可
Solr中会提前对文档中的字段进行定义,并且在schema.xml中对这些字段的属性进行约束,例如:字段数据类型、字段是否索引、是否存储、是否分词等等.
第一种标签为 field标签: 主要是用来指定字段名称的, Lucene中是有用户在程序中指定, solr中需要提前在配置文件中指定.
name: 字段的名称
type: 字段的类型
indexed: 是否索引
stored: 是否保存
multiValued: 是否多值, 这个字段, 类似存储一个数组
这里有两个不允许删除的: 一个是 version_ 一个是 root_ 这两个是solr内部需要使用的字段.
有一个字段的名称必须为id,其类型都不允许进行修改.原因是id字段已经被主键使用uniqueKey.
其余的是一些初始化好的字段.
第二种标签为dynamicField, 被称为是动态字段
此种标签是为程序的扩展所使用的, 因为我们不可能把所有的字段全部定义好, 所以就需要动态域来进行动态扩展
第三种标签为 uniqueKey: 必要标签, 表名文档的唯一属性, 一般默认为id
第四种标签为 copyField: 被称为是复制域
????????source: 表名要复制那个字段的值
????????dest: 复制到那个字段上
此种标签主要是为了查询所使用的,
例如, 当查询Text字段的时候, 实质上相当于查询title和name两个字段
? 第五种标签: fieldType ??字段类型定义标签-->
<fieldType name="managed_en" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.ManagedStopFilterFactory" managed="english" />
<filter class="solr.ManagedSynonymFilterFactory" managed="english" />
</analyzer>
</fieldType> ?
此种标签是用来定义字段的类型的,可以指定此字段使用何种分词器进行分词.
? 第一步: 导入ik相关的依赖包
? 将jar包放置在tomcat>webapps>solr>WEB-INF>lib下
IKAnalyzer2012FF_u1.jar
? 第二步: 导入ik相关的配置文件(ik配置文件, 扩展词典和停止词典)
ext.dic拓展词典(数据自己添加,分词)
stopword.dic停止字典(常存储句末语气词,如啊,了,哦)
IKAnalyzer.cfg.xml ik配置文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
-<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典-->
<entry key="ext_dict">ext.dic;</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic;</entry>
</properties>
? 将三个文件放置在tomcat>webapps>solr>WEB-INF>classes下
? 第三步, 在schema.xml配置文件中自定义一个字段类型, 引入ik分词器
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
? 第四步: 为对应的字段设置为text_ik类型即可
<field name="content" type="text_ik" indexed="false" stored="true" multiValued="true">
solrj是Apache官方提供的一套java开发的, 用于操作solr服务的API, 通过这套API可以让程序与solr服务进行交互, 让java程序可以直接操作solr服务进行增删改查
solrj的官网网址: https://wiki.apache.org/solr/Solrj
<dependency>
???? <groupId>org.apache.solr</groupId>
???? <artifactId>solr-solrj</artifactId>
???? <version>4.10.2</version>
????</dependency>
????<dependency>
??? <groupId>commons-logging</groupId>
???? <artifactId>commons-logging-api</artifactId>
???? <version>1.1</version>
????</dependency>
写入一个文档对象
//1.索引写入器对象
SolrServer solrServer = new HttpSolrServer("http://localhost:8081/solr/collection1");
//2.添加文档
SolrInputDocument document = new SolrInputDocument();
document.addField("id",10);
document.addField("title","日期类型");
document.addField("content","maven是一个管理项目依赖和构建的工具");
document.addField("hiredate","2019-08-18T16:00:00Z");
solrServer.add(document);
//3.提交数据
solrServer.commit();
写入多个文档对象
//1.索引写入器对象
SolrServer solrServer = new HttpSolrServer("http://localhost:8081/solr/collection1");
