索引:关系型数据库中给数据库表中一列或多列的值排序后的存储结构。
|
索引 |
MyISAM引擎 |
InnoDB引擎 |
Memory引擎 |
|
B-Tree |
支持 |
支持 |
支持 |
|
Hash |
不支持 |
不支持 |
支持 |
|
R-Tree |
支持 |
不支持 |
不支持 |
|
Full-text |
支持 |
现支持 |
不支持 |
备注:每个表只能有一个聚集索引,因为一个表中的记录只能以一种物理顺序存放;但是,一个表可以有不止一个非聚集索引。
也叫聚簇索引。该索引中键值的逻辑顺序决定了表中相应行的物理顺序
数据行的物理顺序和列值(一般是主键的那一列)的逻辑顺序相同,一个表中只能有一个聚集索引,聚集索引就显得弥足珍贵,聚集索引选择还是要慎重的(一般不会让没有语义的自增 id 充当聚集索引)
聚集索引确定表中数据的物理顺序。聚集索引类似电话簿,后者按照姓氏排列数据。由于聚集索引规定数据在表中的物理存储顺序,因此一个表只能有一个聚集索引;但该索引可以包含多个列(组合索引),就像电话簿按姓氏和名字进行组织一样。
该索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同,一个表中可以哟弄个有多个普通索引
所以PK查询非常快,直接定位行记录
注意:不是存储行记录头指针,MyISAM的索引叶子节点存储记录指针
Demo:
假设:有table表
table( id PK, name KEY, sex, flag);
id : 聚集索引,name : 非聚集索引
表中有四条记录:
|
id |
name |
sex |
flag |
|
1 |
shenjian |
m |
A |
|
3 |
zhangsan |
m |
A |
|
5 |
lisi |
m |
A |
|
9 |
wangwu |
f |
B |
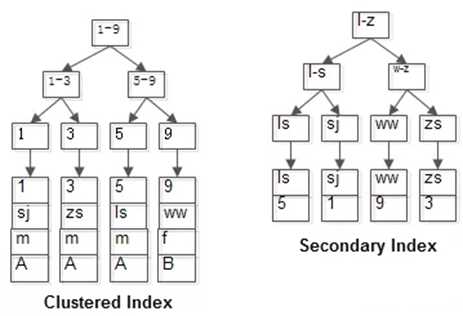
两个B+树索引分别如上图:
从普通索引无法直接定位行记录,那普通索引的查询过程
是怎么样的呢?
通常情况下,需要扫描两遍索引树
例:select * from table where name = ‘lisi‘;
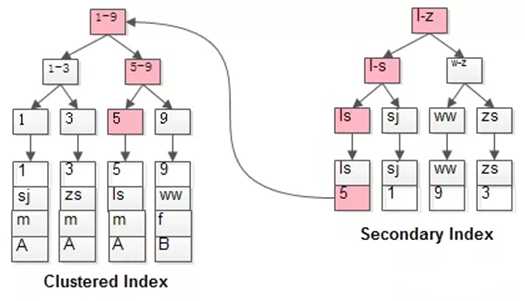
如粉色路径所示,需要扫描两遍所引述:
这就是所谓的回表查询,先定位主键值,再定位行记录;性能较扫一遍索引树更低。
查询的数据列只用从索引中就能够取得,不必读取数据行,换句话说查询列要被所建的索引覆盖。

MySQL官网,类似的说法出现在explain/desc查询计划优化章节,即explain/desc的输出结果Extra字段为Using index时,能够触发索引覆盖。

不管是SQL-Server官网,还是MySQL官网,都表达了:只需要在一颗索引树上就能获取SQL所需的所有列数据,无需回表,速度更快。
如何实现索引覆盖?
常见的方法:将被查询的字段,建立到联合索引中

1、能够命中 name 索引,索引叶子节点存储了主键 id,通过 name 的索引树即可获取 id 和 name,无需回表,符合索引覆盖,效率较高。

2、显示使用 name 索引,索引叶子节点存储了主键 id,但是 sex 字段必须回表查询才能获取到,不符合索引覆盖,需要再次通过 id 值扫描聚集索引获取 sex 字段值,效率会降低。


3、如果把 (name) 单列索引升级为联合索引 (name, sex)就不同了,可以看到都能命中索引,无需回表。
|
动作描述 |
使用聚集索引 |
使用非聚集索引 |
|
列经常被分组排序 |
使用 |
使用 |
|
返回某范围内的数据 |
使用 |
不使用 |
|
一个或极少不同值 |
不使用 |
不使用 |
|
小数目的不同值 |
使用 |
不使用 |
|
大数目的不同值 |
不使用 |
使用 |
|
频繁更新的列 |
不使用 |
使用 |
|
外键列 |
使用 |
使用 |
|
主键列 |
使用 |
使用 |
|
频繁修改索引列 |
不使用 |
使用 |
原文:https://www.cnblogs.com/sebastian-tyd/p/13580127.html