R-CNN的全称是Region-CNN,是第一个成功将深度学习应用到目标检测上的算法。R-CNN基于卷积神经网络(CNN),线性回归,和支持向量机(SVM)等算法,实现目标检测技术。
对于一张图片,R-CNN基于selective search方法大约生成2000个候选区域,然后每个候选区域被resize成固定大小,并送入一个CNN模型中,最后得到一个特征向量。然后这个特征向量被送入一个多类别SVM分类器中,预测出候选区域中所含物体的属于每个类的概率值。每个类别训练一个SVM分类器,从特征向量中推断其属于该类别的概率大小。为了提升定位准确性,R-CNN最后又训练了一个边界框回归模型,通过边框回归模型对框的准确位置进行修正。
能够生成候选区域的方法很多,比如:
R-CNN 采用的是 Selective Search 算法。
? selective search的策略是,既然是不知道尺度是怎样的,那我们就尽可能遍历所有的尺度好了,但是不同于暴力穷举,我们可以先得到小尺度的区域,然后一次次合并得到大的尺寸就好了,这样也符合人类的视觉认知。既然特征很多,那就把我们知道的特征都用上,但是同时也要照顾下计算复杂度,不然和穷举法也没啥区别了。最后还要做的是能够对每个区域进行排序,这样你想要多少个候选我就产生多少个
R-CNN 抽取了一个 4096 维的特征向量,采用的是 Alexnet,基于 Caffe 进行代码开发。
需要注意的是 Alextnet 的输入图像大小是 227x227。
而通过 Selective Search 产生的候选区域大小不一,为了与 Alexnet 兼容,R-CNN 采用了非常暴力的手段,那就是无视候选区域的大小和形状,统一变换到 227*227 的尺寸。
有一个细节,在对 Region 进行变换的时候,首先对这些区域进行膨胀处理,在其 box 周围附加了 p 个像素,也就是人为添加了边框,在这里 p=16。
https://blog.csdn.net/briblue/article/details/103149407
YOLOv1 的论文地址:https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Redmon_You_Only_Look_CVPR_2016_paper.pdf
YOLO将输入图像分成SxS个格子,若某个物体 Ground truth 的中心位置的坐标落入到某个格子,那么这个格子就负责检测出这个物体。
每个格子预测B个bounding box及其置信度(confidence score),以及C个类别概率。bbox信息(x,y,w,h)为物体的中心位置相对格子位置的偏移及宽度和高度,均被归一化.置信度反映是否包含物体以及包含物体情况下位置的准确性,定义为????(????????????)×???????????????????????,其中????(????????????)∈{0,1}Pr(Object)×IOUpredtruth,其中Pr(Object)∈{0,1}.
输入尺寸固定:由于输出层为全连接层,因此在检测时,YOLO训练模型只支持与训练图像相同的输入分辨率。其它分辨率需要缩放成改分辨率.
占比较小的目标检测效果不好.虽然每个格子可以预测B个bounding box,但是最终只选择只选择IOU最高的bounding box作为物体检测输出,即每个格子最多只预测出一个物体。当物体占画面比例较小,如图像中包含畜群或鸟群时,每个格子包含多个物体,但却只能检测出其中一个。
YOLOv2提出了一种新的分类模型Darknet-19.借鉴了很多其它网络的设计概念.主要使用3x3卷积并在pooling之后channel数加倍(VGG);global average pooling替代全连接做预测分类,并在3x3卷积之间使用1x1卷积压缩特征表示(Network in Network);使用 batch normalization 来提高稳定性,加速收敛,对模型正则化.
