首先我们来看下 ZooKeeper 的总体架构图。
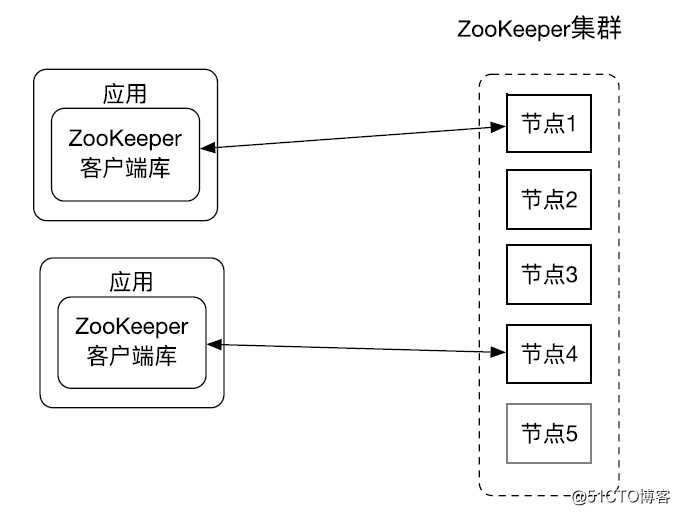
应用使用 ZooKeeper 客户端库来使用 ZooKeeper 服务,ZooKeeper 客户端会和集群中某一个节点建立 session, ZooKeeper 客户端负责和 ZooKeeper 集群的交互。ZooKeeper 集群可以有两种模式:standalone 模式和 quorum 模式。处于 standalone 模式的 ZooKeeper 集群还有一个独立运行的 ZooKeeper 节点,standalone 模式一般用来开发。实际生产环境 ZooKeeper 一般处于 quorum 模式,在 quorum 模式下 ZooKeeper 集群包换多个 ZooKeeper 节点。
Session 是 ZooKeeper 客户端的一个重要概念,ZooKeeper 客户端库和 ZooKeeper 集群中的节点创建一个 session。客户端可以主动关闭 session。另外如果 ZooKeeper 节点没有在 session 关联的 timeout 时间内收到客户端的数据的话,ZooKeeper 节点也会关闭 session。另外 ZooKeeper 客户端库如果发现连接的 ZooKeeper 出错,会自动的和其他 ZooKeeper 节点建立连接。
下图展示了 ZooKeeper 客户端是如何进行重连的?
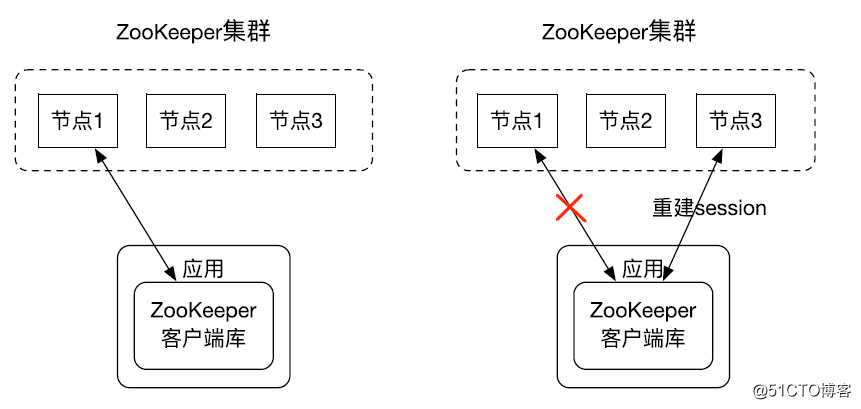
刚开始 ZooKeeper 客户端和 ZooKeeper 集群中的节点 1 建立的 session,在过了一段时间后,ZooKeeper 节点 1 失败了,ZooKeeper 客户端就自动和 ZooKeeper 集群中的节点 3 重新建立了 session 连接。
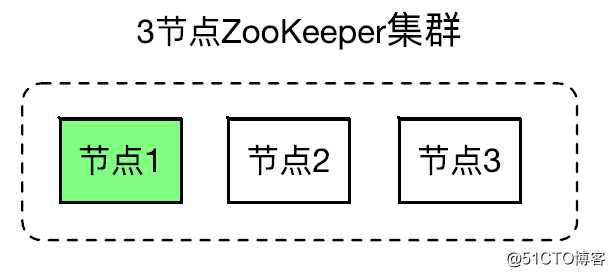
处于 Quorum 模式的 ZooKeeper 集群包含多个 ZooKeeper 节点。下图的 ZooKeeper 集群有 3 个节点,其中节点 1 是 leader 节点,节点 2 和节点 3 是 follower 节点。集群中只能有一个 leader 节点,可以有多个 follower 节点,leader 节点可以处理读写请求,follower 只可以处理读请求。follower 在接到写请求时会把写请求转发给 leader 来处理。
下面来说下 ZooKeeper 保证的数据一致性:
数据一致性
为了让大家更好地理解 Quorum 模式,下面会配置一个 3 节点的 Quorum 模式的 ZooKeeper 集群。
首先需要准备 3 个配置文件,dataDir 和 clientPort 配置项要配置不同的值。3 个配置文件的 server.n 部分都是一样的。在 server.1=127.0.0.1:3333:3334,其中 3333 是 quorum 之间的通信的端口号,3334 是用于 leader 选举的端口号。
还需要在每个节点的 dataDir 目录下创建 myid 文件,里面内容为一个数字,用来标识当前主机,配置文件中配置的 server.n 中 n 为什么数字,则 myid 文件中就输入这个数字。
如下是第 1 个节点的配置文件,其中目录是 node1,端口号用的是 2181,另外两个节点的目录分别是 node2 和 node3,端口号分别为 2182 和 2183,最下面的三行都是一样的:
# 心跳检查的时间 2秒
tickTime=2000
# 初始化时 连接到服务器端的间隔次数,总时间10*2=20秒
initLimit=10
# ZK Leader 和follower 之间通讯的次数,总时间5*2=10秒
syncLimit=5
# 存储内存中数据库快照的位置,如果不设置参数,更新事务日志将被存储到默认位置。
dataDir=/data/zk/quorum/node1
# ZK 服务器端的监听端口
clientPort=2181
server.1=127.0.0.1:3333:3334
server.2=127.0.0.1:4444:4445
