在前几篇讲内存管理的时候,提到地址空间是内存的抽象。那进程就是CPU的抽象,一个程序运行起来以后就是一个进程,线程是进程创建出来的,其本身并不能独立运行,一个进程可以创建出来多个线程,他们之间会共享进程的堆空间,公共变量等。本文就详细介绍一个进程和线程基础。
一个具有一定独立功能的程序在一个数据集合上的一次执行过程。这是清华大学操作系统公开课上给的定义。觉得不用做过多解释,相信大家应该都明白。
操作系统用于管理进程所用的信息集合。linux中 task_struct描述符结构体表示一个进程的控制块,这个 task_struct结构记录了这个进程所有的context (进程上下文信息)
struct task_struct{ //列出部分字段 volatitle long state;//表示进程当前的状态 ,-1表示不可运行,0表示可运行,>0表示停止 void *stack; //进程内核栈 unsigned int ptrace; pid_t pid;//进程号 pid_t tgid;//进程组号 struct mm_struct *mm,*active_mm //用户空间 内核空间 struct list_head thread_group;//该进程的所有线程链表 struct list_head thread_node; int leader;//表示进程是否为会话主管 struct thread_struct thread;//该进程在特定CPU下的状态 //等等字段:包括一些 表示 使用的文件描述符、该进程被CPU调度的次数、时间、父子、兄弟进程等信息 }
在linux中,进程的信息在/proc文件夹下保存着。如果想看某个pid的信息,可以使用ps或者top等命令获取。进程控制块在内存的组织形式有两种方式,一种是链表方式,每个PCB以链表的方式连接在一起,另一种是索引的方式,索引的指针指向进程控制块。系统中的所有进程的信息都会保存到进程控制块的链表中。
由于现代操作系统,大多是采用时间片的方式来执行进程,就是每个进程执行一段时间,相互交替执行,所以进程就有了很多的中间状态,下面就介绍一下这些状态。
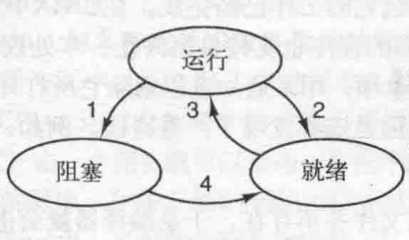
图片来源:现代操作系统
这里说明一下什么是时间片,举个例子,CPU给每个进程的执行时间是20ns,那如果某个进程20ns没有执行完,会切换到别的进程执行,那20ns就是时间片的大小。
在解释一下上面状态之间的切换。
上面只介绍了三种状态,其实还有一种状态,僵尸状态,下面就简略介绍一下
父进程可以通过fork来创建子进程,当子进程结束的时候,可以直接调用exit退出,这个时候进程的资源就会全部被回收,但是进程控制块是操作系统管理的,这个还没有被回收,由于进程用户态资源已经全部释放了,无法再回到用户态发出系统调用,回收进程控制块(PCB),只能交给他的父进程进行回收,在程序执行了exit,而父进程还没有回收进程控制块这段时间进程既不是就绪状态,也不是等待状态,而是处于一种僵尸状态(就是半死不死的状态)。上面的解释是清华大学操作系统公开课老师给的一种解释,不太明白为什么在进程资源被回收完之后,不把进程的唯一标示PCB也给回收掉,而要交给父进程进行回收,有明白的胖友,欢迎指教。
线程其实是一种轻量级进程,通常一个进程由多个线程组成,各个线程共享进程的内存空间(包括数据,代码,堆,打开的文件,信号等),一个典型的线程和进程的关系图如下
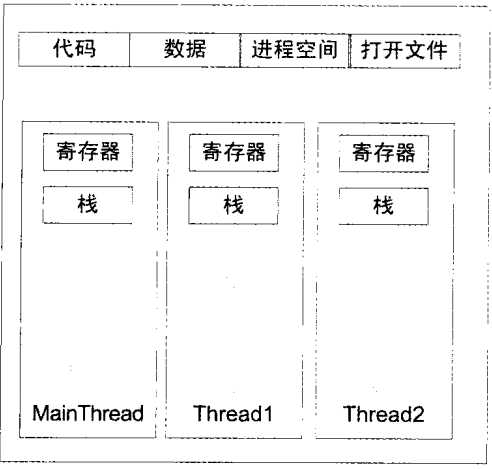
图片来源:程序员的自我修养
线程之间虽然可以共享同一个进程的很多资源,但是线程仍然有私有存储空间,如下
上面几个存储空间,我想介绍一个TLS,在牛客网上有这么一个题。
链接:https://www.nowcoder.com/questionTerminal/a0c59b5a3e71436a86c3cc1f6392e55f 来源:牛客网 (多选题) 对于线程局部存储TLS(thread local storage),以下表述正确的是 A. 解决多线程中的对同一变量的访问冲突的一种技术 B. TLS会为每一个线程维护一个和该线程绑定的变量的副本 C. 每一个线程都拥有自己的变量副本,从而也就没有必要对该变量进行同步了 D. Java平台的java.lang.ThreadLocal是TLS技术的一种实现