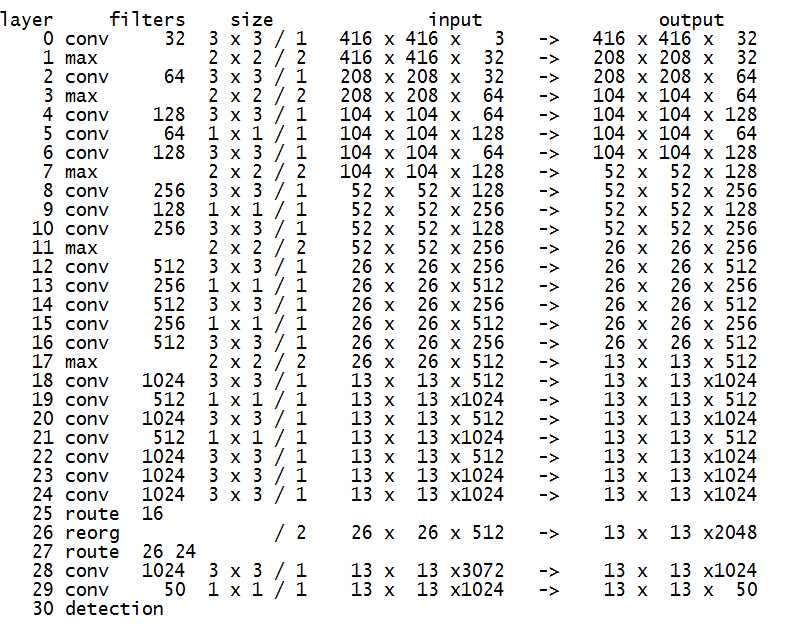
网络结构如下(输入416,5个类别,5个anchor box; 此结构信息由Darknet框架启动时输出):
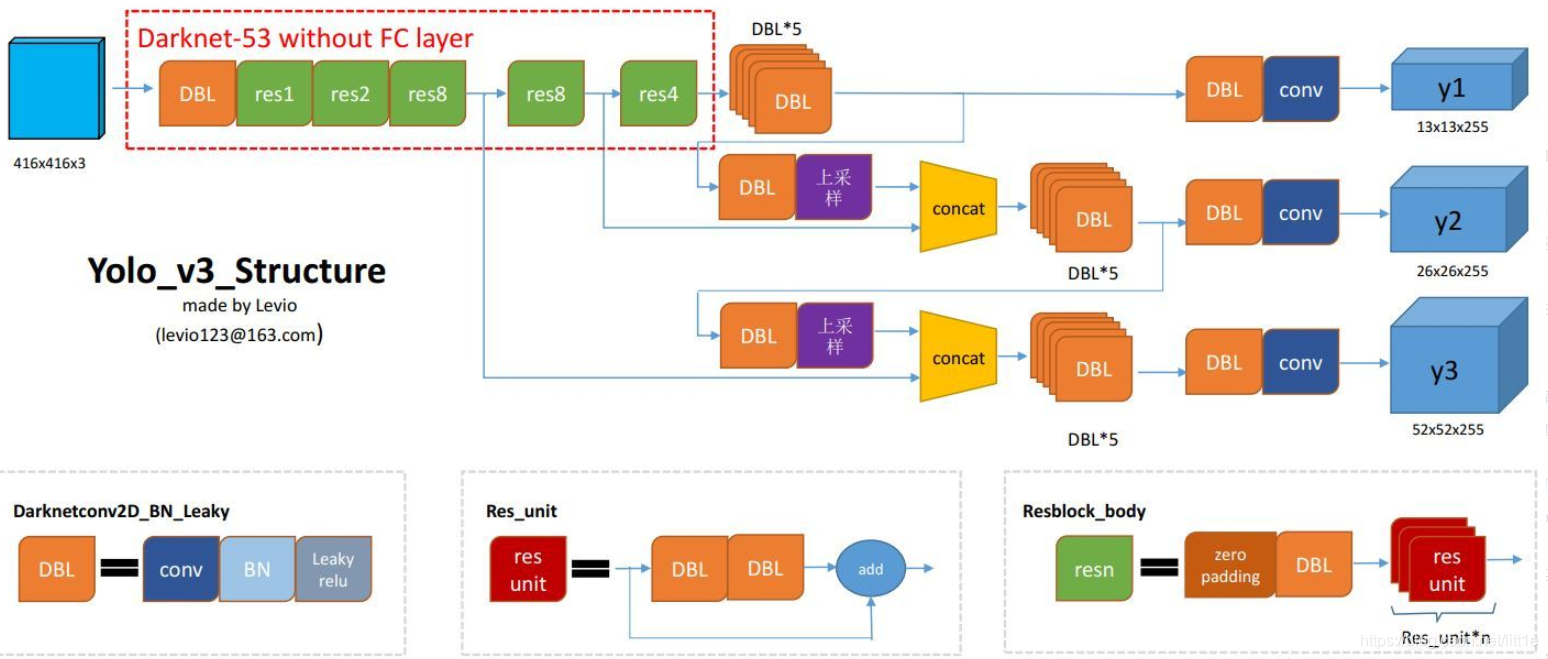
DBL:代码中的Darknetconv2d_BN_Leaky,是yolo_v3的基本组件。就是卷积+BN+Leaky relu。
resn:n代表数字,有res1,res2, … ,res8等等,表示这个res_block里含有多少个res_unit。
concat:张量拼接。将darknet中间层和后面的某一层的上采样进行拼接。拼接的操作和残差层add的操作是不一样的,拼接会扩充张量的维度,而add只是直接相加不会导致张量维度的改变。
为了达到更好的分类效果,作者自己设计训练了darknet-53。作者在ImageNet上实验发现这个darknet-53,的确很强,相对于ResNet-152和ResNet-101,darknet-53不仅在分类精度上差不多,计算速度还比ResNet-152和ResNet-101强多了,网络层数也比他们少。
Yolo_v3使用了darknet-53的前面的52层(没有全连接层),yolo_v3这个网络是一个全卷积网络,大量使用残差的跳层连接,并且为了降低池化带来的梯度负面效果,作者直接摒弃了POOLing,用conv的stride来实现降采样。在这个网络结构中,使用的是步长为2的卷积来进行降采样。
为了加强算法对小目标检测的精确度,YOLO v3中采用类似FPN的upsample和融合做法(最后融合了3个scale,其他两个scale的大小分别是26×26和52×52),在多个scale的feature map上做检测。
作者在3条预测支路采用的也是全卷积的结构,其中最后一个卷积层的卷积核个数是255,是针对COCO数据集的80类:3*(80+4+1)=255,3表示一个grid cell包含3个bounding box,4表示框的4个坐标信息,1表示objectness score。
