Redis 命令参考 http://redisdoc.com/#
| DEL key | 该命令用于在 key 存在时删除 key。 |
| DUMP key | 序列化给定 key ,并返回被序列化的值。 |
| EXISTS key | 检查给定 key 是否存在。 |
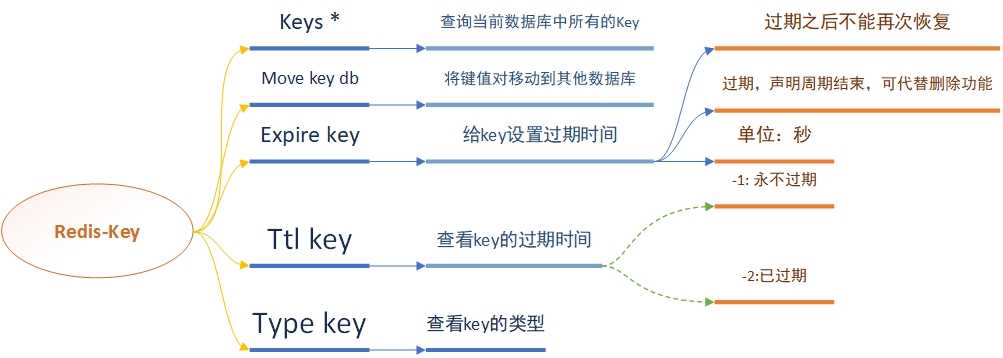
| EXPIRE key seconds | 为给定 key 设置过期时间,以秒计。 |
| EXPIREAT key timestamp | EXPIREAT 的作用和 EXPIRE 类似,都用于为 key 设置过期时间。 不同在于 EXPIREAT 命令接受的时间参数是 UNIX 时间戳(unix timestamp)。 |
| PEXPIRE key milliseconds | 设置 key 的过期时间以毫秒计。 |
| PEXPIREAT key milliseconds-timestamp | 设置 key 过期时间的时间戳(unix timestamp) 以毫秒计 |
| KEYS pattern | 查找所有符合给定模式( pattern)的 key 。 |
| MOVE key db | 将当前数据库的 key 移动到给定的数据库 db 当中。 |
| PERSIST key | 移除 key 的过期时间,key 将持久保持。 |
| PTTL key | 以毫秒为单位返回 key 的剩余的过期时间。 |
| TTL key | 以秒为单位,返回给定 key 的剩余生存时间(TTL, time to live)。 |
| RANDOMKEY | 从当前数据库中随机返回一个 key 。 |
| RENAME key newkey | 修改 key 的名称 |
| RENAMENX key newkey | 仅当 newkey 不存在时,将 key 改名为 newkey 。 |
| TYPE key | 返回 key 所储存的值的类型 |
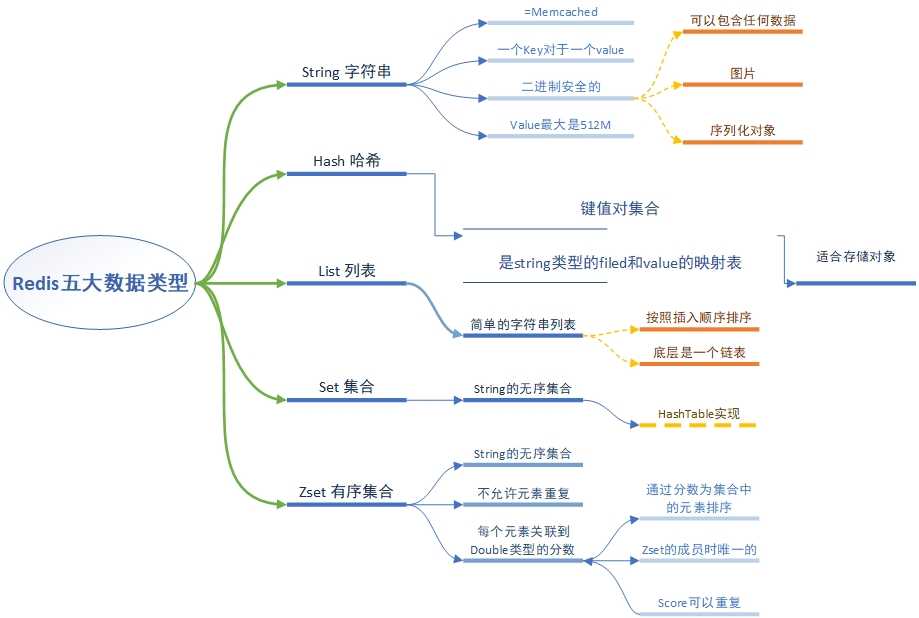
是redis的最基本的类型,一个key对应一个Value
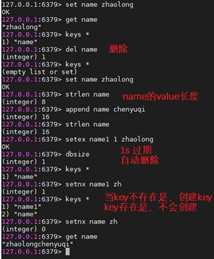
| SET key value | 设置指定 key 的值 |
| GET key | 获取指定 key 的值 |
| GETRANGE key start end | 返回 key 中字符串值的子字符 |
| GETSET key value | 将给定 key 的值设为 value ,并返回 key 的旧值(old value) |
| GETBIT key offset | 对 key 所储存的字符串值,获取指定偏移量上的位(bit) |
| MGET key1 [key2..] | 获取所有(一个或多个)给定 key 的值 |
| SETBIT key offset value | 对 key 所储存的字符串值,设置或清除指定偏移量上的位(bit) |
| SETEX key seconds value | 将值 value 关联到 key ,并将 key 的过期时间设为 seconds (以秒为单位) |
| SETNX key value | 只有在 key 不存在时设置 key 的值 |
| SETRANGE key offset value | 用 value 参数覆写给定 key 所储存的字符串值,从偏移量 offset 开始 |
| STRLEN key | 返回 key 所储存的字符串值的长度 |
| MSET key value [key value …] | 同时设置一个或多个 key-value 对 |
| MSETNX key value [key value …] | 同时设置一个或多个 key-value 对,当且仅当所有给定 key 都不存在 |
| PSETEX key milliseconds value | 这个命令和 SETEX 命令相似,但它以毫秒为单位设置 key 的生存时间,而不是像 SETEX 命令那样,以秒为单位 |
| INCR key | 将 key 中储存的数字值增一 |
| INCRBY key increment | 将 key 所储存的值加上给定的增量值(increment) |
| INCRBYFLOAT key increment | 将 key 所储存的值加上给定的浮点增量值(increment) |
| DECR key | 将 key 中储存的数字值减一 |
| DECRBY key decrement | key 所储存的值减去给定的减量值(decrement) |
| APPEND key value | 如果 key 已经存在并且是一个字符串, APPEND 命令将指定的 value 追加到该 key 原来值(value)的末尾 |
key-value模式不变,但是 value值是一个key-value,键值对的集合
是 string类型的 Field 和Value 的映射表, Redis 中每个 hash 可以存储 232 - 1 键值对(40多亿)
