MySQL的性能指标如下:
① TPS(Transaction Per Second) 每秒事务数,即数据库每秒执行的事务数。
MySQL 本身没有直接提供 TPS 参数值,如果我们想要获得 TPS 的值,只有我们自己计算了,可以根据 MySQL 数据库提供的状态变量,来计算 TPS。
需要使用的参数:
我们定义第一次获取的 Comcommit 的值与 Comrollback 值的和为 c_r1,时间为 t1;
第二次获取的 Comcommit 的值与 Comrollback 值的和为 cr2,时间为 t2,t1 与 t2 单位为秒。 那么 TPS = ( cr2 - c_r1 ) / ( t2 - t1 ) 算出来的就是该 MySQL 实例在 t1 与 t2 生命周期之间的平均 TPS。
② QPS(Query Per Second) 每秒请求次数,也就是数据库每秒执行的 SQL 数量,包含 INSERT、SELECT、UPDATE、DELETE 等。 QPS = Queries / Seconds Queries 是系统状态值—总查询次数,可以通过 show status like ‘queries‘; 查询得出,如下所示:
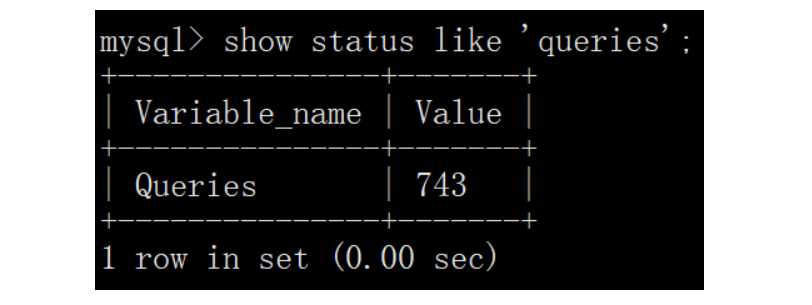
Seconds 是监控的时间区间,单位为秒。 比如,采样 10 秒内的查询次数,那么先查询一次 Queries 值(Q1),等待 10 秒,再查询一次 Queries 值(Q2),那么 QPS 就可以通过,如下公式获得:
QPS = (Q2 - Q1) / 10
③ IOPS(Input/Output Operations per Second) 每秒处理的 I/O 请求次数。
IOPS 是判断磁盘 I/O 能力的指标之一,一般来讲 IOPS 指标越高,那么单位时间内能够响应的请求自然也就越多。理论上讲,只要系统实际的请求数低于 IOPS 的能力,就相当于每一个请求都能得到即时响应,那么 I/O 就不会是瓶颈了。
注意:IOPS 与磁盘吞吐量不一样,吞吐量是指单位时间内可以成功传输的数据数量。
可以使用 iostat 命令,查看磁盘的 IOPS,命令如下:
yum install sysstat iostat -dx 1 10
执行效果如下图所示:
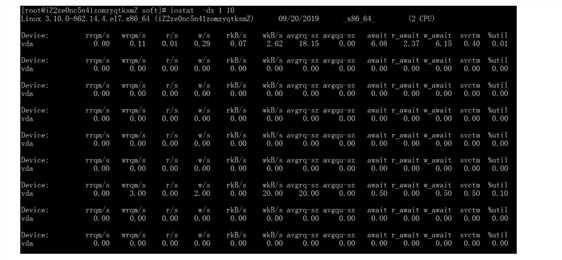
IOPS = r/s + w/s 其中:
慢查询是 MySQL 中提供的一种慢查询日志,它用来记录在 MySQL 中响应时间超过阀值的语句,具体指运行时间超过 longquerytime 值的 SQL,则会被记录到慢查询日志中。longquerytime 的默认值为 10,意思是运行 10S 以上的语句。默认情况下,MySQL 数据库并不启动慢查询日志,需要我们手动来设置这个参数,如果不是调优需要的话,一般不建议启动该参数,因为开启慢查询日志会给 MySQL 服务器带来一定的性能影响。慢查询日志支持将日志记录写入文件,也支持将日志记录写入数据库表。
使用 mysql> show variables like ‘%slow_query_log%‘; 来查询慢查询日志是否开启,执行效果如下图所示:
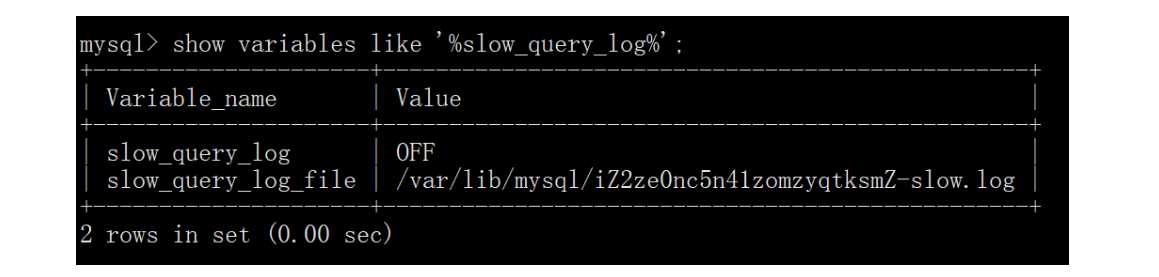
slowquerylog 的值为 OFF 时,表示未开启慢查询日志。
开启慢查询日志,可以使用如下 MySQL 命令:
mysql> set global slowquerylog=1
不过这种设置方式,只对当前数据库生效,如果 MySQL 重启也会失效,如果要永久生效,就必须修改 MySQL 的配置文件 my.cnf,配置如下:
slowquerylog =1 slowquerylogfile=/tmp/mysqlslow.log
使用 MySQL 中的 explain 分析执行语句,比如:
explain select * from t where id=5;
如下图所示:

其中:
其中最重要的就是 type 字段,type 值类型如下:
① 查询优化
② 优化索引的使用
③ 表结构设计优化
④ 表拆分
当数据库中的数据非常大时,查询优化方案也不能解决查询速度慢的问题时,我们可以考虑拆分表,让每张表的数据量变小,从而提高查询效率。 a)垂直拆分:是指数据表列的拆分,把一张列比较多的表拆分为多张表,比如,用户表中一些字段经常被访问,将这些字段放在一张表中,另外一些不常用的字段放在另一张表中,插入数据时,使用事务确保两张表的数据一致性。 垂直拆分的原则:
b)水平拆分:指数据表行的拆分,表的行数超过200万行时,就会变慢,这时可以把一张的表的数据拆成多张表来存放。
通常情况下,我们使用取模的方式来进行表的拆分,比如,一张有 400W 的用户表 users,为提高其查询效率我们把其分成 4 张表 users1,users2,users3,users4,然后通过用户 ID 取模的方法,同时查询、更新、删除也是通过取模的方法来操作。
⑤ 读写分离
一般情况下对数据库而言都是“读多写少”,换言之,数据库的压力多数是因为大量的读取数据的操作造成的,我们可以采用数据库集群的方案,使用一个库作为主库,负责写入数据;其他库为从库,负责读取数据。这样可以缓解对数据库的访问压力。
MySQL常见的读写分离方案,如下列表:
1)应用层解决方案 可以通过应用层对数据源做路由来实现读写分离,比如,使用 SpringMVC + MyBatis,可以将 SQL 路由交给 Spring,通过 AOP 或者 Annotation 由代码显示的控制数据源。 优点:路由策略的扩展性和可控性较强。 缺点:需要在 Spring 中添加耦合控制代码。
2)中间件解决方案 通过 MySQL 的中间件做主从集群,比如:Mysql Proxy、Amoeba、Atlas 等中间件都能符合需求。 优点:与应用层解耦。 缺点:增加一个服务维护的风险点,性能及稳定性待测试,需要支持代码强制主从和事务。
介绍一下 Sharding-JDBC 的功能和执行流程?
Sharding-JDBC 在客户端对数据库进行水平分区的常用解决方案,也就是保持表结构不变,根据策略存储数据分片,这样每一片数据被分散到不同的表或者库中,Sharding-JDBC 提供以下功能:
Sharding-JDBC 的执行流程:当业务代码调用数据库执行的时候,先触发 Sharding-JDBC 的分配规则对 SQL 语句进行解析、改写之后,才会对改写的 SQL 进行执行和结果归并,然后返回给调用层。
MySQL多实例就是在同一台服务器上启用多个 MySQL 服务,它们监听不同的端口,运行多个服务进程,它们相互独立,互不影响的对外提供服务,便于节约服务器资源与后期架构扩展。 多实例的配置方法有两种:
通常保证主备无延迟有以下三种方法:
原文:https://www.cnblogs.com/lianhaifeng/p/13567951.html