所谓的多尺度就是来自这3条预测之路,y1,y2和y3的深度都是255,边长的规律是13:26:52。yolo v3设定的是每个网格单元预测3个box,所以每个box需要有(x, y, w, h, confidence)五个基本参数,然后还要有80个类别的概率。所以3×(5 + 80) = 255。这个255就是这么来的。
下面我们具体看看y1,y2,y3是如何而来的。
网络中作者进行了三次检测,分别是在32倍降采样,16倍降采样,8倍降采样时进行检测,这样在多尺度的feature map上检测跟SSD有点像。在网络中使用up-sample(上采样)的原因:网络越深的特征表达效果越好,比如在进行16倍降采样检测,如果直接使用第四次下采样的特征来检测,这样就使用了浅层特征,这样效果一般并不好。如果想使用32倍降采样后的特征,但深层特征的大小太小,因此yolo_v3使用了步长为2的up-sample(上采样),把32倍降采样得到的feature map的大小提升一倍,也就成了16倍降采样后的维度。同理8倍采样也是对16倍降采样的特征进行步长为2的上采样,这样就可以使用深层特征进行detection。
作者通过上采样将深层特征提取,其维度是与将要融合的特征层维度相同的(channel不同)。如下图所示,85层将13×13×256的特征上采样得到26×26×256,再将其与61层的特征拼接起来得到26×26×768。为了得到channel255,还需要进行一系列的3×3,1×1卷积操作,这样既可以提高非线性程度增加泛化性能提高网络精度,又能减少参数提高实时性。52×52×255的特征也是类似的过程。
OLO v3的Bounding Box由YOLOV2又做出了更好的改进。在yolo_v2和yolo_v3中,都采用了对图像中的object采用k-means聚类。 feature map中的每一个cell都会预测3个边界框(bounding box) ,每个bounding box都会预测三个东西:(1)每个框的位置(4个值,中心坐标tx和ty,,框的高度bh和宽度bw),(2)一个objectness prediction ,(3)N个类别,coco数据集80类,voc20类。
