类继承结构图
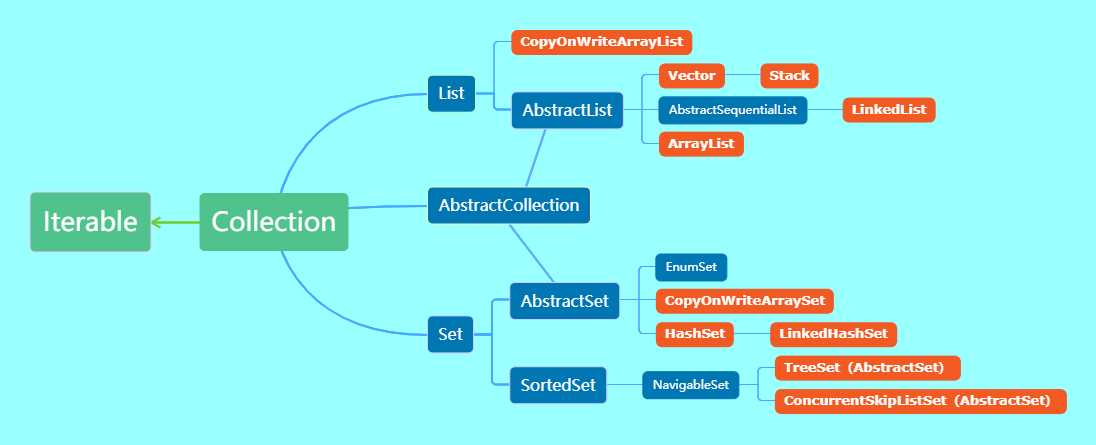
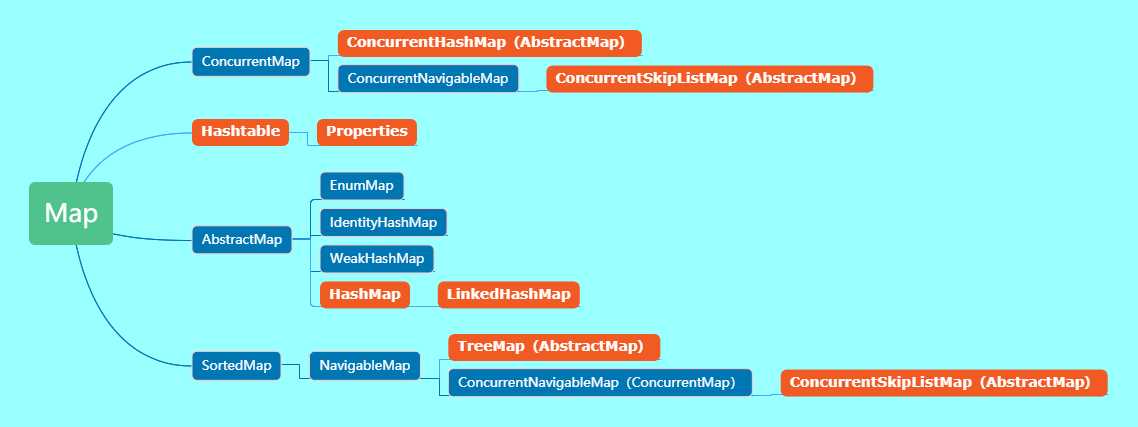
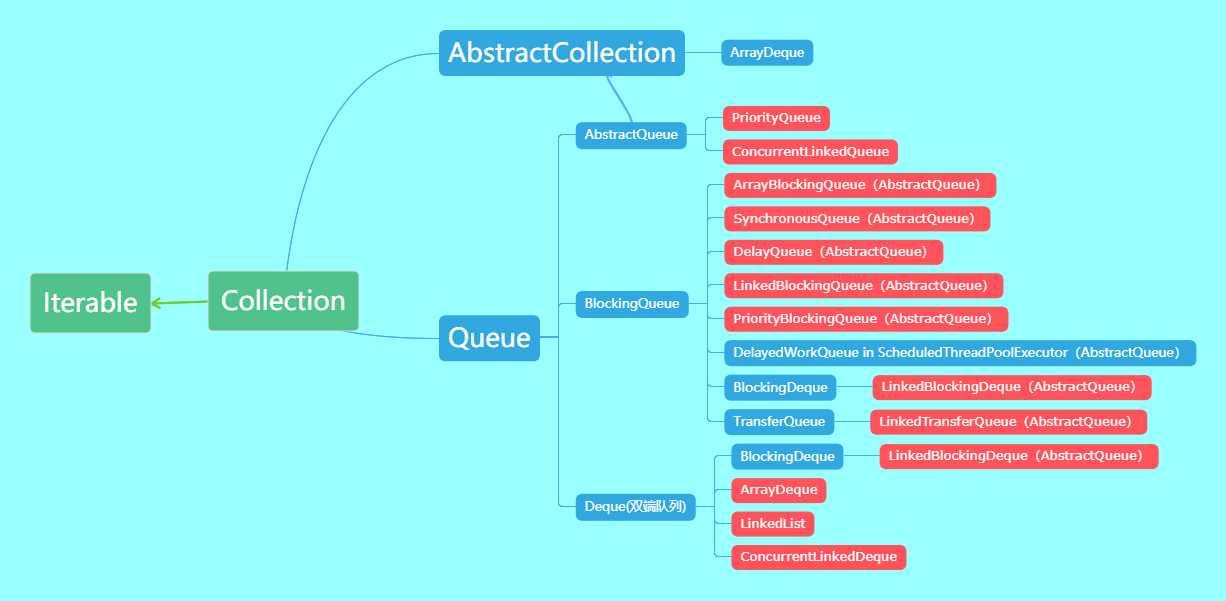
HashMap
1. 对象的HashCode是用来在散列存储结构中确定对象的存储地址的。
2. 如果两个对象的HashCode相同,即在数组中的地址相同。而数组的元素是链表。这两个对象会放在同一链表上。
3. 如何确定是同一个对象? 通过equals方法。
4. HashMap默认的加载因子是0.75,默认最大容量是16。扩容大小:扩容原来的一倍。
因此可以得出HashMap的默认实际容量是:0.75*16=12,到了12就会扩容。
5. JAVA 7中的HashMap是数组和链表的结合体。JAVA 8中是数组 + 红黑树实现。
ConcurrentHashMap
1. JDK1.7版本:ReentrantLock+Segment+HashEntry
JDK1.8版本中synchronized+CAS+HashEntry+红黑树,已经接近HashMap,相对而言,ConcurrentHashMap只是增加了同步的操作来控制并发。
2. 查询时间复杂度:从原来的遍历链表O(n),变成遍历红黑树O(logN)。
3. 定位一个元素的过程需要进行两次Hash操作。第一次Hash定位到Segment,第二次Hash定位到元素所在的链表的头部。
TreeSet与TreeMap :可以保证按大小排序。
LinkedHashSet与LinkedHashMap:加了一个双向链表,能保证添加的顺序。
ArrayList与LinkedList:即数组和链表的优缺点。查询前者更高效,添加删除后者更高效。
线程不安全的类
HashMap、HashSet、ArrayList、LinkedList、TreeSet、TreeMap
同步容器
ArrayList -> Vector、Stack
HashMap -> HashTable(key和value不能为空)
