操作系统: CentOS6.7
jdk: jdk-8u221
hadoop: 2.7.3
一. 卸载系统自带jdk并安装准备好的jdk
1. 查看: rpm -qa | grep jdk
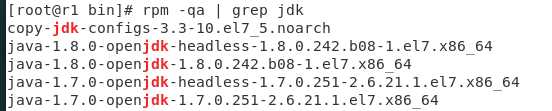
2.卸载: yum -y remove xxxx
3.安装jdk1.8
解压jdk包
tar zxvf jdkxxxx.tar.gz

重命名: mv jdk1.8.0_221/ jdk1.8

或者给jdk目录创建软连接 ln -s jdk1.8 jdk ( 用jdk 代替jdk1.8)
配置jdk环境变量(我装在全局下,所以修改的配置文件是/etc/profile,如果是普通用户则修改 ~/.bashrc)

使配置生效: source /etc/profile (普通用户 source ~./bashrc)
使用java -version 可以查看安装的jdk版本

二. 解压hadoop压缩包
tar zxvf hadoopxxxx.tar.gz
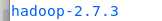
修改名字为hadoop2.7: mv hadoop-2.7.3 hadoop2.7
配置环境变量
vi profile

source /etc/profile
测试一下

成功了, 系统找到了hdfs命令在的目录
三.克隆出另外两台主机
主机1 : hostname:hadoop1 ip:192.168.253.128
主机2 : hostname:hadoop2 ip:192.168.253.129
主机3 : hostname:hadoop3 ip:192.168.253.130
按以上分配修改相应的系统配置
四. 配置主机间两两免密登录(每台主机都要做)
修改/etx/hosts 文件 ,在末尾追加

关闭防火墙 :
永久关闭: chkconfig iptables off
在hadoop1上生成密钥对
$ ssh-keygen -t rsa
连续敲三次回车后会在~下生成.ssh文件夹.
将hadoop1公钥 id_rsa.pub复制到hadoop1,hadoop2,hadoop3中
$ ssh-copy-i ~/.ssh/id_rsa.pub hadoop1
$ ssh-copy-i ~/.ssh/id_rsa.pub hadoop2
$ ssh-copy-i ~/.ssh/id_rsa.pub hadoop3
...
测试一下 在任意一台主机上输入ssh hadoop2
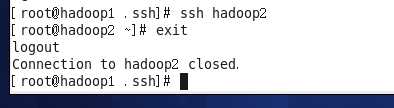
不用输入密码即可登录hadoop2 即表示免密成功
五. ntp服务(centos自带了就不赘述)
六. 设置Hadoop配置文件
1.vi hadoop-env.sh

2.vi core-site.xml
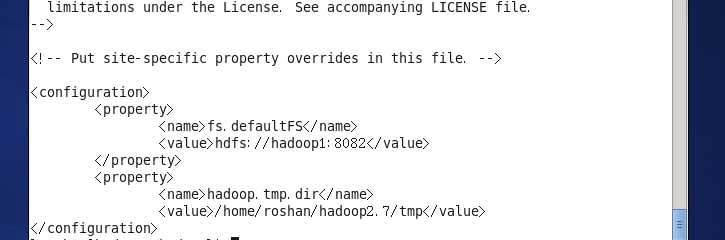
每一台都要创建这个tmp文件夹
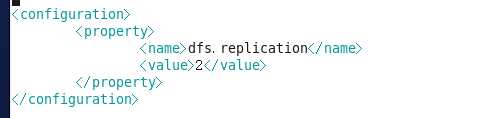
3. vi hdfs-site.xml
4. cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml

5. vi yarn-site.xml
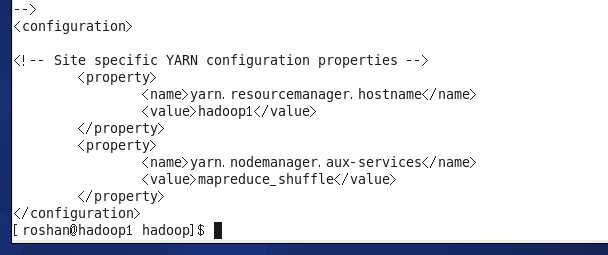
6. vi slavers

7. 分发配置到hadoop2,hadoop3
scp -r ~/hadoop2.7/etc/hadoop roshan@hadoop2:~/hadoop2.7/etc/
scp -r ~/hadoop2.7/etc/hadoop roshan@hadoop3:~/hadoop2.7/etc/
七.启动Hadoop
初始化namenode : hdfs namenode -format
启动hadoop: start-all.sh
在hadoop1里有一下进程
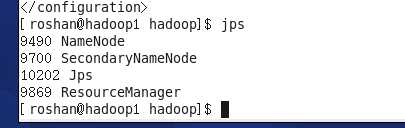
在hadoop2,hadoop3中有


说明分布式成功搭建
在windows浏览器中打开192.168.253.128:50070/192.168.253.128:50090

可以看到有两个datanode
原文:https://www.cnblogs.com/jkluo/p/13511670.html