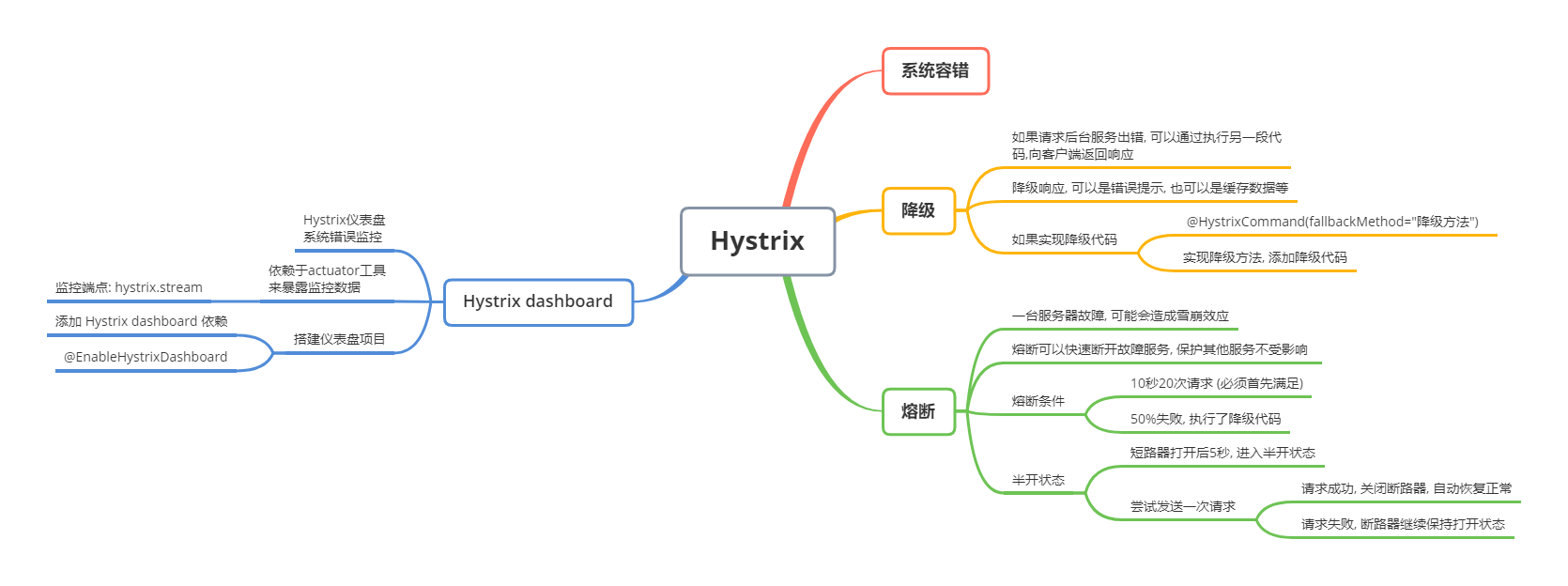
解决问题: 主要防止服务器集群发生雪崩, 起到对服务器的保护作用
github地址: https://github.com/Netflix/Hystrix/wiki
分布式系统环境下,服务间类似依赖非常常见,一个业务调用通常依赖多个基础服务。如下图,对于同步调用,当库存服务不可用时,商品服务请求线程被阻塞,当有大批量请求调用库存服务时,最终可能导致整个商品服务资源耗尽,无法继续对外提供服务。并且这种不可用可能沿请求调用链向上传递,这种现象被称为雪崩效应。
针对造成雪崩效应的不同场景,可以使用不同的应对策略,没有一种通用所有场景的策略,参考如下:
综上所述,如果一个应用不能对来自依赖的故障进行隔离,那该应用本身就处在被拖垮的风险中。 因此,为了构建稳定、可靠的分布式系统,我们的服务应当具有自我保护能力,当依赖服务不可用时,当前服务启动自我保护功能,从而避免发生雪崩效应。本文将重点介绍使用Hystrix解决同步等待的雪崩问题。
一个服务调用后台服务失败(出现异常、等待超时、不能连接),可以执行当前服务中的一段代码,向前返回响应(错误提示、缓存数据)
系统容错,当后台服务出现错误,还可以向客户端返回结果
10秒内20次请求,50%调用失败,执行了降级代码,会触发熔断
熔断可以避免故障的传播,避免引起雪崩效应
限流,后台服务压力过大出现故障,可以断开连接,限制访问流量
熔断的条件(两个条件必须都满足)
半开状态
? 断路器打开5秒后,会进入半开状态,
? 客户端请求时,会尝试发送一次调用,
? 如果成功,会自动关闭断路器,恢复正常
? 如果失败,就继续保持打开状态
和ribbon联用 [跳转ribbon]
在springboot中导入Hystrix [Maintenance] 依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
主要是把@EnableCircuitBreaker注解到主启动类
以下3个注解可以使用@SpringCloudApplication注解代替
@EnableCircuitBreaker // 开启Hystrix的注解, 启动断路器
//@EnableDiscoveryClient // 开启eureka的注解, 高版本可省略
@SpringBootApplication
public class Sp06RibbonApplication {
public static void main(String[] args) {
SpringApplication.run(Sp06RibbonApplication.class, args);
}
// ribbon配置, RestTemplate对象
@LoadBalanced
@Bean
public RestTemplate restTemplate() {
SimpleClientHttpRequestFactory f = new SimpleClientHttpRequestFactory();
f.setConnectTimeout(1000);
f.setReadTimeout(1000);
