https://www.bilibili.com/video/av94519857?p=8
https://www.bilibili.com/video/av94519857?p=9
-----总结-----




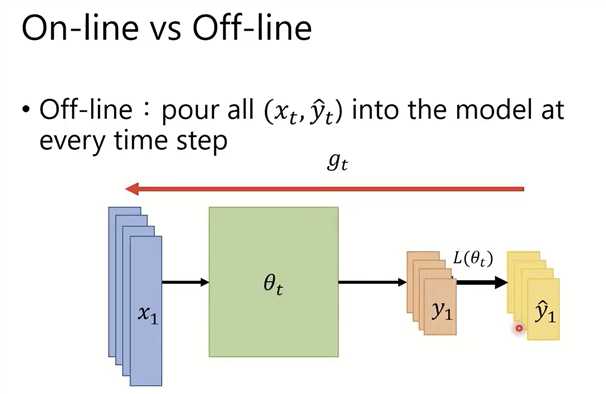
一次能够拿到所有训练数据,就是offline learning。
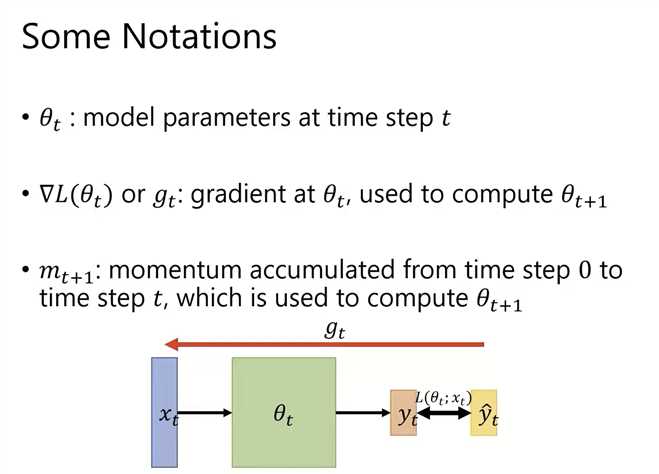
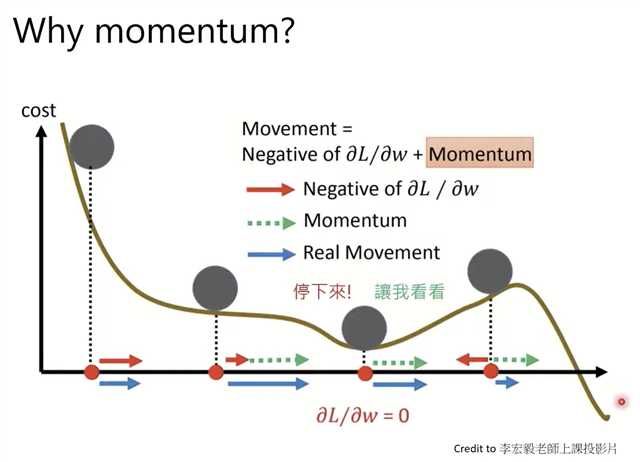
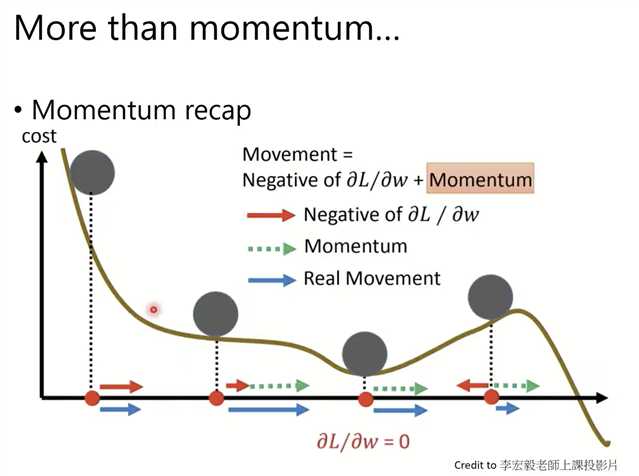
每次梯度反方向
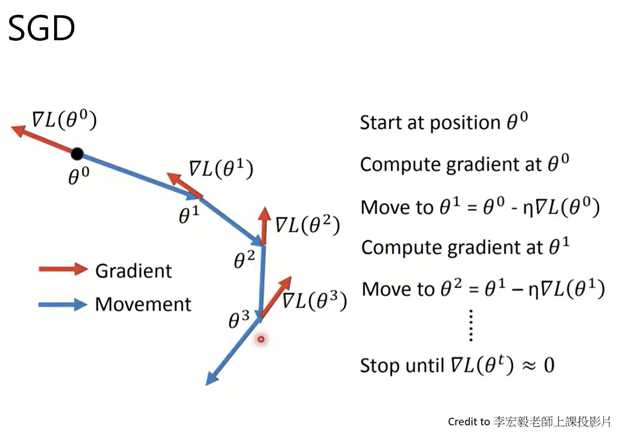
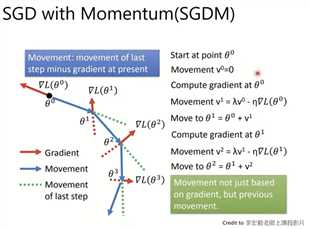
Momentum(累加历史所有梯度,即使当前梯度为0,也会因为历史梯度的影响,继续移动,防止卡在鞍点)