server.3=127.0.0.1:5555:5556下面来启动这个集群,首先启动第一个节点,启动命令如下:
zkServer.sh start-foreground /usr/local/apache-zookeeper-3.5.6-bin/conf/zoo-quorum-node1.cfg注:start-foreground 选项 zkServer.sh 在前台运行,把日志直接打到 console。如果把日志打到文件的话,这三个 zkServer.sh 会把日志打到同一个文件。
在启动第一个节点后日志中会出现如下:
2019-12-29 13:14:35,758 [myid:1] - WARN [WorkerSender[myid=1]:QuorumCnxManager@679] - Cannot open channel to 2 at election address /127.0.0.1:4445
java.net.ConnectException: Connection refused (Connection refused)
at java.net.PlainSocketImpl.socketConnect(Native Method)
at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:350)
at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:206)
at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:188)
at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392)
at java.net.Socket.connect(Socket.java:589)
at org.apache.zookeeper.server.quorum.QuorumCnxManager.connectOne(QuorumCnxManager.java:650)
at org.apache.zookeeper.server.quorum.QuorumCnxManager.connectOne(QuorumCnxManager.java:707)
at org.apache.zookeeper.server.quorum.QuorumCnxManager.toSend(QuorumCnxManager.java:620)
at org.apache.zookeeper.server.quorum.FastLeaderElection$Messenger$WorkerSender.process(FastLeaderElection.java:477)
at org.apache.zookeeper.server.quorum.FastLeaderElection$Messenger$WorkerSender.run(FastLeaderElection.java:456)
at java.lang.Thread.run(Thread.java:748)原因是配置文件中配置的为 3 个节点,但是只启动了 1 个节点,目前他和其他另外两个节点建立不了连接,所以报这个问题。
接下来启动第 2 个节点,执行命令如下:
zkServer.sh start-foreground /usr/local/apache-zookeeper-3.5.6-bin/conf/zoo-quorum-node2.cfg启动后,我们可以在节点 2 的日志中发现这么一行:
2019-12-29 13:15:13,699 [myid:2] - INFO [QuorumPeer[myid=2](plain=/0.0.0.0:2182)(secure=disabled):Leader@464] - LEADING - LEADER ELECTION TOOK - 41 MS这说明节点 2 成为了 leader 节点,同样可以在节点 1 的日志中发现如下一行日志,说明了节点 1 成为了 follower 节点。