牛客上给的正确答案是ABD,C之所以错误是如果TLS中保存的是变量的引用,多个线程并发修改时,还是有同步的问题,所以C错误,具体解释看这篇文章,而B说每个线程维护一个变量副本,意思是说每个线程都会获取到相同的具有初始化值的变量副本,至于之后每个线程怎么改,是相互独立的。
这篇文章更详细的介绍了TLS,有兴趣的可以看看:有必要澄清一下究竟TLS(or java‘s thread local)的作用是什么
从数据的角度来看,是否私有如下表

由于进程调度还没有写,不过大家应该都听说过操作系统分时调度,那既然要切换不同的进程,就要把之前运行的进程一些信息给保存起来,什么信息呢,比如寄存器中的临时变量,程序计数器等,然后加载另外一个进程的临时变量,程序计数器,并跳转到指定的地方运行,这个过程就叫做上下文切换。
下面就详细介绍一下这三种上下文切换。
进程上下文分为进程内上下文切换和进程间上下文切换,先介绍进程内上下文切换。
在现代操作系统中,有两种运行状态,用户态和内核态,用户态运行着特权级别比较低的程序,只能访问部分资源,内核态运行着特权级别比较高的程序,可以访问所有的硬件和功能,比如操作系统,而处于用户态的程序如果想要执行某个特权级别比较高的操作,就需要调用操作系统暴露的接口,这个过程叫做系统调用,而系统调用需要程序从用户态切换到内核态运行,这个过程会发生上下文切换。
举个例子,printf("hello world"),这个操作就需要系统调用,上下文切换的过程如下
所以一次系统调用发生了两次上下文切换(用户态 -> 内核态 -> 用户态)
系统调用上下文切换,切换到内核态之后,并不需要虚拟内存等用户空间的资源,而且也不会切换进程,只需要加载内核态的程序计数器和寄存器、堆、栈等资源。
进程上下文切换的场景如下
由于进程是由内核管理的,因此进程的切换只能发生在内核态,所以进程间上下文切换不光需要把用户态的寄存器、程序计数器、堆栈,虚拟地址空间等信息保存起来,还需要把内核中的进程的状态,堆栈信息保存起来。
进程间上下文切换就比系统调用多了一步,切换到另一个进程的时候需要加载进程用户态的资源,而系统调用,进入内核态的时候是不牵涉到用户态的资源的,所以就无须加载用户态的资源。
操作系统为了安全,限制用户程序的特权级别,就牺牲了效率。同样,操作系统为了公平,让每个程序都有执行的机会,搞了个分时调度,同样牺牲了效率(不包括程序执行I/O等操作的情况,这种情况切换别的进程执行是提高效率的???),上下文切换时间不只是浪费在需要保存寄存器,堆栈等信息和重新加载另一个进程的寄存器,堆栈信息。还有之前介绍虚拟地址空间的时候,介绍过,为了加快虚拟地址和物理地址的映射,在CPU中有一个MMU,MMU中有一个TLB硬件,用来缓存最近经常使用的映射关系,那如果发生上下文切换就需要从内存中的页表中读取映射关系,再缓存到TLB中,这个过程也会浪费时间。
上面已经介绍过线程,同一个进程的线程会共享很多的资源,这些在线程上线文切换的时候是不需要保存的,需要保存的是线程自己私有的数据,就是上面介绍过的寄存器,栈,TLB等。
中断,在第一篇文章中已经介绍过,这里就不介绍了,中断上下文切换有点像系统调用,因为系统调用和中断都是操作系统执行的,所以都发生在内核态,也就是说在处理中断的时候不涉及到用户态的虚拟地址空间、堆、栈等信息。
本文介绍了进程、线程、上下文切换 。进程介绍了进程的组成和进程的状态,线程介绍了线程的组成,上下文切换分别介绍了进程上下文切换、线程上下文切换、中断上线文切换,总的来说把基础的知识给概括的介绍了一下,之后会介绍进程调度和线程安全相关的内容。

参考:
《现代操作系统》
《程序员的自我修养》
清华大学操作系统公开课
原文:https://www.cnblogs.com/gunduzi/p/13504298.html