return new RestTemplate();
}
}
使用@HystrixCommand注解来实现降级, 实现步骤如下:
@HystrixCommand(fallbakMethod="降级方法名")注解, 放在正常执行的业务代码方法上, 这个业务员代码中调用了后端的服务器, 参数fallbakMethod为字符串类型, 指向降级的方法名如下代码
@RestController
@Slf4j
public class RibbonController {
// 注入RestTemplate对象 (ribbon)
@Autowired
private RestTemplate restTemplate;
// 处理请求业务, 调用后端服务器
@GetMapping("/item-service/{orderId}")
@HystrixCommand(fallbackMethod = "getItemsFB") // 使用降级注解
public JsonResult<List<Item>> getItems(@PathVariable String orderId) {
log.info("调用后台商品服务, 获取商品列表");
JsonResult r = restTemplate.getForObject(
"http://item-service/{1}",
JsonResult.class,
orderId);
return r;
}
// 降级后执行的方法
public JsonResult<List<Item>> getItemsFB(@PathVariable String orderId) {
return JsonResult.err().msg("获取商品失败");
}
}
即, 当我们的正常业务getItems方法调用后端服务器(出现异常、等待超时[超时时间默认为1秒]、不能连接)时, 执行getItemsFB方法
hystrix等待超时后, 会执行降级代码, 快速向客户端返回降级结果, 默认超时时间是1000毫秒
思考: 当调用后端服务器超时的时候(Hystrix默认超时时间为1秒), 服务器是否会进行重试或者更换服务器的操作(ribbon)??????
假如如下为ribbon的超时时间(1秒)
@LoadBalanced
@Bean
public RestTemplate restTemplate() {
SimpleClientHttpRequestFactory f = new SimpleClientHttpRequestFactory();
f.setConnectTimeout(1000);
f.setReadTimeout(1000);
return new RestTemplate();
}
以及重试和更换服务器的次数
ribbon:
MaxAutoRetriesNextServer: 2
MaxAutoRetries: 1
OkToRetryOnAllOperations: true
答案也是很明显的重试依然会执行, 也会执行降级方法的执行结果, 但是我们的重试和更换服务器的操作几乎没有意义了
那么我们如何解决这一问题呢?