2019-12-29 13:15:13,713 [myid:1] - INFO [QuorumPeer[myid=1](plain=/0.0.0.0:2181)(secure=disabled):Follower@69] - FOLLOWING - LEADER ELECTION TOOK - 61 MS因为对于一个三节点集群来说两个就代表了多数,就形成了 Quorum 模式,接下来启动第 3 个节点,执行命令如下:
zkServer.sh start-foreground /usr/local/apache-zookeeper-3.5.6-bin/conf/zoo-quorum-node3.cfg启动后在日志中也有如下一行,说明第 3 个节点也加入这个集群,并且是作为 follower 节点加入的。
2019-12-29 13:15:52,440 [myid:3] - INFO [QuorumPeer[myid=3](plain=/0.0.0.0:2183)(secure=disabled):Follower@69] - FOLLOWING - LEADER ELECTION TOOK - 15 MS下面来启动客户端来使用这个三节点集群,在命令中加了 -server 选项,后面指定的是三个节点的主机名和端口号,命令如下:
zkCli.sh -server 127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:21832019-12-29 13:45:44,982 [myid:127.0.0.1:2181] - INFO [main-SendThread(127.0.0.1:2181):ClientCnxn$SendThread@1394] - Session establishment complete on server localhost/127.0.0.1:2181, sessionid = 0x101fff740830000, negotiated timeout = 30000通过启动日志可以看到客户端和端口号为 2181 的节点建立了连接,也就是和第 1 个节点建立了连接。
我们执行 ls -R / 命令看下这个集群中的 znode 数据。
[zk: 127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183(CONNECTED) 1] ls -R /
/
/zookeeper
/zookeeper/config
/zookeeper/quota下面我们杀掉一个 ZooKeeper 节点,看客户端是否能进行重连。现在我们连的节点 1,我们来把节点 1 杀掉,可以在客户端的日志中发现客户端和端口号为 2183 的节点重新建立了连接,也就是和节点 3 建立了连接。
2019-12-29 14:03:31,392 [myid:127.0.0.1:2183] - INFO [main-SendThread(127.0.0.1:2183):ClientCnxn$SendThread@1394] - Session establishment complete on server localhost/127.0.0.1:2183, sessionid = 0x101fff740830000, negotiated timeout = 30000然后我们再看下客户端能否正常使用,执行 ls -R / ,可以发现能够正常返回数据,说明客户端是能够正常使用的。
[zk: 127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183(CONNECTED) 4] ls -R /
/
/zookeeper
/zookeeper/config
/zookeeper/quota这篇文章主要讲解了 ZooKeeper 架构,以及怎样配置一个三节点的 ZooKeeper 集群。
完
●ZooKeeper 入门看这篇就够了
●Nginx 热部署和日志切割,你学会了吗?
●Nginx 了解一下?
●你真的了解 volatile 关键字吗?
●Java线程的生老病死
●Java 8 Optional:优雅地避免 NPE

武培轩
有帮助?在看,转发走一波
喜欢作者
原文:https://blog.51cto.com/14901336/2522745