//2.添加文档
List<SolrInputDocument> docs = new ArrayList<SolrInputDocument>();
SolrInputDocument doc1 = new SolrInputDocument();
doc1.addField("id","5");
doc1.addField("title","mysql简介");
doc1.addField("content","mysql是一个高效的关系型数据库");
docs.add(doc1);
SolrInputDocument doc2 = new SolrInputDocument();
doc2.addField("id","6");
doc2.addField("title","redis简介");
doc2.addField("content","redis是一个内存型的非关系型数据库");
docs.add(doc2);
solrServer.add(docs);
//3.提交数据
solrServer.commit();
写入javabean对象
public class News {
@Field
private String id;
@Field
private String title;
@Field
private String content;
@Field
private String url;
//此处省略了 get 和 set方法
}
SolrServer solrServer = new HttpSolrServer("http://localhost:8081/solr/collection1");
News news = new News(7,"张三","mybatis简介","mybatis是是一个优秀的持久层框架","http://www.qq.com");
solrServer.addBean(news);
solrServer.commit();
? 注意事项:
– 如果使用javaBean进行数据添加时, 需要给对应要加入索引库的字段添加@Field,用来指定其实一个document字段
– javaBean中的字段必须提前在solr的schema.xml中提前定义好
SolrServer solrServer = new HttpSolrServer("http://localhost:8081/solr/collection1");
//索引库中存在相同id属性的对象,则为修改
News news = new News(7,"李四","mybatis简介","mybatis是是一个优秀的持久层框架","http://www.qq.com");
solrServer.addBean(news);
solrServer.commit();
SolrServer solrServer = new HttpSolrServer("http://localhost:8081/solr/collection1");
//删除索引
//solrServer.deleteByQuery("*:*") //删除所有
solrServer.deleteById("change.me1");
solrServer.commit();
//创建一个索引服务
SolrServer solrServer = new HttpSolrServer("http://localhost:8081/solr/collection1");
//创建索引查询对象
SolrQuery query = new SolrQuery("*:*");
//执行查询;
QueryResponse response = solrServer.query(query);
//文档的集合
SolrDocumentList list = response.getResults();
for (SolrDocument document : list) {
String id = (String)document.get("id");
String title = (String)document.get("title");
String content = (String)document.get("content");
System.out.println("id:"+id+",title:"+title+",content:"+content);
}
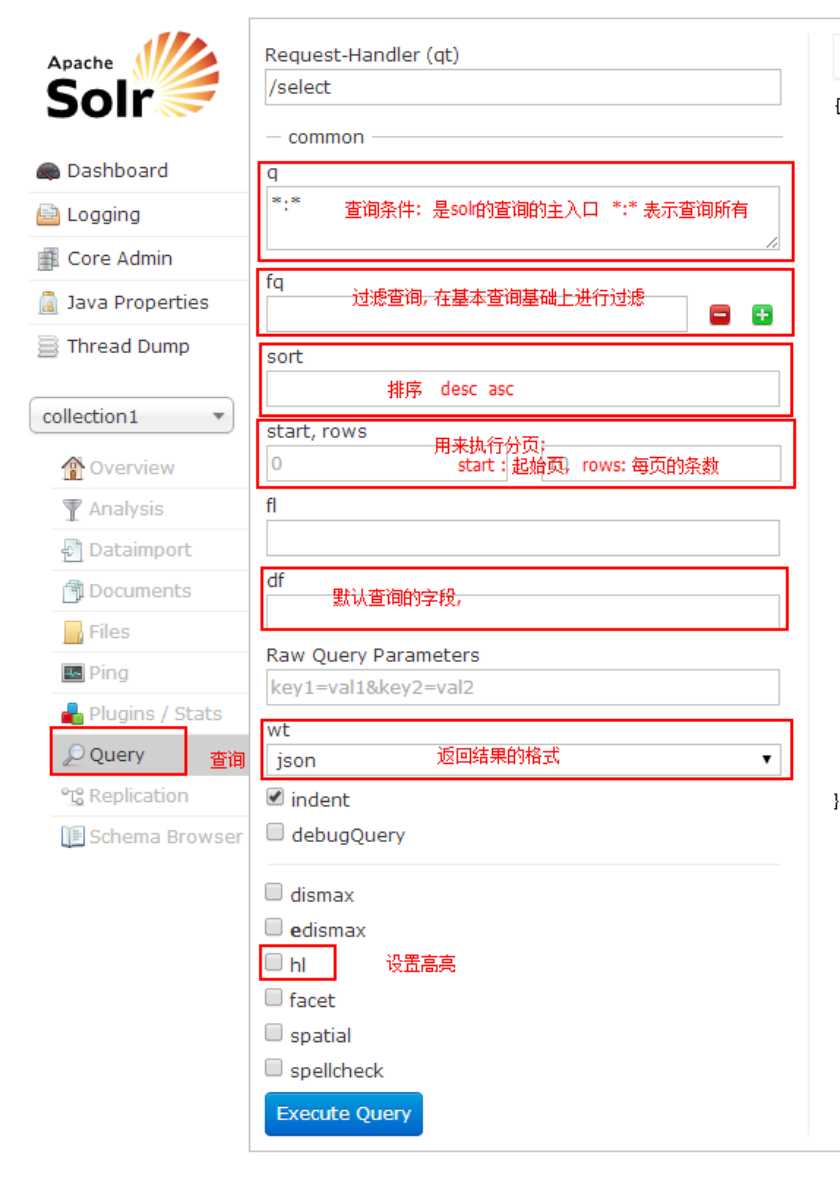
在创建SolrQuery时,我们填写的Query语句,可以有以下高级写法:
查询语句中如果有特殊字符,需要转义,可以使用: ” ”
1、匹配所有文档:: (通配符?和 * :“*”表示匹配任意字符;“?”表示匹配出现的位置)
2、布尔操作:AND、OR和NOT布尔操作(推荐使用大写,区分普通字段)
3、子表达式查询(子查询):可以使用“()”构造子查询。 比如:(query1 AND query2) OR (query3 AND query4)
4、相似度查询:
(1)默认相似度查询:title:appla~,此时默认编辑距离是2
(2)指定编辑距离的相似度查询:对模糊查询可以设置编辑距离,可选02的整数:title:appla1。
5、范围查询(Range Query):Lucene支持对数字、日期甚至文本的范围查询,并且两端范围。结束的范围可以使用“*”通配符。
(1)日期范围(ISO-8601 时间GMT):birthday:[1990-01-01T00:00:00.000Z TO 1999-12-31T24:59:99.999Z]
(2)数字:age:[2000 TO *]
(3)文本:content:[a TO a]# solr
原文:https://www.cnblogs.com/ygfcoder/p/13496525.html