我们可以设置Hystrix 超时时间, 即降级执行的时间, 此设置一般应大于 ribbon 的重试超时时长,例如 10 秒
hystrix:
command:
default:
execution:
isolation:
thread:
timeoutInMilliseconds: 10000
如果调用后端服务超时, hystrix 才会立即执行降级方法
如果调用的后端服务未启动, hystrix也会立即执行降级方法
hystrix 对请求的降级和熔断,可以产生监控信息,hystrix dashboard可以实时的进行监控
仪表盘一般都是独立运行的
断路仪表盘依赖springboot的actuator工具 关于actuator功能 [actuator监控]
在被监控的项目中(Hystrix项目)添加actuator依赖, 并配置了配置文件
依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
yml配置文件
management:
endpoints:
web:
exposure:
include: "*" # 一定要加引号
被监控项目启动后访问: http://localhost:3001/actuator (ip和端口写自己的) 查看效果
如果一直显示ping:, 可发送一次请求, 出现一大坨信息就是配置成功了
我们重新新建一个项目, 用来监控
导入Hystrix Dashboard依赖 :
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix-dashboard</artifactId>
</dependency>
配置文件只需要进行简单的配置即可
spring:
application:
name: hystrix-dashboard # 服务名
server:
port: 4001 # 端口号
在主启动类上添加一个注解@EnableHystrixDashboard
@EnableHystrixDashboard
@SpringBootApplication
public class Sp08HystrixDashboardApplication {
public static void main(String[] args) {
SpringApplication.run(Sp08HystrixDashboardApplication.class, args);
}
}