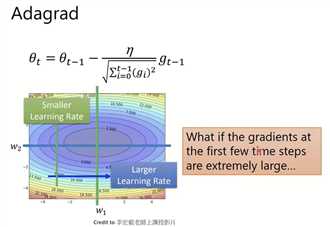
Adagrad(随着时间累计,分母可能会无止境变大,导致leanring rate*gradient接近0,也就相当于卡住。EMA问题)
RMSProp(通过增加一个系数alpha,解决EMA问题。但是梯度为0的情况还是可能进入鞍点。)
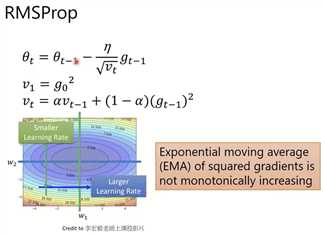
Adam(结合Momentum和RMSProp,既能避免EMA问题,又能避免梯度为0进入鞍点。)

Ada系列集中在2014年左右被提出的。

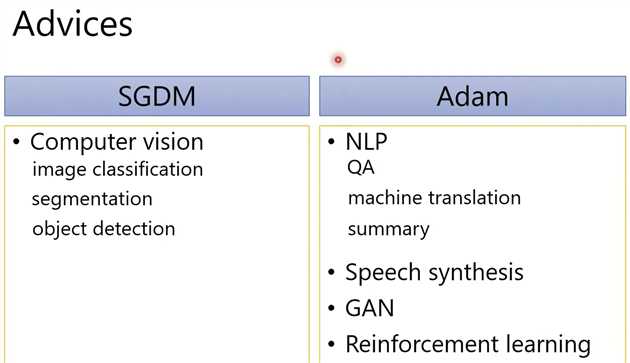
实际应用


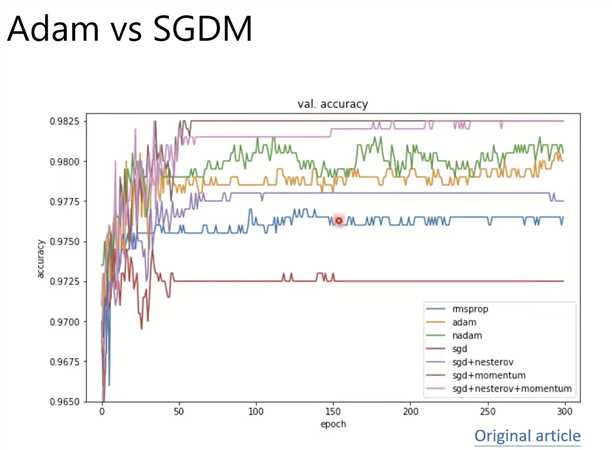
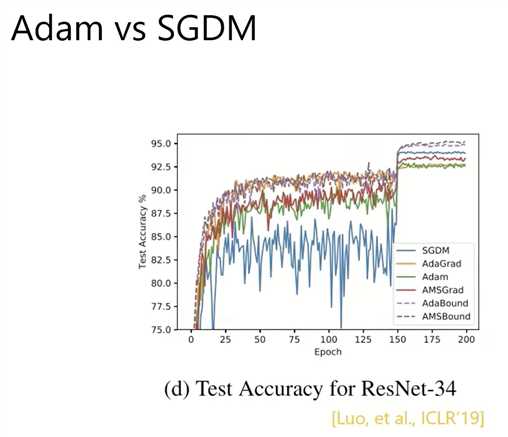
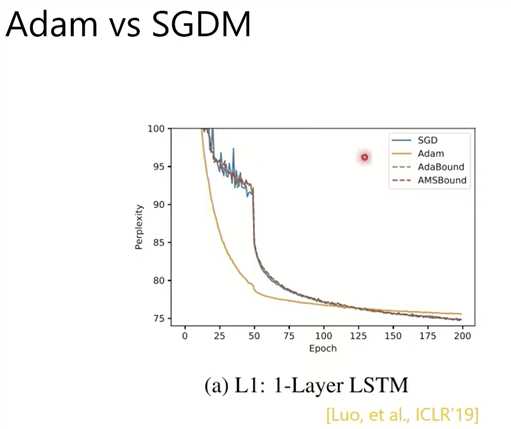
Adam 和 SGDM
训练acc