- HashMap不是线程安全的,多线程环境容易导致CPU 100%
- HashTable使用synchronized来保证线程安全,效率低下。
Collections.synchronizedXXX(List,Set,Map):原理是直接使用synchronized修饰。一般并发够用,但是高并发情况下需要使用并发容器。
Collections.synchronizedList(l1);
Collections.synchronizedMap(new HashMap<String,String>());
Collections.synchronizedSet(new HashSet<String>());
Collections.synchronizedSortedMap(new TreeMap<String,String>());
Collections.synchronizedSortedSet(new TreeSet<String>());
并发容器 J.U.C(比同步容器更适合高并发)
ArrayList -> CopyOnWriteArrayList
写写才会阻塞,写不阻塞读。 适合大小比较小且读多写少的场景
HashSet -> CopyOnWriteArraySet
适合大小比较小且读多写少的场景
TreeSet(大小顺序) -> ConcurrentSkipListSet(同步+大小顺序)
适合大小比较小且读多写少的场景
HashMap -> ConcurrentHashMap(同步)
锁分段技术-数据分成一段一段存储(一段对应一个hashEntry数组,每个数组是一个链表结构的元素) ,为每一段数据分配一把锁,多线程访问不同数据段时,就不会产生竞争了。
TreeMap(大小顺序) -> ConcurrentSkipListMap(同步+大小顺序)
ConcurrentLinkedQueue 高效的并发队列,是高并发中性能最好的队列,先进先出,使用链表实现。入队了出队都采用CAS算法。(线程安全的LinkedList)
原文:https://www.cnblogs.com/caoshouling/p/13515281.html