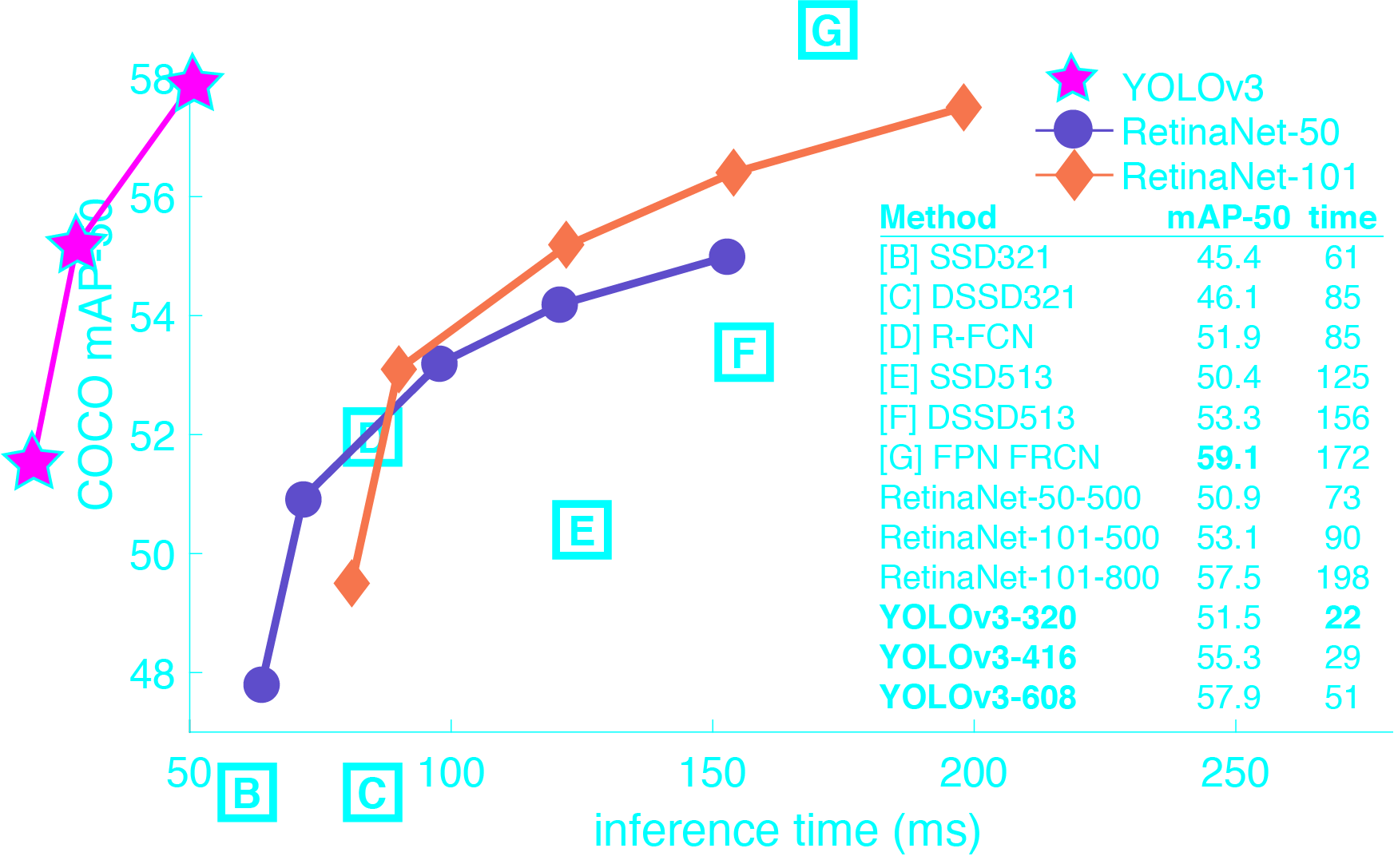
三次检测,每次对应的感受野不同,32倍降采样的感受野最大,适合检测大的目标,所以在输入为416×416时,每个cell的三个anchor box为(116 ,90); (156 ,198); (373 ,326)。16倍适合一般大小的物体,anchor box为(30,61); (62,45); (59,119)。8倍的感受野最小,适合检测小目标,因此anchor box为(10,13); (16,30); (33,23)。所以当输入为416×416时,实际总共有(52×52+26×26+13×13)×3=10647个proposal box。
YOLOv3重要改变之一:No more softmaxing the classes。
YOLO v3现在对图像中检测到的对象执行多标签分类。
logistic回归用于对anchor包围的部分进行一个目标性评分(objectness score),即这块位置是目标的可能性有多大。这一步是在predict之前进行的,可以去掉不必要anchor,可以减少计算量。
如果模板框不是最佳的即使它超过我们设定的阈值,我们还是不会对它进行predict。
不同于faster R-CNN的是,yolo_v3只会对1个prior进行操作,也就是那个最佳prior。而logistic回归就是用来从9个anchor priors中找到objectness score(目标存在可能性得分)最高的那一个。logistic回归就是用曲线对prior相对于 objectness score映射关系的线性建模。
原文:https://www.cnblogs.com/y6ming/p/13583422.html
