决策树基本概念及优缺点
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。
决策树的主要优点:
决策树的主要缺点:
基于企鹅数据集的决策树实例
## 基础函数库 import numpy as np import pandas as pd ## 绘图函数库 import matplotlib.pyplot as plt import seaborn as sns
本次我们选择企鹅数据(palmerpenguins)进行方法的尝试训练,该数据集一共包含8个变量,其中7个特征变量,1个目标分类变量。共有150个样本,目标变量为 企鹅的类别 其都属于企鹅类的三个亚属,分别是(Adélie, Chinstrapand Gentoo)。包含的三种种企鹅的七个特征,分别是所在岛屿,嘴巴长度,嘴巴深度,脚蹼长度,身体体积,性别以及年龄。

## 我们利用Pandas自带的read_csv函数读取并转化为DataFrame格式 data = pd.read_csv(‘penguins_raw.csv‘) ## 为了方便我们仅选取四个简单的特征,有兴趣的同学可以研究下其他特征的含义以及使用方法 data = data[[‘Species‘,‘Culmen Length (mm)‘,‘Culmen Depth (mm)‘,‘Flipper Length (mm)‘,‘Body Mass (g)‘]]
## 利用.info()查看数据的整体信息 data.info()
<class ‘pandas.core.frame.DataFrame‘> RangeIndex: 344 entries, 0 to 343 Data columns (total 5 columns): Species 344 non-null object Culmen Length (mm) 342 non-null float64 Culmen Depth (mm) 342 non-null float64 Flipper Length (mm) 342 non-null float64 Body Mass (g) 342 non-null float64 dtypes: float64(4), object(1) memory usage: 13.6+ KB
## 进行简单的数据查看,我们可以利用 .head() 头部.tail()尾部 data.head()
这里我们发现数据集中存在NaN,一般的我们认为NaN在数据集中代表了缺失值,可能是数据采集或处理时产生的一种错误。这里我们采用-1将缺失值进行填补,还有其他例如“中位数填补、平均数填补”的缺失值处理方法有兴趣的同学也可以尝试。
data = data.fillna(-1) #用-1填充缺失值
data.tail()
## 其对应的类别标签为‘Adelie Penguin‘, ‘Gentoo penguin‘, ‘Chinstrap penguin‘三种不同企鹅的类别。 data[‘Species‘].unique()
array([‘Adelie Penguin (Pygoscelis adeliae)‘,
‘Gentoo penguin (Pygoscelis papua)‘,
‘Chinstrap penguin (Pygoscelis antarctica)‘], dtype=object)
## 利用value_counts函数查看每个类别数量 pd.Series(data[‘Species‘]).value_counts() Adelie Penguin (Pygoscelis adeliae) 152 Gentoo penguin (Pygoscelis papua) 124 Chinstrap penguin (Pygoscelis antarctica) 68 Name: Species, dtype: int64
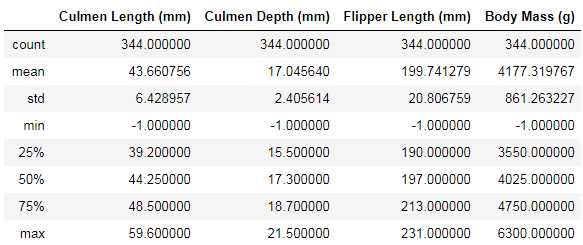
## 对于特征进行一些统计描述 data.describe()
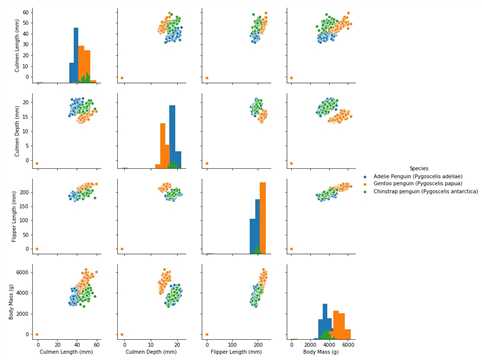
## 特征与标签组合的散点可视化 sns.pairplot(data=data, diag_kind=‘hist‘, hue= ‘Species‘) plt.show()
‘‘‘为了方便我们将标签转化为数字
‘Adelie Penguin (Pygoscelis adeliae)‘ ------0
‘Gentoo penguin (Pygoscelis papua)‘ ------1
‘Chinstrap penguin (Pygoscelis antarctica) ------2 ‘‘‘