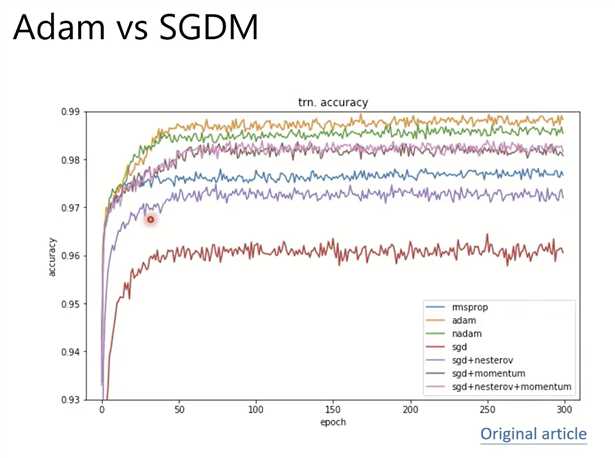
验证acc
一篇论文
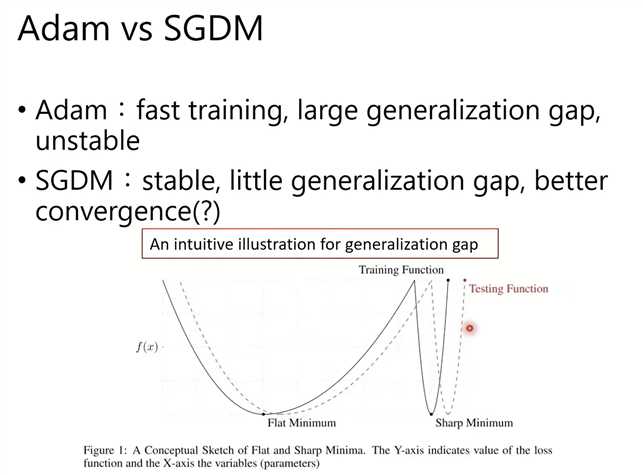
结论:Flat Minimum和Sharp Minimum
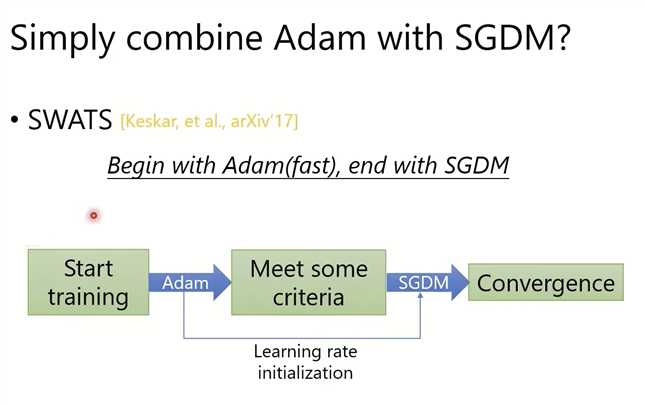
如何提高Adam?

经过1000步很小的gradients之后,遇到一个较大的gradient,但是受movement影响,只能移动很小的一步。也就是大量Non-informative梯度抑制了informative梯度。
从公式可以看出,一次更新的最大移动距离的上届就是(sqrt(1/(1-beta_2)))*eta

这篇文章提出记住历史最大的v_t,就可以避免non-informative gradients的影响了。

另一篇文章


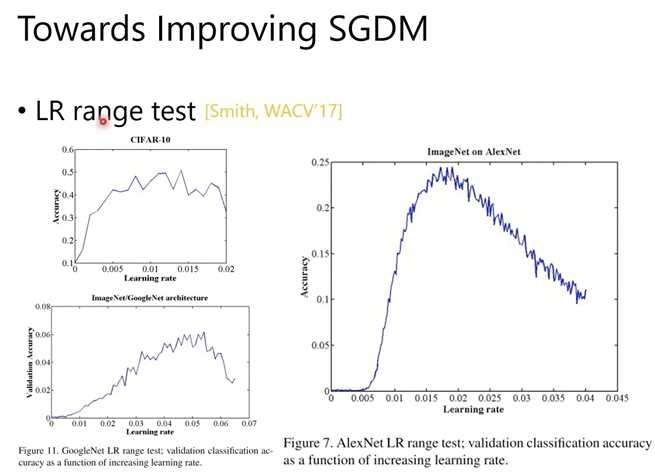
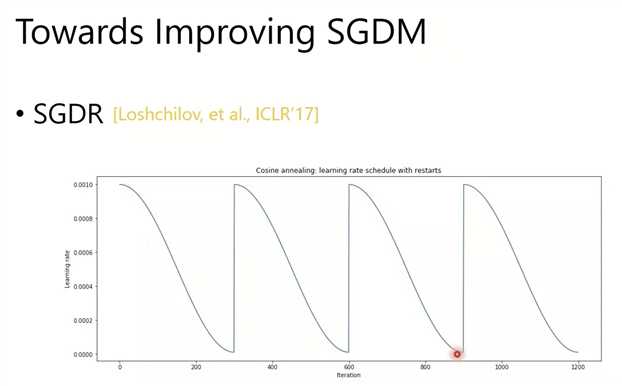
如何提高SGDM?