http://localhost:4001/hystrix ip/域名和端口写自己的即可
可以看到如下页面:
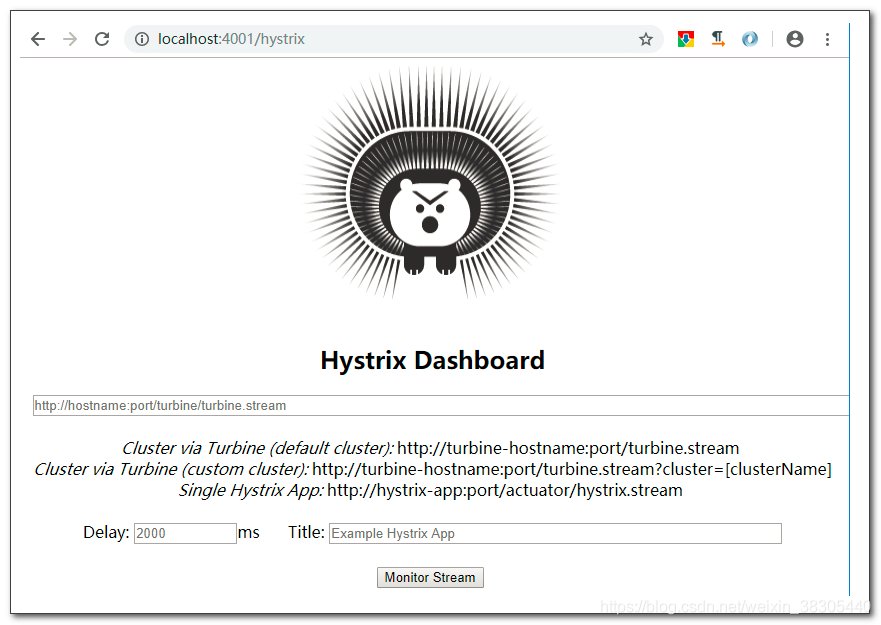
然后输入我们的被监控的Hystrix服务的网址, 点击Monitor Stream即可
我的是http://localhost:3001/actuator, 我就填入这个
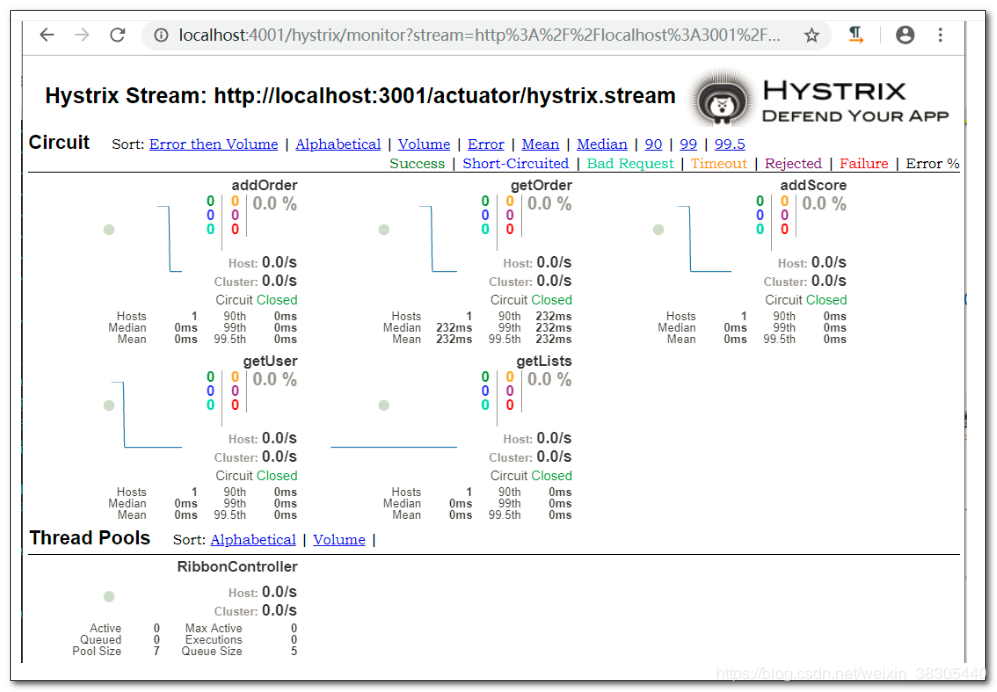
关于仪表盘的信息如何查看:
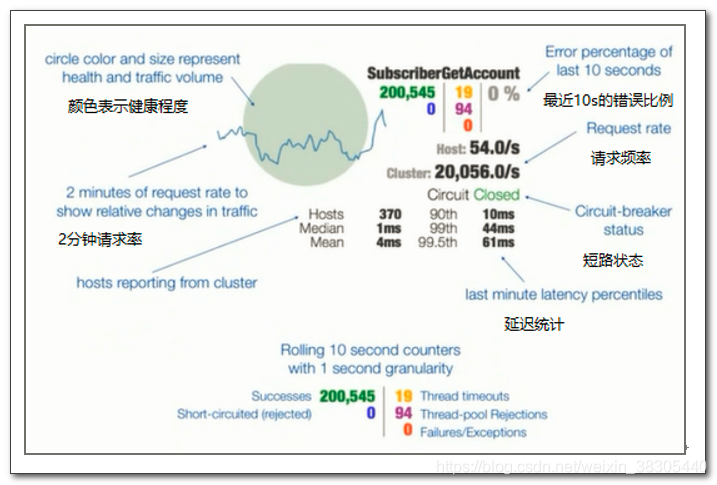
整个链路达到一定的阈值,默认情况下,10秒内产生超过20次请求,则符合第一个条件。
满足第一个条件的情况下,如果请求的错误百分比大于阈值,则会打开断路器,默认为50%。
Hystrix的逻辑,先判断是否满足第一个条件,再判断第二个条件,如果两个条件都满足,则会开启断路器
断路器打开 5 秒后,会处于半开状态,会尝试转发请求,如果仍然失败,保持打开状态,如果成功,则关闭断路器
使用 apache 的并发访问测试工具 ab
http://httpd.apache.org/docs/current/platform/windows.html#down
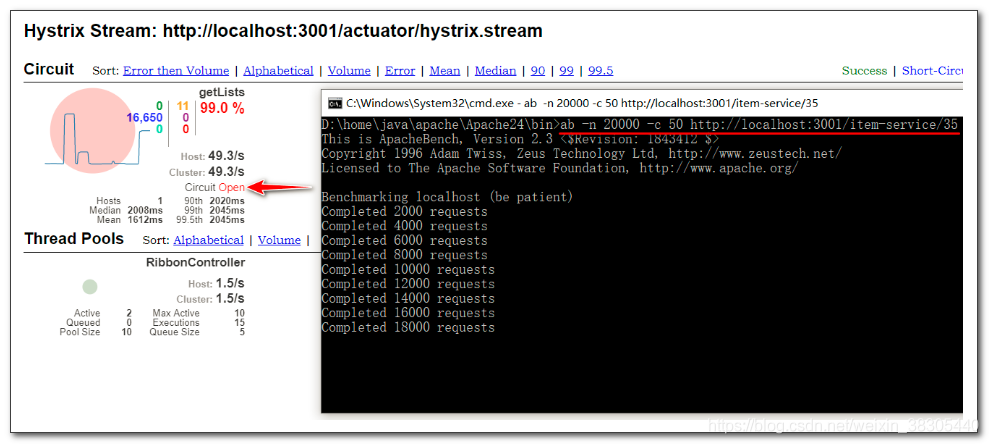
用 ab 工具,以并发50次,来发送20000个请求
ab -n 20000 -c 50 http://localhost:3001/item-service/35
断路器状态为 Open,所有请求会被短路,直接降级执行 fallback 方法
https://github.com/Netflix/Hystrix/wiki/Configuration
hystrix.command.default.execution.isolation.thread.timeoutInMillisecondshystrix.command.default.circuitBreaker.requestVolumeThresholdhystrix.command.default.circuitBreaker.errorThresholdPercentagehystrix.command.default.circuitBreaker.sleepWindowInMilliseconds原文:https://www.cnblogs.com/zpKang/p/13579762.html