Spark比hadoop快的原因,我认为主要是spark的DAG机制优于hadoop太多,spark的DAG机制以及RDD的设计避免了很多落盘的操作,在窄依赖的情况下可以在内存中完成end to end的计算,相比于hadoop的map reduce编程模型来说,少了很多IO的开销。其次还有几个其他方面的助攻
上面说到spark比mr优越的一个原因也是shffle机制的不同。具体来说,spark的shffle机制从它诞生到现在一共有这么几种。
shuffle的意思就是打乱数据顺序使得相同的key被统一到同一个分区。
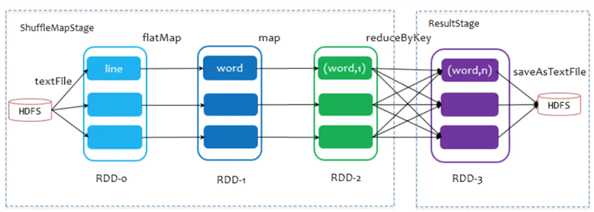
spark中只有2类stage:ShuffleMapStage和ResultStage。但其总的过程包含有map阶段(shuffle rade)和reduce阶段(shuffle write),两个阶段位于不同的stage中。
ResultStage基本上对应代码中的action算子, 而ShuffleMapStage 的则伴随着 shuffle IO。spark的mr和hadoop的mapreduce不是一个东西。map端task和reduce端task不在相同的stage中,map task位于ShuffleMapStage,reduce task位于ResultStage。map task会先执行,将上一个stage得到的最后结果写出,后执行的reduce task拉取上一个stage进行合并。
对于一次shuffle,map过程和reduce过程都有若干个task来执行。对于task的个数,map端的task个数和RDD的partition个数相同,reduce 端的 stage 默认取spark.default.parallelism 这个配置项的值作为分区数,如果没有配置,则以 map 端的最后一个 RDD 的分区数作为其分区数,分区数就将决定 reduce 端的 task 的个数。
在Spark的源码中,负责shuffle过程的执行、计算和处理的组件主要就是ShuffleManager。
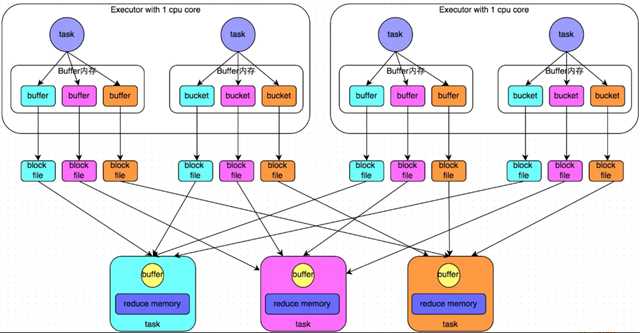
在Spark 1.2以前,默认的shuffle计算引擎是HashShuffleManager。它的计算模式比较的简单粗暴,详细如下:
stage的每一个task就需要将上一个stage的计算结果中的所有相同key,从各个节点上通过网络都拉取到自己所在的节点上,然后进行key的聚合或连接等操作。由于shuffle write的过程中,task给下游stage的每个task都创建了一个磁盘文件,因此shuffle read的过程中,每个task只要从上游stage的所有task所在节点上,拉取属于自己的那一个磁盘文件即可。
这个阶段将stage中每个task处理的数据根据算子进行“划分”。比如reduceByKey,就是对相同的key执行hash算法,从而将相同都写入同一个磁盘文件中,而每一个磁盘文件都只属于下游stage的一个task。在将数据写入磁盘之前,会先将数据写入内存缓冲中,当内存缓冲填满之后,才会溢写到磁盘文件中去。
那么针对这种简单粗暴的HashShuffleManager,有着一个非常严重的弊端:会产生大量的中间磁盘文件,这样大量的磁盘IO操作会很影响性能。磁盘文件的数量由下一个stage的task数量决定,即下一个stage的task有多少个,当前stage的每个task就要创建多少份磁盘文件。比如下一个 stage 总共有 100 个 task,那么当前 stage 的每个 task 都要创建 100 份磁盘文件,如果当前stage有50个 task,那么总共会建立5000个磁盘文件。
原文:https://www.cnblogs.com/zhouyc/p/13562858.html