| Hset | 创建Hash hset key value(key value) |
| hget | 获取字段的值 key中的field的值 |
| hmset | 创建多个value值 |
| Gmset | 获取多个value值 |
| hgetall | 获取全部的value |
| hdel | 删除hash中的字段value |
| hlen | 获取长度 |
| hexists | 在key中里面的field是否存在 |
| Hkeys | 获取key值 |
| Hvals | 获取value值 |
| hincrby | 按照某个值增长 |
| hincrbyfloat | 按照浮点数 |
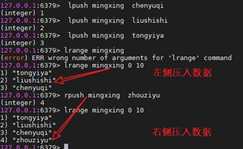
类似list,但是不允许重复
| Sadd | 创建或者添加元组到集合中 |
| Sismember | 查询元素是否存在于集合中 |
| Smembers | 显示所有的元素 |
| Scard | 获取集合中有多少个元素 |
| Srem key value | 删除集合中元素 |
| Srandmember key | 某个整数,从key中随机出几个数 |
| Spop key count | 随机出栈 |
| Smove key1 key2 value | 将key1中的某个值赋值给key2 |
| 集合操作 | |
| Sdiff | 差集:在第一个集合中,但是不再第二个集合 |
| Sinter | 交集 |
| Sunion | 并集 |
| SINTERSTORE destination key1 [key2] | 返回给定所有集合的交集并存储在 destination 中 |
有序集合 sorted set
| ZADD key score1 member1 [score2 member2] | 向有序集合添加一个或多个成员,或者更新已存在成员的分数 |
| ZCARD key | 获取有序集合的成员数 |
| ZCOUNT key min max | 计算在有序集合中指定区间分数的成员数 |
| ZINCRBY key increment member | 有序集合中对指定成员的分数加上增量 increment |
| ZINTERSTORE destination numkeys key [key …] | 计算给定的一个或多个有序集的交集并将结果集存储在新的有序集合 key 中 |
| ZLEXCOUNT key min max | 在有序集合中计算指定字典区间内成员数量 |
| ZRANGE key start stop [WITHSCORES] | 通过索引区间返回有序集合指定区间内的成员 |
| ZRANGEBYLEX key min max [LIMIT offset count] | 通过字典区间返回有序集合的成员 |
| ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT] | 通过分数返回有序集合指定区间内的成员 |
| ZRANK key member | 返回有序集合中指定成员的索引 |
| ZREM key member [member …] | 移除有序集合中的一个或多个成员 |
| ZREMRANGEBYLEX key min max | 移除有序集合中给定的字典区间的所有成员 |
| ZREMRANGEBYRANK key start stop | 移除有序集合中给定的排名区间的所有成员 |
| ZREMRANGEBYSCORE key min max | 移除有序集合中给定的分数区间的所有成员 |
| ZREVRANGE key start stop [WITHSCORES] | 返回有序集中指定区间内的成员,通过索引,分数从高到低 |
| ZREVRANGEBYSCORE key max min [WITHSCORES] | 返回有序集中指定分数区间内的成员,分数从高到低排序 |
| ZREVRANK key member | 返回有序集合中指定成员的排名,有序集成员按分数值递减(从大到小)排序 |
| ZSCORE key member | 返回有序集中,成员的分数值 |
| ZUNIONSTORE destination numkeys key [key …] | 计算给定的一个或多个有序集的并集,并存储在新的 key 中 |
| ZSCAN key cursor [MATCH pattern] [COUNT count] | 迭代有序集合中的元素(包括元素成员和元素分值) |
Redis HyperLogLog 是用来做基数统计的算法
HyperLogLog 的优点:在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2……^64 个不同元素的基数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素
基数------(不重复元素)
原文:https://www.cnblogs.com/ZhaoLong-study/p/13582543.html