def trans(x): if x == data[‘Species‘].unique()[0]: return 0 if x == data[‘Species‘].unique()[1]: return 1 if x == data[‘Species‘].unique()[2]: return 2 data[‘Species‘] = data[‘Species‘].apply(trans)
绘制各属性下不同种类企鹅的箱线图,利用箱型图我们也可以得到不同类别在不同特征上的分布差异情况。
for col in data.columns: if col != ‘Species‘: sns.boxplot(x=‘Species‘, y=col, saturation=0.5, palette=‘pastel‘, data=data) plt.title(col) plt.show()
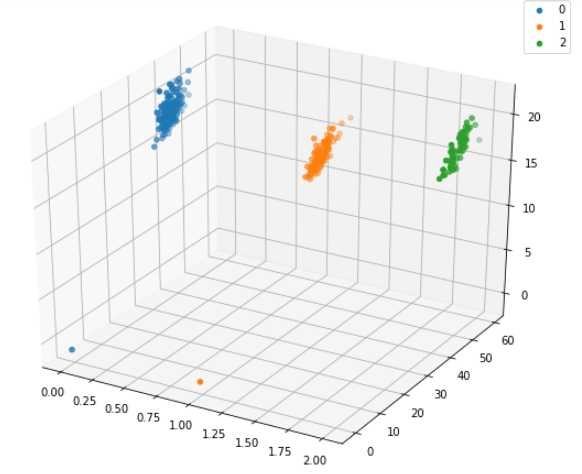
# 选取其前三个特征绘制三维散点图
from mpl_toolkits.mplot3d import Axes3D fig = plt.figure(figsize=(10,8)) ax = fig.add_subplot(111, projection=‘3d‘) data_class0 = data[data[‘Species‘]==0].values data_class1 = data[data[‘Species‘]==1].values data_class2 = data[data[‘Species‘]==2].values # ‘setosa‘(0), ‘versicolor‘(1), ‘virginica‘(2) ax.scatter(data_class0[:,0], data_class0[:,1], data_class0[:,2],label=data[‘Species‘].unique()[0]) ax.scatter(data_class1[:,0], data_class1[:,1], data_class1[:,2],label=data[‘Species‘].unique()[1]) ax.scatter(data_class2[:,0], data_class2[:,1], data_class2[:,2],label=data[‘Species‘].unique()[2]) plt.legend() plt.show()
## 为了正确评估模型性能,将数据划分为训练集和测试集,并在训练集上训练模型,在测试集上验证模型性能。 from sklearn.model_selection import train_test_split ## 选择其类别为0和1的样本 (不包括类别为2的样本) data_target_part = data[data[‘Species‘].isin([0,1])][[‘Species‘]] data_features_part = data[data[‘Species‘].isin([0,1])][[‘Culmen Length (mm)‘, ‘Culmen Depth (mm)‘, ‘Flipper Length (mm)‘, ‘Body Mass (g)‘]] ## 测试集大小为20%, 80%/20%分 x_train, x_test, y_train, y_test = train_test_split(data_features_part, data_target_part, test_size = 0.2, random_state = 2020)
## 从sklearn中导入决策树模型 from sklearn.tree import DecisionTreeClassifier from sklearn import tree ## 定义 逻辑回归模型 clf = DecisionTreeClassifier(criterion=‘entropy‘) # 在训练集上训练决策树模型 clf.fit(x_train, y_train) DecisionTreeClassifier(class_weight=None, criterion=‘entropy‘, max_depth=None, max_features=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=1, min_samples_split=2, min_weight_fraction_leaf=0.0, presort=False, random_state=None, splitter=‘best‘)
## 可视化 import graphviz dot_data = tree.export_graphviz(clf, out_file=None) graph = graphviz.Source(dot_data) graph.render("penguins"
原文:https://www.cnblogs.com/dusu/p/13549594.html