lr太大或太小,都不如适中的时候好。LR Range Test

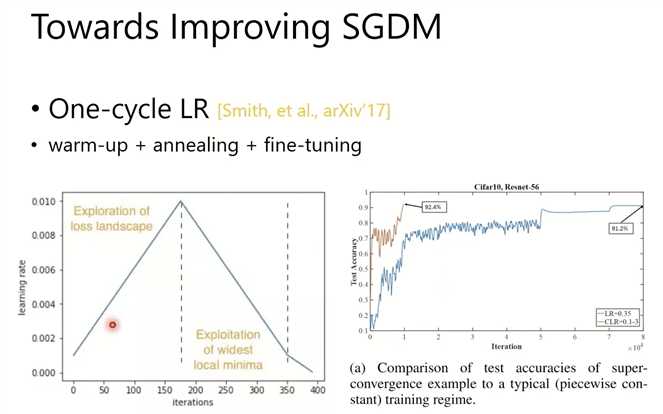
Adam需要warm up,否则前期的梯度会很乱。
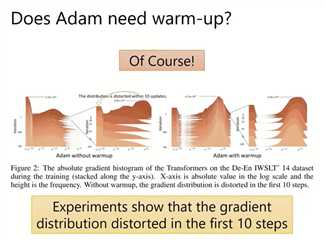
warmup,前期走小步一点。
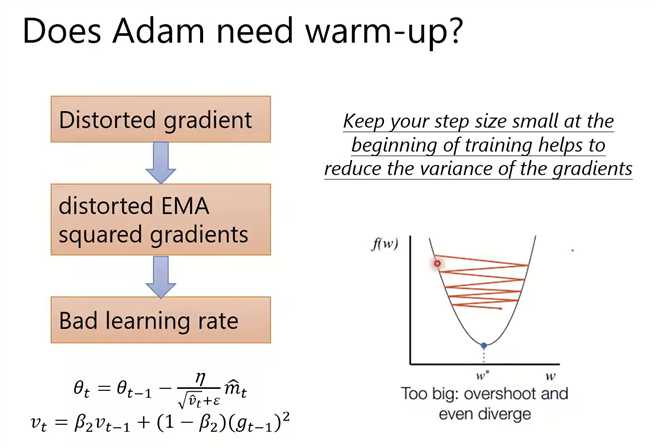
Variance大,则走小步;Variance小,则走大步。

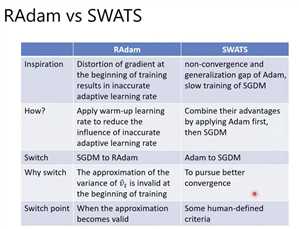
通用的方法

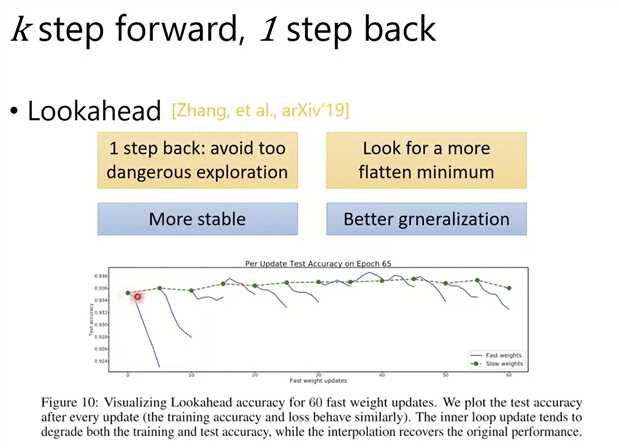
再看Momentum


Adam in the future:Nadam

L2 regularization or weight decay?【SGDWM或AdamW(实际应用比较多)】


更多探索,效果更好

耐心教导模型

【2020春】李宏毅机器学习(New Optimizers for Deep Learning)
原文:https://www.cnblogs.com/CheeseZH/p/13546274.html